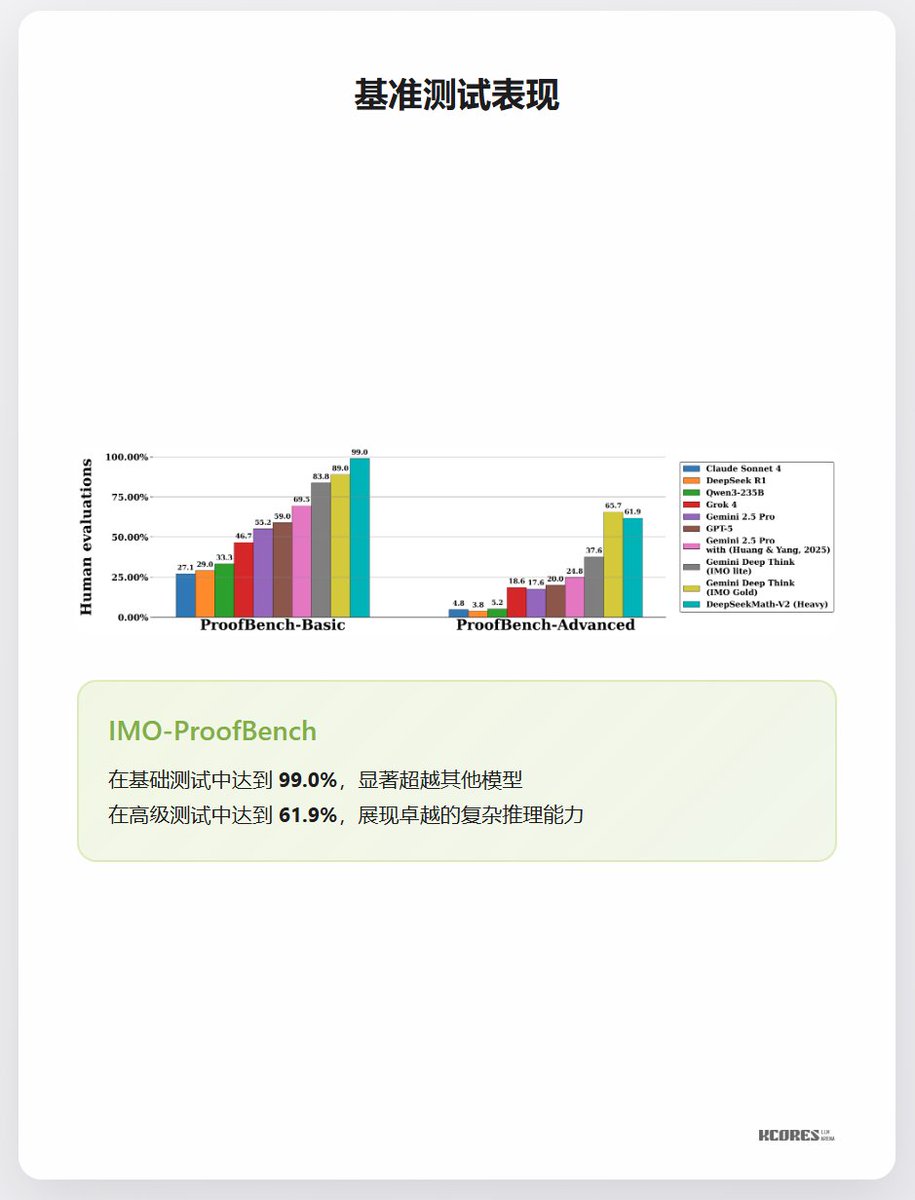
Uma única imagem para entender o novo modelo DeepSeek, DeepSeek-Math-V2! DeepSeek acaba de lançar o DeepSeek-Math-V2! Isso mesmo, este é um modelo específico para o domínio do raciocínio matemático. Desta vez, ele foi pós-treinado/ajustado com base no DeepSeek-V3.2, o que significa que o DeepSeek migrou completamente para a nova arquitetura. Em termos de desempenho, alcançou 83,3% na IMO 2025 (Olimpíada Internacional de Matemática), conquistando a medalha de ouro. Superou completamente o ProofBench-Basic, obtendo 99% e derrotando todos os outros modelos. O ProofBench-Advanced ficou em segundo lugar, atrás apenas do Gemini Deep Think (que é uma plataforma baseada em agentes, não um modelo puro). Aliás, meu país também ficou em primeiro lugar na IMO 2025 este ano. Então, calculei a média da pontuação do DeepSeek-Math-V2 de 83,3% em cada questão, e a pontuação deveria ser de 210 pontos (de um total de 252, com 83,3% de precisão), o que nos colocaria entre os Estados Unidos (216 pontos) e a Coreia do Sul (203 pontos), ou seja, em 3º lugar.
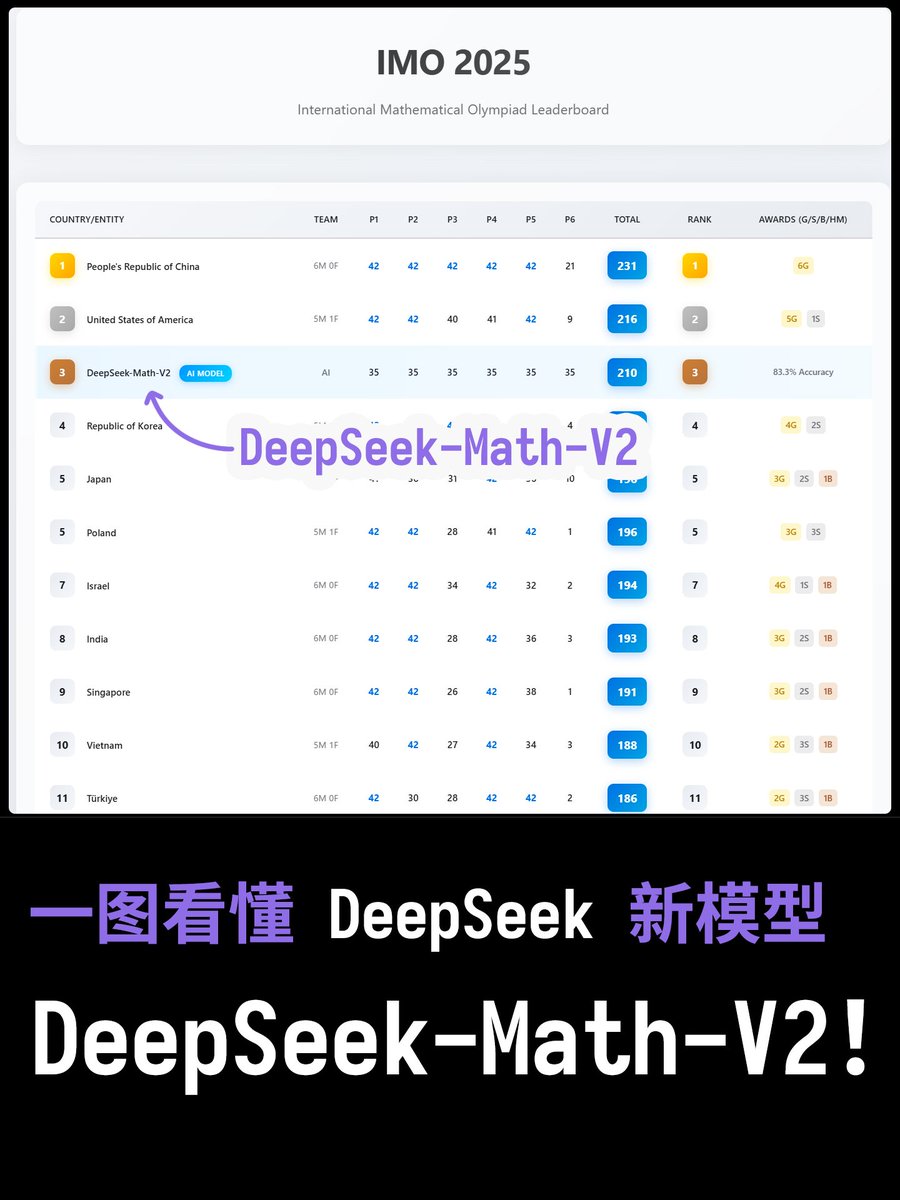
As pontuações foram ajustadas à tabela de classificação da IMO deste ano.

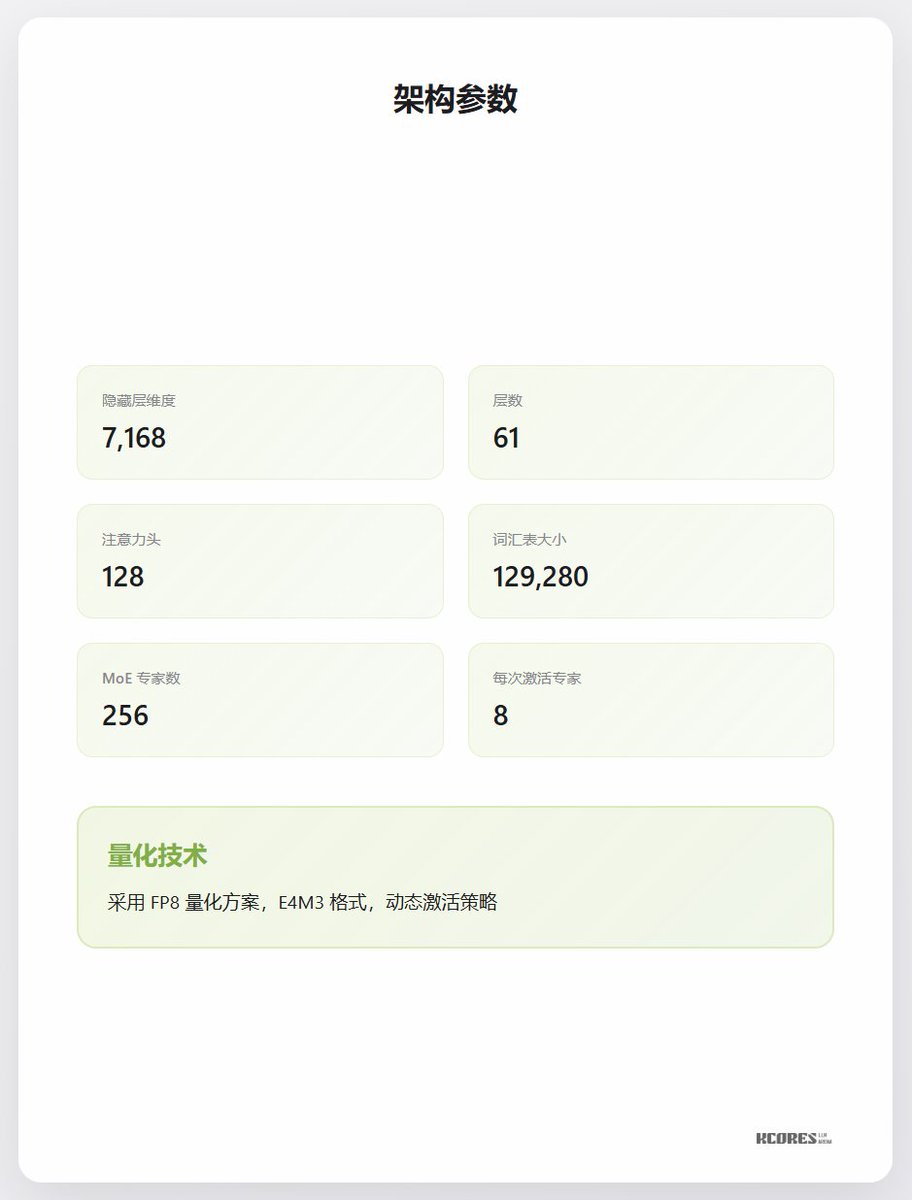
Parâmetros básicos


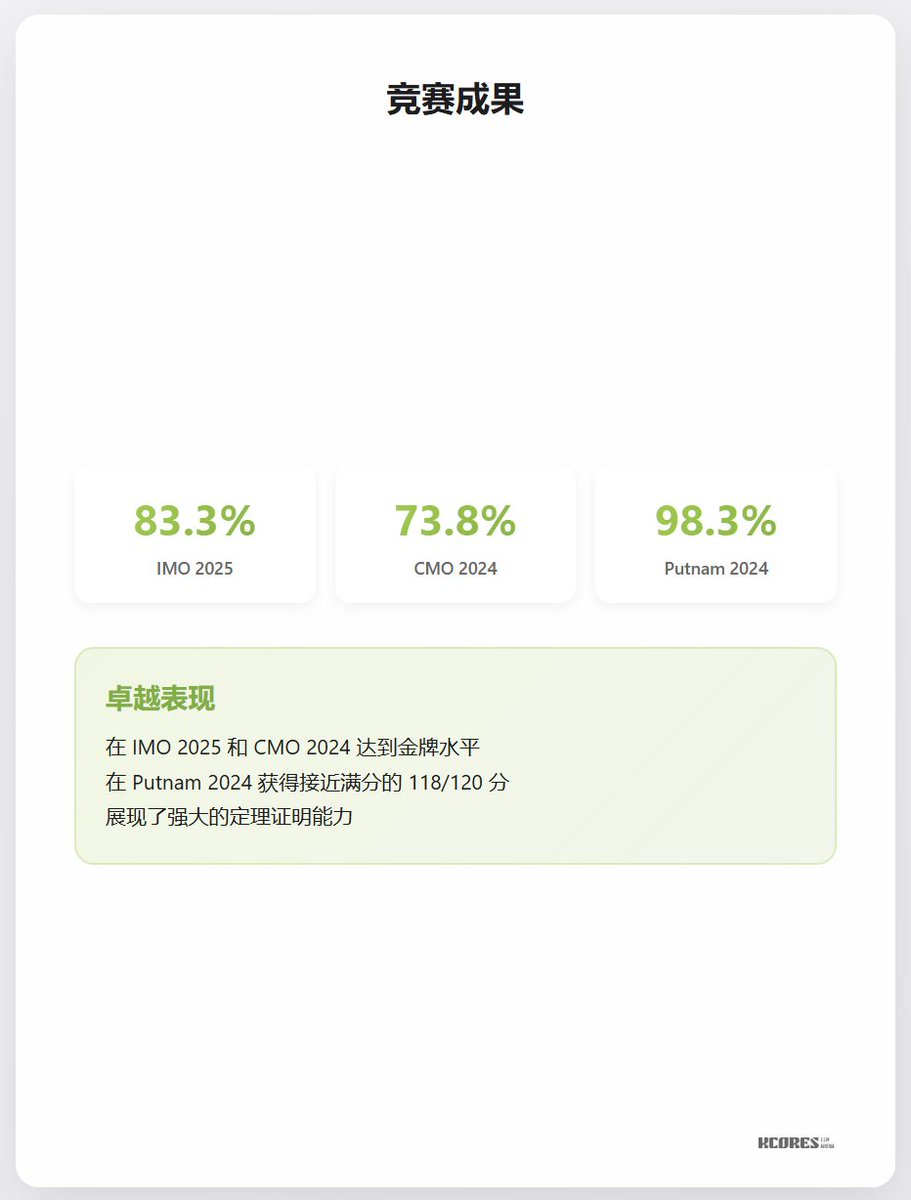
referência