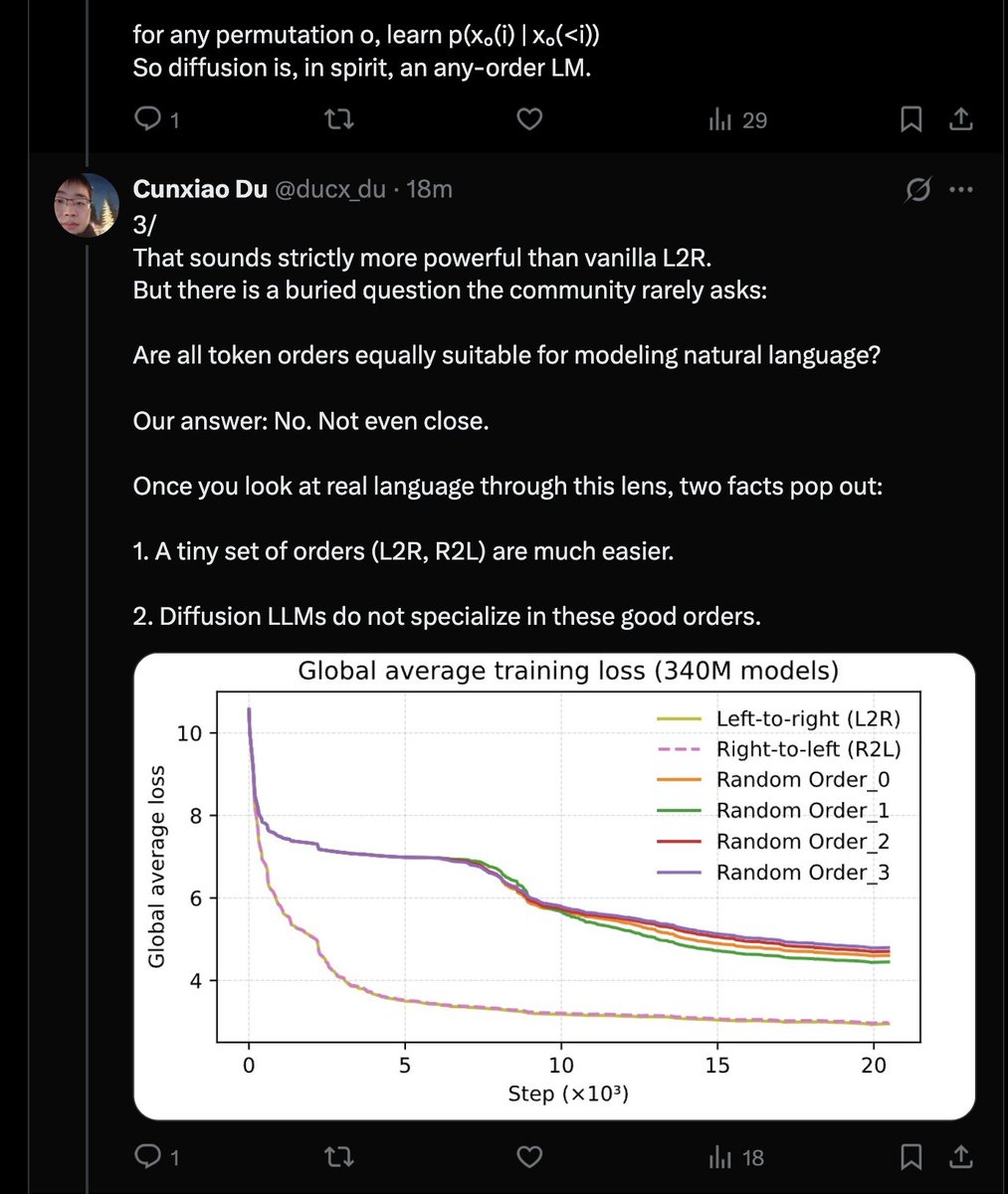
Narrativa extremamente impactante. Por padrão, os modelos de difusão não fazem sentido, pois a linguagem é Markoviana e as ordens da esquerda para a direita *ou* da direita para a esquerda são estritamente superiores. Parece que a única maneira sensata de treinar DLLMs é com a função de perda log-sum.