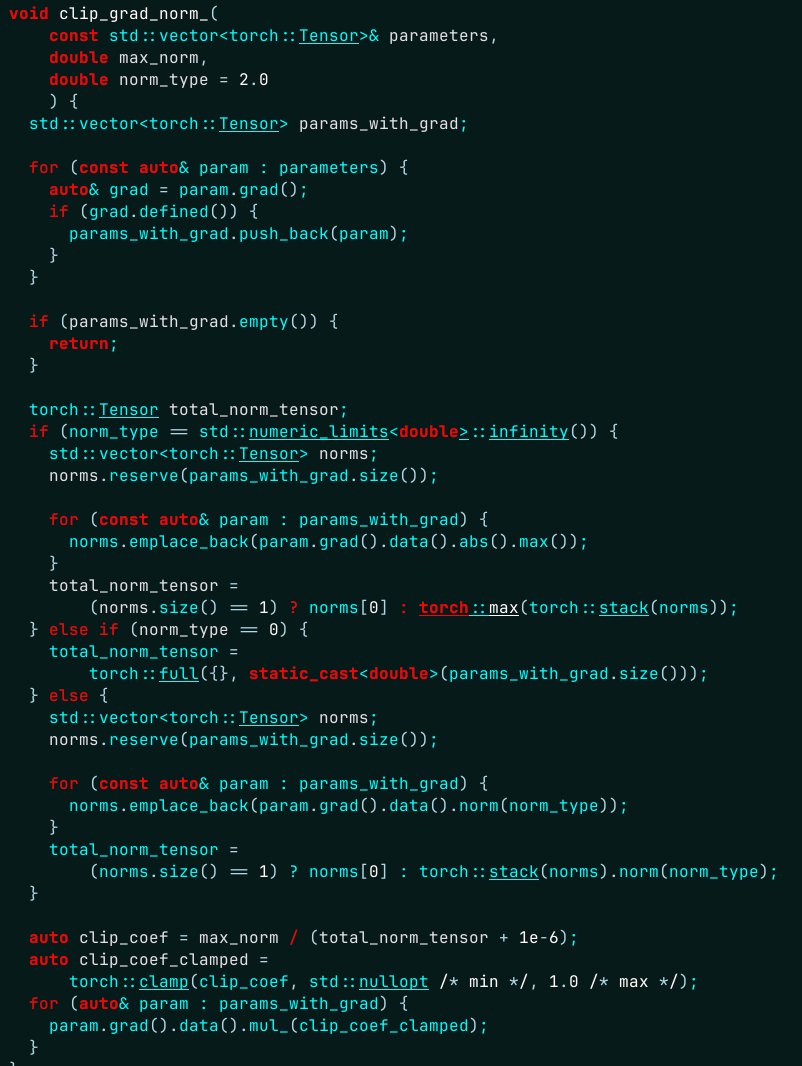
Passei uma hora tentando descobrir de onde vinham as centenas de sincronizações CUDA extras... sério, que coisa... // Diferença em relação à versão em Python: ao contrário da versão em Python, mesmo quando // Ignorando as verificações de finitude (error_if_nonfinite = false), esta função // irá introduzir a sincronização dispositivo CPU (para dispositivos onde isso faz // sentido!) para retornar um `double` do lado da CPU. Esta versão em C++, portanto // Não pode ser executado de forma totalmente assíncrona em relação ao dispositivo dos gradientes.
Estava sincronizando sem motivo algum... resolvido aqui.