A infraestrutura OlmoRL era 4 vezes mais rápida que a Olmo 2 e tornava a execução de experimentos muito mais barata. Algumas das mudanças: 1. Loteamento contínuo 2. atualizações durante o voo 3. amostragem ativa 4. Muitas melhorias em nosso código multithread.
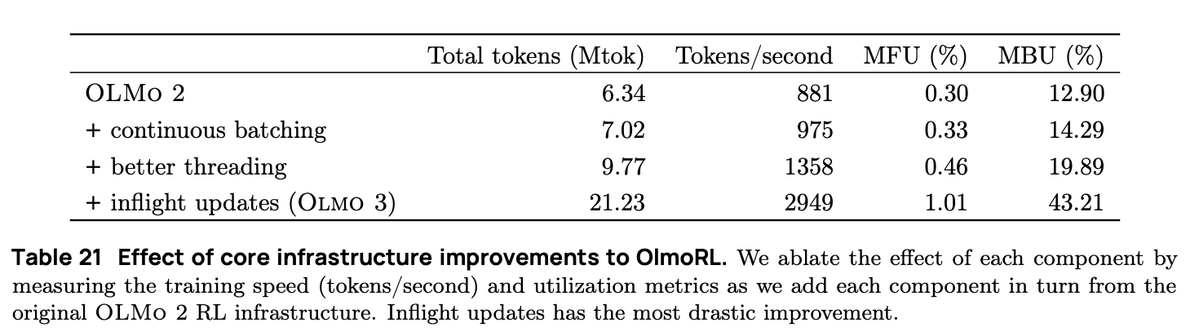
No processamento em lote contínuo, passamos para uma configuração de geração totalmente assíncrona, onde temos duas filas: uma para solicitações e outra para resultados da geração. Nossos atores operam de forma totalmente assíncrona, buscando continuamente novos prompts para gerar à medida que as conclusões são finalizadas.
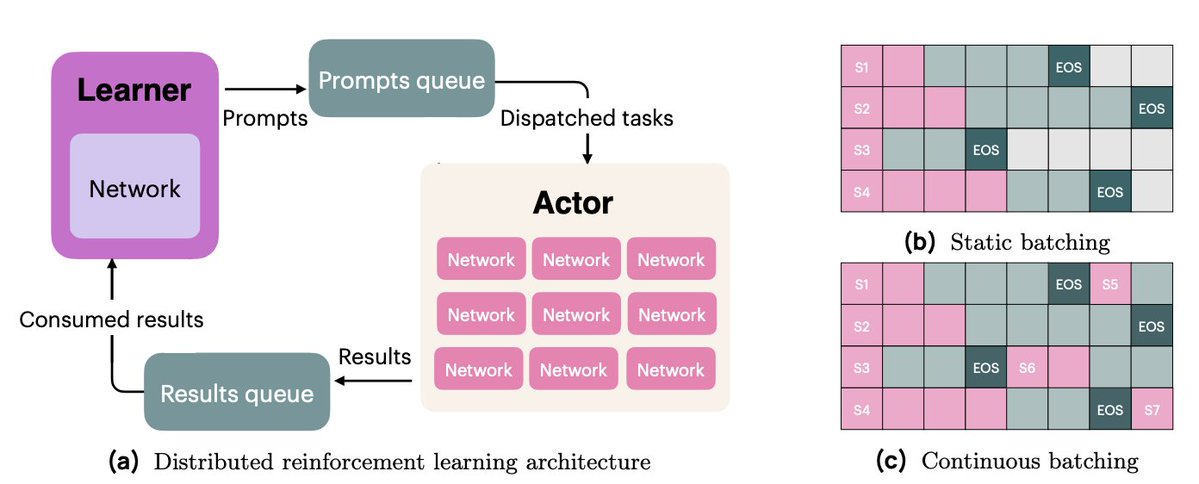
Com atualizações em tempo real (PipelineRL, de @alexpiche_, @DBahdanau e outros), atualizamos nossos atores no meio da geração. O sistema fica muito mais rápido, pois não precisamos esvaziar as filas de geração para atualizar os pesos (o que é o mesmo problema do processamento em lote estático).

A amostragem ativa (uma contribuição inédita de @mnoukhov) resolve um problema recorrente no GRPO, onde grupos com variância 0 na recompensa (e, portanto, vantagem 0, resultando em gradiente 0) são filtrados, fazendo com que o tamanho do lote varie a cada etapa de treinamento.
Trabalhos anteriores resolveram o problema do tamanho variável dos lotes amostrando 3 vezes mais grupos do que o necessário, na esperança de que sempre houvesse grupos suficientes após a filtragem. Em vez disso, Michael alterou nosso código para esperar até termos um lote completo de grupos com recompensas não constantes antes do treinamento.
Isso exigiu um trabalho minucioso e complexo para manter nossos atores e alunos sincronizados.
Por fim, dedicamos muito tempo à refatoração do nosso código para reduzir a sincronização, permitindo que nossos atores operassem de forma assíncrona. Isso envolveu um extenso trabalho de engenharia com as APIs de threading e asyncio do Python.
Nosso trabalho de infraestrutura de RL foi um esforço coletivo, com contribuições minhas, de @hamishivi, @mnoukhov, @saurabh_shah2 e @tyleraromero, e construído sobre as bases deixadas por @vwxyzjn.
Para saber mais sobre o nosso trabalho, consulte o artigo, a publicação no blog e os trabalhos relacionados, incluindo a nossa transmisx.com/natolambert/st… às 9h (horário do Pacífico).