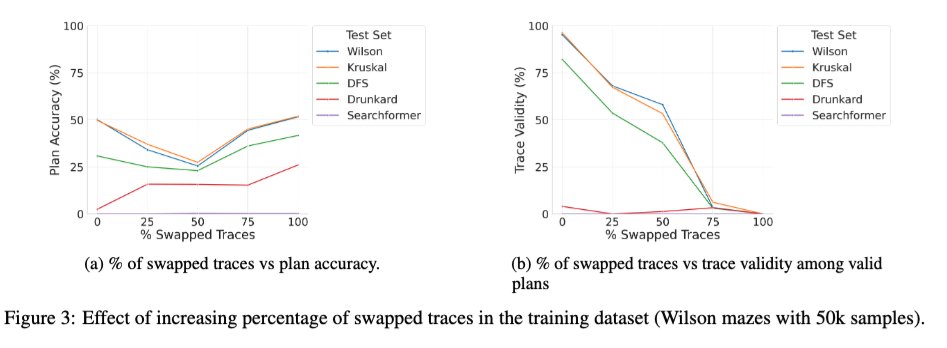
Acabamos de publicar uma versão expandida do artigo "Beyond Semantics" — nosso estudo sistemático sobre o papel dos tokens intermediários em LRMs — no arXiv, e pode ser do interesse de alguns de vocês. 🧵 1/ Um novo estudo intrigante investiga o efeito do treinamento do Transformer base com uma mistura de traços corretos e incorretos. Observamos que, à medida que a porcentagem de traços incorretos (trocados) durante o treinamento varia de 0 a 100%, a validade dos traços dos modelos no momento da inferência diminui monotonicamente (gráfico à direita abaixo), como esperado, mas a precisão da solução exibe uma curva em U (gráfico à esquerda)! Isso sugere que o que parece importar é a "consistência" dos traços usados durante o treinamento, e não sua correção.