Imagine uma equipe de software trabalhando em um grande projeto, mas com uma regra peculiar: cada engenheiro só pode trabalhar por algumas dezenas de minutos, no máximo algumas horas, e então um novo engenheiro precisa ser substituído. Assim, essa equipe funciona bem para tarefas simples do projeto, mas para projetos mais complexos que exigem longos períodos de execução, como clonar um arquivo claude.ai, eles simplesmente não conseguem. Essencialmente, este é o estado atual dos Agentes de Codificação: eles carecem de memória e possuem uma janela de contexto de duração limitada. Portanto, não são adequados para executar tarefas de longa duração. A postagem do blog da Anthropic, "Effective harnesses for long-running agents" (Mecanismos eficazes para agentes de longa duração), discute especificamente como permitir que os agentes continuem executando tarefas em várias janelas de contexto. Primeiramente, vamos analisar os principais problemas que o Agente encontra em tarefas longas. Existem três tipos principais: O primeiro tipo é chamado de "tentar fazer muito de uma vez". Por exemplo, se você pedir a um agente para clonar um site como claude.ai, ele tentará concluir toda a aplicação de uma só vez. Como resultado, o contexto não terá sido totalmente utilizado, metade da funcionalidade terá sido escrita e o código estará uma bagunça completa. Quando a próxima sessão chegar, ela só poderá olhar fixamente para o produto inacabado, gastando muito tempo tentando adivinhar o que foi feito nas etapas anteriores. O segundo tipo é chamado de declaração prematura de vitória. Uma parte do projeto é concluída, então um agente posterior verifica o ambiente, acha que está quase pronto e considera o trabalho encerrado. Uma série de funcionalidades faltantes são ignoradas. O terceiro tipo é chamado de teste superficial. O agente modifica o código, executa alguns testes unitários ou acessa a interface via curl e pensa que está tudo bem, sem realmente passar pelo processo de ponta a ponta como um usuário real. O ponto em comum entre esses três modos de falha é que o agente desconhece o objetivo global, nem sabe onde parar ou o que deixar para o próximo agente. Qual é, então, a solução da Anthropic? Essencialmente, essas são algumas soluções prontamente disponíveis na engenharia de software: introduzir um mecanismo colaborativo semelhante ao de uma equipe humana, dividir tarefas complexas em tarefas menores, rastreáveis e verificáveis, estabelecer mecanismos claros de transferência de responsabilidade e verificar rigorosamente os resultados das tarefas. Um agente de inicialização aparece apenas uma vez, quando o projeto é iniciado. Sua função é configurar o ambiente de execução do projeto. Ele funciona como um arquiteto, escrevendo um script init.sh para facilitar a inicialização subsequente do servidor de desenvolvimento, criando um arquivo claude-progress.txt para registrar o progresso, realizando o primeiro commit no Git e, mais importante, gerando uma lista de funcionalidades. Quão detalhada é essa lista de recursos? No caso da clonagem do claude.ai, são listadas mais de 200 funções específicas, como permitir que os usuários iniciem novas conversas, insiram perguntas, pressionem Enter e vejam as respostas da IA. Cada estado inicial é marcado como falho, e o Agente deve verificar cada um individualmente antes que possa ser alterado para bem-sucedido. Além disso, há um detalhe importante: esta lista não está escrita em Markdown, mas sim como um array JSON. Isso ocorre porque experimentos da Anthropic demonstraram que, em comparação com o Markdown, os modelos são menos suscetíveis a alterações ou sobrescritas arbitrárias durante o processamento de JSON. O outro é o agente de codificação. Após a inicialização do projeto, ele é responsável pelo trabalho. Suas principais diretrizes de comportamento são apenas duas: executar uma função por vez e deixar o ambiente limpo após a conclusão. O que define um ambiente limpo? Imagine seus padrões para enviar código para a branch principal: nenhum bug grave, código organizado e bem documentado, para que a próxima pessoa possa começar a trabalhar em novas funcionalidades imediatamente, sem precisar limpar sua bagunça primeiro. Antes de cada operação, ele realiza algumas tarefas: – Execute o comando `pwd` para ver em qual diretório você está. – Leia os logs do Git e os arquivos de progresso para entender o que foi feito na execução anterior. – Consulte a lista de recursos e escolha o recurso inacabado de maior prioridade. – Execute um teste básico para garantir que o aplicativo ainda seja utilizável. Em seguida, concentre-se em uma funcionalidade e, depois de concluí-la: - Limpar mensagem de commit do Git – Atualizar claude-progress.txt – Modifique apenas os campos de status na lista de funcionalidades; nunca exclua ou modifique os próprios requisitos. A genialidade deste projeto reside na externalização da "memória" em arquivos e no histórico do Git. Cada iteração do agente não depende de informações fragmentadas na janela de contexto; em vez disso, imita as tarefas diárias de um engenheiro humano confiável: primeiro, sincronizar o progresso, confirmar se o ambiente está funcionando corretamente e, em seguida, iniciar o trabalho. As melhorias no processo de teste merecem uma discussão à parte. O agente utilizava apenas verificação em nível de código, como executar testes unitários ou chamar APIs. O problema é que muitos bugs só aparecem quando o usuário interage de fato com a página. A solução é equipar o Agente com uma ferramenta de automação de navegador, como o Puppeteer MCP. O Agente agora pode abrir um navegador, clicar em botões, preencher formulários e visualizar os resultados de renderização da página como uma pessoa real. A Anthropic publicou um GIF animado mostrando uma captura de tela feita pelo Agente durante o teste de um clone do claude.ai, demonstrando que ele realmente opera como um usuário. Essa técnica melhora significativamente a precisão da verificação funcional. Claro que existem limitações. Por exemplo, o Puppeteer não consegue capturar pop-ups de alerta nativos do navegador, e funcionalidades que dependem de pop-ups são propensas a erros. Este plano ainda deixa algumas questões em aberto. Por exemplo, é melhor ter um agente de uso geral que lide com tudo, ou ter funções especializadas? Talvez fosse mais eficaz ter um agente de teste específico para testes e um agente de limpeza de código específico para limpeza. Por exemplo, esse conjunto de experiências é otimizado para desenvolvimento web full-stack. Será que pode ser transferido para tarefas de ciclo longo, como pesquisa científica ou modelagem financeira? Deveria ser possível, mas isso precisa ser verificado por meio de experimentos. Xiangma@xicilion disse: No final das contas da IA, ainda resta a engenharia de software. Os agentes de IA não são mágicos. Eles também precisam aprender com a experiência humana em engenharia de software, decompor tarefas complexas em tarefas simples e contar com um ambiente de trabalho estruturado e um mecanismo claro de transição de responsabilidades. Por que os engenheiros humanos conseguem colaborar entre equipes e fusos horários diferentes? Porque eles têm acesso ao Git, documentação, revisão de código e testes. Para que os agentes de IA trabalhem de forma autônoma por longos períodos, eles também precisam levar essas ferramentas consigo. A abordagem da Anthropic simplesmente transforma as melhores práticas de engenharia de software em palavras-chave e conjuntos de ferramentas que o agente consegue entender. Ela não torna o modelo mais inteligente, mas sim fornece a ele uma estrutura melhor. A abordagem da Anthropic é digna de aprendizado. Seja usando Claude, GPT ou outro modelo, ao projetar tarefas longas com várias rodadas, é fundamental entender claramente como levar o agente para a próxima rodada rapidamente e como evitar que ele reinvente a roda ou crie um código confuso. Mesmo em tarefas de rodada única, é preciso compreender que elas não possuem memória; é necessário usar arquivos externos para ajudá-las a "lembrar" o que já fizeram. Com as capacidades atuais do modelo, o Coding Agent já consegue fazer muita coisa. A questão principal é se você consegue decompor tarefas e projetar fluxos de trabalho de uma maneira semelhante à engenharia de software. Texto original: Sistemas eficazes de fixação para agentes de longa duração https://t.co/tERUGrV9wC traduzir:
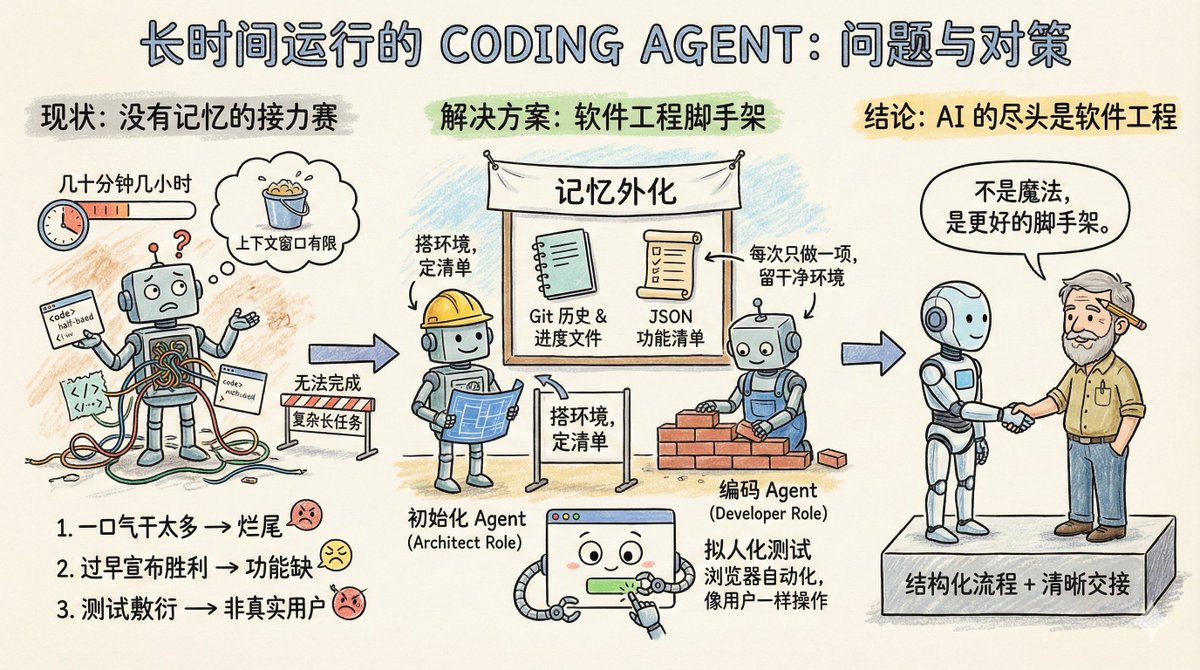
A lista de tarefas mencionada no artigo é um tipo de contextox.com/stevenlu1729/s…s os contextos globais, não pode ser muito longa, caso contrário, a janela de contexto para executar tarefas não seria suficiente.