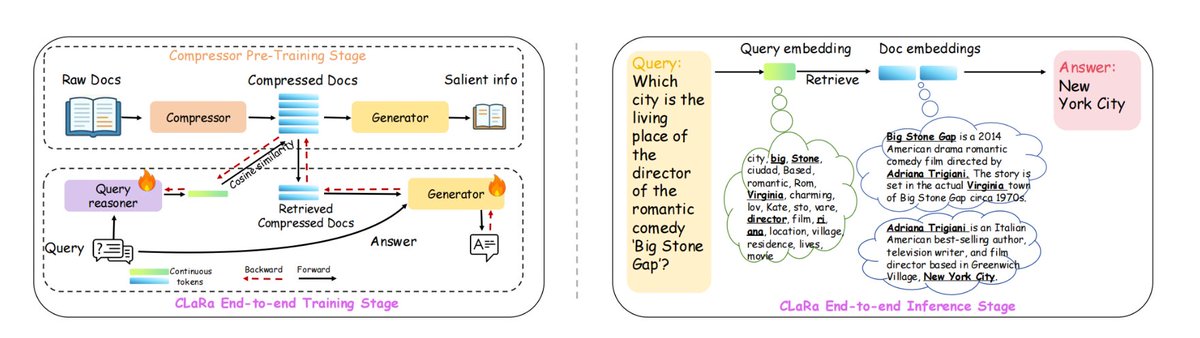
A Apple desenvolveu uma nova estrutura RAG chamada ml-clara, que aborda as ineficiências no tratamento de contextos longos e a separação dos processos de otimização de recuperação e geração. A ideia central é evitar alimentar um modelo grande com o texto inteiro, mas, em vez disso, comprimir os processos de "recuperação" e "geração" no mesmo espaço vetorial contínuo e diferenciável, permitindo um treinamento unificado e inferência em um único estágio. Isso aborda as seguintes questões: 1) o aumento do tamanho do contexto, que leva a uma explosão no custo computacional; 2) a inconsistência nos objetivos de otimização causada pelo treinamento independente da recuperação e dos geradores; e 3) o problema da desconexão do gradiente. Em NQ, HotpotQA, MuSiQue e 2Wiki, manteve sua posição de liderança em diferentes taxas de compressão de 4×/16×/32×, e mesmo com compressão de 32×, ainda era superior à linha de base de busca pura não comprimida. O comprimento do contexto pode ser comprimido em até 32×–64×, mantendo as informações essenciais necessárias para gerar uma resposta precisa. Especificamente: 1. Primeiro, comprima o pré-treinamento, compactando os documentos em vetores de 32 a 256 dimensões, preservando a semântica de perguntas e respostas/repetição. 2. Em seguida, ajuste as instruções para adaptar o vetor comprimido à tarefa subsequente de resposta a perguntas. 3. Treinamento conjunto de ponta a ponta adicional, otimizando tanto a recuperação quanto os geradores. #RAG #mlclara
github:github.com/apple/ml-clara