Vale a pena ler este artigo da Universidade de Stanford 👇🏻 Eles construíram uma estrutura de agente de IA, partindo de zero dados, sem anotações humanas, tarefas cuidadosamente elaboradas ou qualquer demonstração, e mesmo assim ela superou todos os métodos de autoaprendizagem existentes. Essa estrutura é chamada de Agent0: ela liberta agentes inteligentes autoevolutivos da ausência de dados, integrando inferência por meio de ferramentas. Suas conquistas são incríveis. Todos os agentes de "autoaperfeiçoamento" que você já viu têm uma falha fatal: eles só conseguem gerar tarefas um pouco mais difíceis do que aquelas que já conhecem, então imediatamente se deparam com um gargalo. O Agente 0 quebrou esse limite. O ponto principal é: Eles geram dois agentes a partir do mesmo modelo LLM subjacente e os deixam competir. • Agente de percurso - Gera tarefas cada vez mais difíceis. • Agente de execução - Tenta resolver essas tarefas usando raciocínio e ferramentas. Sempre que o agente executor melhora, o agente do percurso é forçado a aumentar a dificuldade. Sempre que a tarefa se torna mais difícil, o agente executor é forçado a evoluir. Isso criou um ciclo curricular em espiral, auto-reforçador, e tudo começou do zero, sem dados, sem pessoas e sem nada. É simplesmente o fato de que os dois agentes inteligentes se impulsionam mutuamente para atingir um nível de inteligência superior. Em seguida, adicionaram códigos de trapaça: Um interpretador completo de ferramentas Python está em um loop. O agente de execução aprende a raciocinar sobre problemas por meio de código. O agente do curso aprende a criar tarefas que exigem o uso de ferramentas. Portanto, ambos os agentes inteligentes estão em constante atualização. E qual foi o resultado? → Habilidade de raciocínio matemático melhorou em +18% → A capacidade de raciocínio geral aumentou em 24% → Supera R-Zero, SPIRAL, Absolute Zero e até mesmo frameworks que utilizam APIs proprietárias externas → Todos esses se originam de dados zero, simplesmente um ciclo de autoevolução. Eles demonstraram inclusive que a curva de dificuldade aumenta durante o processo de iteração: a tarefa começa com geometria básica e eventualmente chega a problemas que envolvem satisfação de restrições, combinatória, quebra-cabeças lógicos e problemas de várias etapas dependentes de ferramentas. Este é o exemplo mais próximo que já vimos de crescimento cognitivo autônomo em LLM. Agent0 é mais do que apenas "RL melhorado". É um modelo para que agentes inteligentes orientem sua própria inteligência. A era dos agentes inteligentes foi inaugurada.

Antes de começar a ler, lembre-se de curtixaicreator.comar esta publicação. Este conteúdo no Threads foi publicado por um mecanismo de conteúdo colaborativo entre humanos e computadores. https://t.co/Gxsobg3hEN
Ideia central: O Agente0 cria dois agentes a partir do mesmo modelo de lógica latente (LLM) subjacente e os força a entrar em um ciclo de feedback competitivo. Um inventa uma tarefa, o outro tenta sobreviver. Essa interação contínua cria um problema de dificuldade de vanguarda, sem paralelo com qualquer conjunto de dados estático.
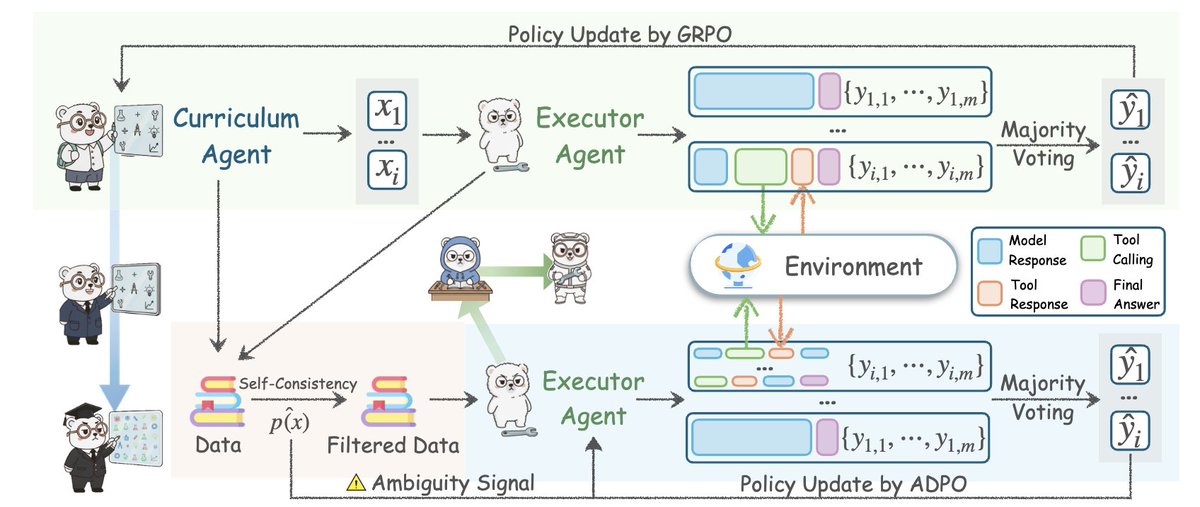
A inovação não reside no jogo autônomo, mas no raciocínio integrado a ferramentas. O agente executivo pode executar código Python real dentro da solução, obter o resultado e atualizar seu raciocínio. Isso permite que o agente curricular responda criando perguntas que exigem o uso de ferramentas. Um ciclo virtuoso.

Eles abordaram o maior modo de falha para agentes autoevolutivos: a estagnação. A maioria dos agenarxiv.org/abs/2511.16043as ligeiramente mais difíceis do que seu nível atual. O Agente 0 usa incerteza, divergência entre respostas amostradas e frequência de chamadas de ferramentas para detectar fragilidades no agente em execução. Leia o artigo completo aqui: https://t.co/7UheEMgrBw

Meu entendimento pessoal é que isso essencialmente usa o LLM para construir dois agentes que competem entre si, o que também é uma espécie de lógica de pensamento GAN. Em outras palavras, o desenvolvimento se forma no processo de resolução constante do conflito entre Yin e Yang. No entanto, para que esse sistema funcione, é impossível não dar aos agentes a capacidade de "buscar e criar ferramentas". Contanto que tenham essa capacidade, os agentes podem interagir continuamente com o mundo por meio do aprendizado por reforço e, eventualmente, encontrar soluções para os problemas. Isso é semelhante à prática humana.
Por fim, agradeço por dedicar seu tempo para ler este tweet! Siga @Yangyixxxx para informações sobre IA, insights de negócios e estratégias de crescimento. Se você gostou deste conteúdo, curta e compartilhe o primeiro tweet para que mais pessoas possam acessar informações valiosas.