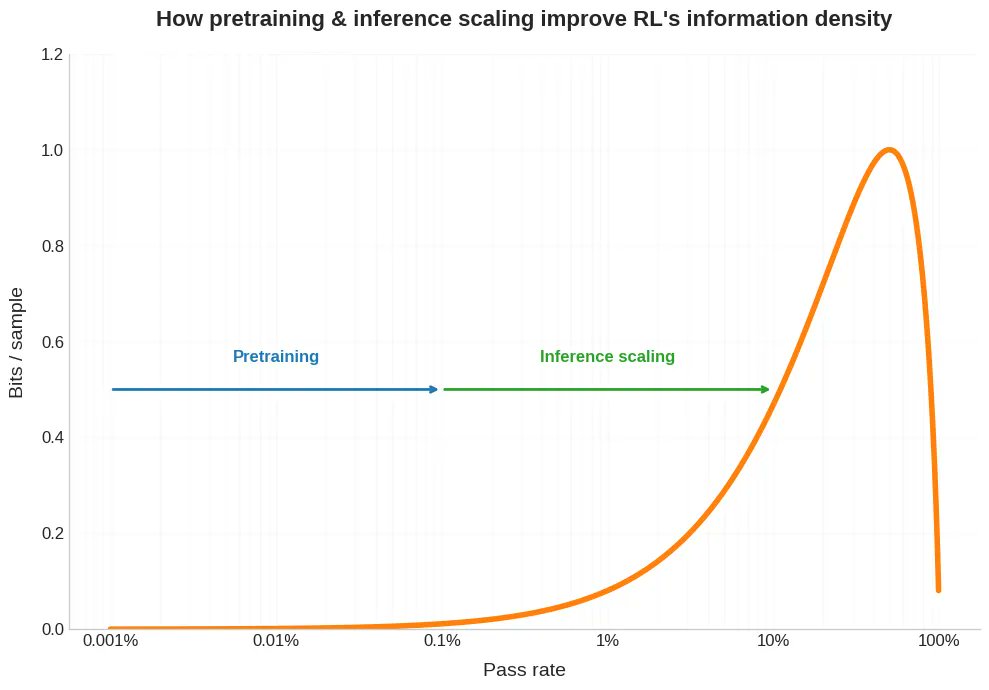
Novo post no blog. Recentemente, as pessoas têm comentado sobre como obter uma única amostra em aprendizado por reforço exige muito mais poder computacional do que no pré-treinamento. Mas isso é apenas metade do problema. Na vida real, essa amostra cara geralmente também fornece muito menos bits. Isso tem implicações para a escalabilidade do RLVR, além de nos ajudar a entender por que o jogo autônomo e o aprendizado curricular são tão úteis para o RL, por que os modelos baseados em RL são tão irregulares e como podemos pensar sobre o que os humanos fazem de forma diferente. Link abaixo.