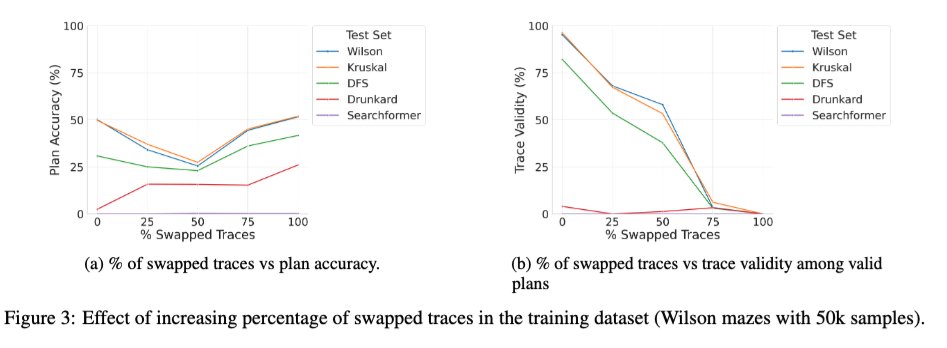
Acabamos de publicar uma versão expandida do artigo "Beyond Semantics" — nosso estudo sistemático sobre o papel dos tokens intermediários em LRMs — no arXiv, e pode ser do interesse de alguns de vocês. 🧵 1/ Um novo estudo intrigante investiga o efeito do treinamento do Transformer base com uma mistura de traços corretos e incorretos. Observamos que, à medida que a porcentagem de traços incorretos (trocados) durante o treinamento varia de 0 a 100%, a validade dos traços dos modelos no momento da inferência diminui monotonicamente (gráfico à direita abaixo), como esperado, mas a precisão da solução exibe uma curva em U (gráfico à esquerda)! Isso sugere que o que parece importar é a "consistência" dos traços usados durante o treinamento, e não sua correção.
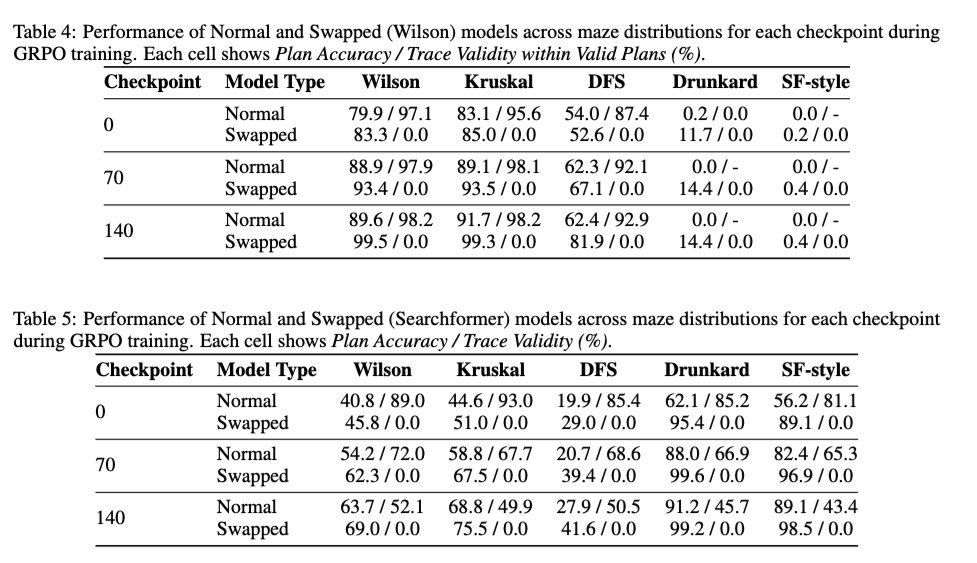
2/ Também analisamos o efeito do aprendizado por reforço (RL) no estilo DeepSeek R1 na validade do traço — para verificar se o RL melhora a validade do traço do modelo base. Os resultados mostram que o RL é basicamente neutro em relação à validade do traço. Ele melhora a precisão da solução mesmo no caso de um modelo treinado com traços 100% trocados, sem aumentar a validade do traço.
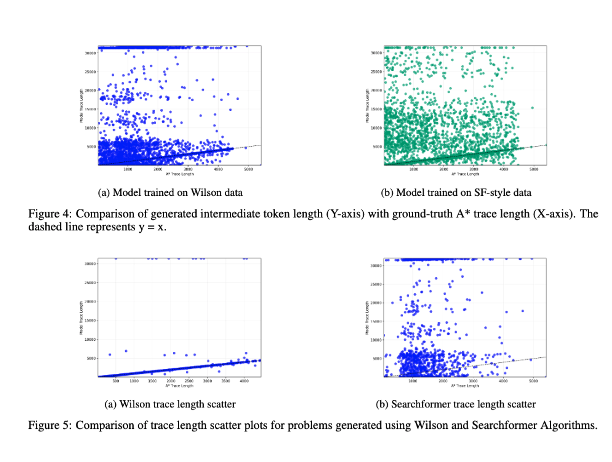
3/ Por fim, incluímos um estudo da correlação entre o comprimento dos tokens intermediários e a complexidade computacional da instância do problema. Os resultados mostram que não há correlação entre eles! (Discuti uma versão anterior deste experimento em https://t.co/RL9ZEOKbpQ)
4/ A nova versão pode ser encontradarxiv.org/abs/2505.13775iCZ5e. Esses resultados também serão apresentados pelos autores principais @karthikv792, @kayastechly e @PalodVardh12428 nos workshops #NeurIPS2025 sobre LAW, ForLM e Raciocínio Eficiente na próxima semana. Apareça para bater um papo!