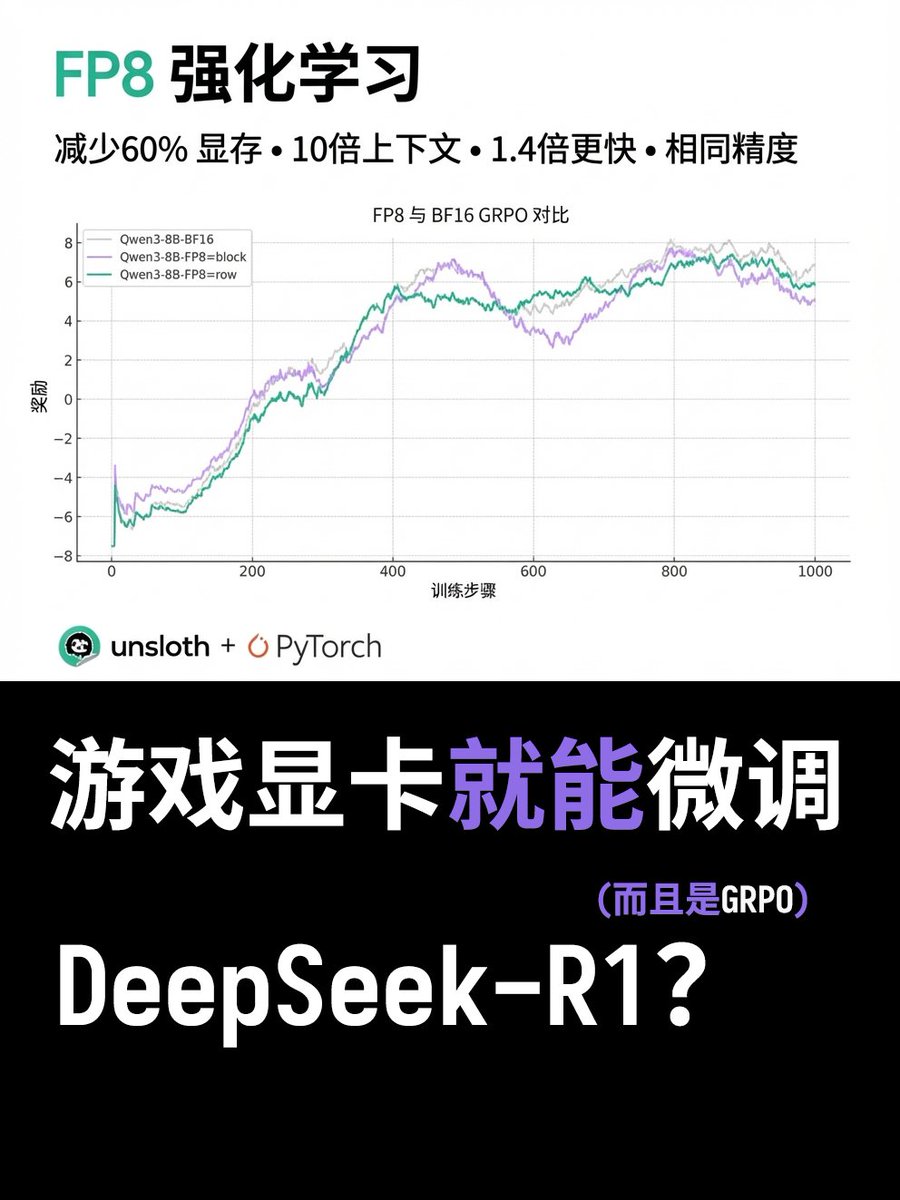
Os cartões de jogo agora também podem usar FP8 GRPO? A Unsloth acaba de lançar um novo tutorial mostrando como otimizar o GRPO FP8 do DeepSeek-R1 com o mínimo de VRAM! Eles colaboraram com o PyTorch para melhorar a velocidade de inferência de RL em FP8 em 1,4 vezes. Em seguida, refinaram o processo reduzindo a memória da GPU em 60% e aumentando o comprimento do contexto em 12 vezes. Agora está disponível no framework Unsloth. Essa abordagem de aprendizado por reforço, que possibilita a adoção generalizada da precisão FP8, permite que o FP8 GRPO seja implementado em GPUs de consumo (como RTX 40, 50, etc.). Os dados de teste mostram que o FP8 GRPO no Qwen3-1.7B agora requer apenas 5 GB de VRAM para funcionar. Endereço do tutorial: