1/n: O que a maioria não percebe é que a equipe da DeepSeek desvendou o tão temido e almejado ciclo de autoaperfeiçoamento para o domínio mais complexo dos LLMs: a geração de provas para problemas difíceis. Vai ser interessante ver onde o ciclo se interrompe. Alguém acorde Eliezer Yudkowsky! @teortaxesTex
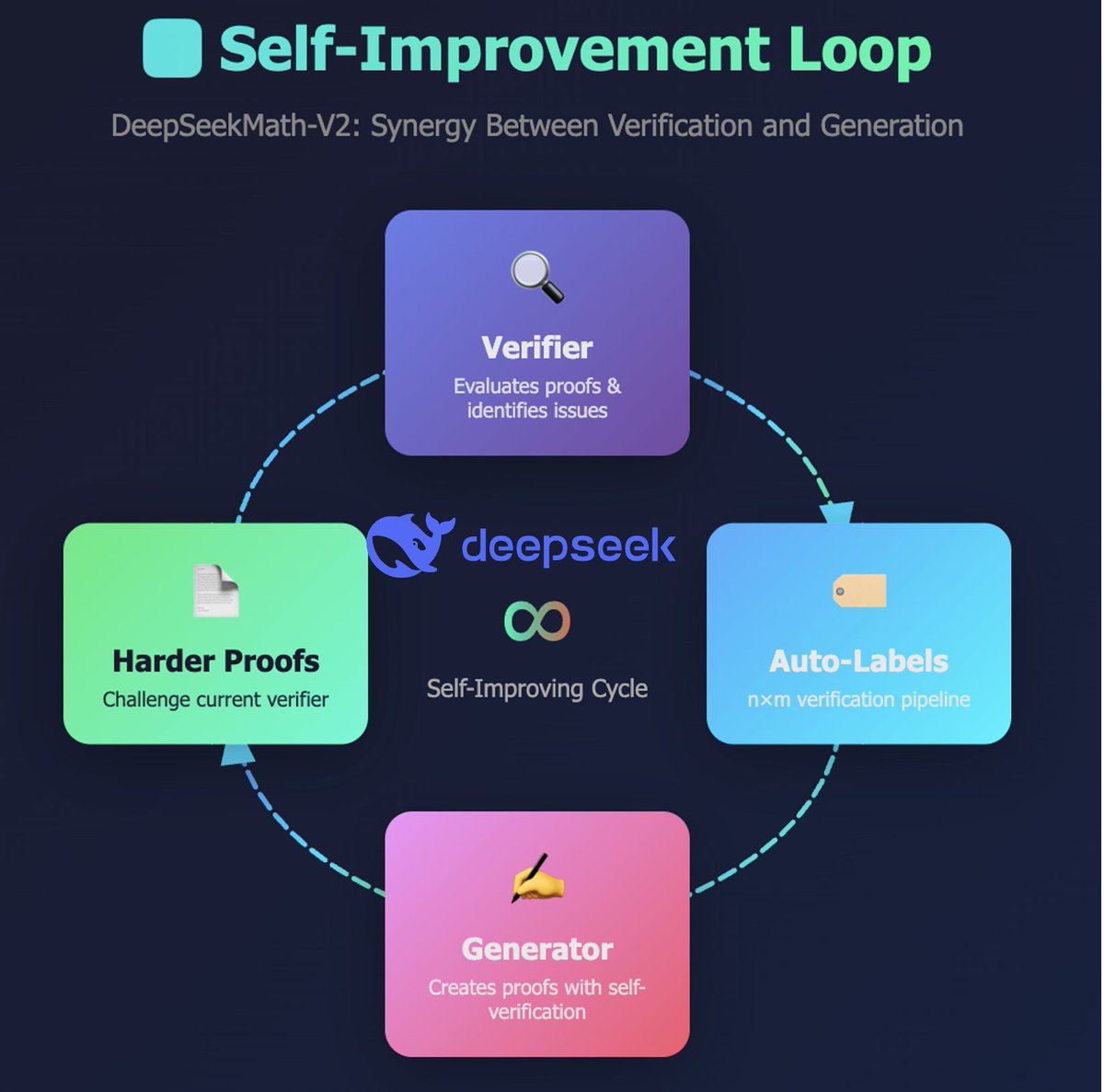
2/n: Momento "Sou tão burro" (comparável ao "momento eureka" do DeepSeek R1) O avanço tecnológico mais importante no artigo DeepSeekMath-V2 não é o desempenho de nível Ouro da IMO! Então, o que é? Trata-se da capacidade de conceder ao modelo recursos para verificar de forma confiável sua própria geração de amostras. Isso tem sido muito difícil para os Modelos de Aprendizagem Baseados em Lógica (mesmo os de raciocínio). Citar: Quando um gerador de provas falha em produzir uma prova completamente correta de primeira — algo comum em problemas complexos de competições como a IMO e a CMO — a verificação e o refinamento iterativos podem melhorar os resultados (até certo ponto). Isso envolve analisar a prova com um verificador externo e instruir o gerador a corrigir os problemas identificados. No entanto, observamos uma limitação crítica: quando solicitado a gerar e analisar sua própria prova simultaneamente, o gerador tende a declarar-se correto mesmo quando o verificador externo identifica facilmente as falhas. Em outras palavras, embora o gerador possa refinar as provas com base em feedback externo, ele não consegue avaliar seu próprio trabalho com o mesmo rigor que o verificador dedicado. Essa observação nos motivou a dotar o gerador de provas com capacidades genuínas de verificação." @gm8xx8 @teortaxesTex @rohanpaul_ai @ai_for_success
3/n: O modelo DeepSeekMath-V2 foi literalmente ameaçado para não trapacear. Você pode ler isso no modelo de prompt. Liang Wengfeng é um pai rigoroso!!!
