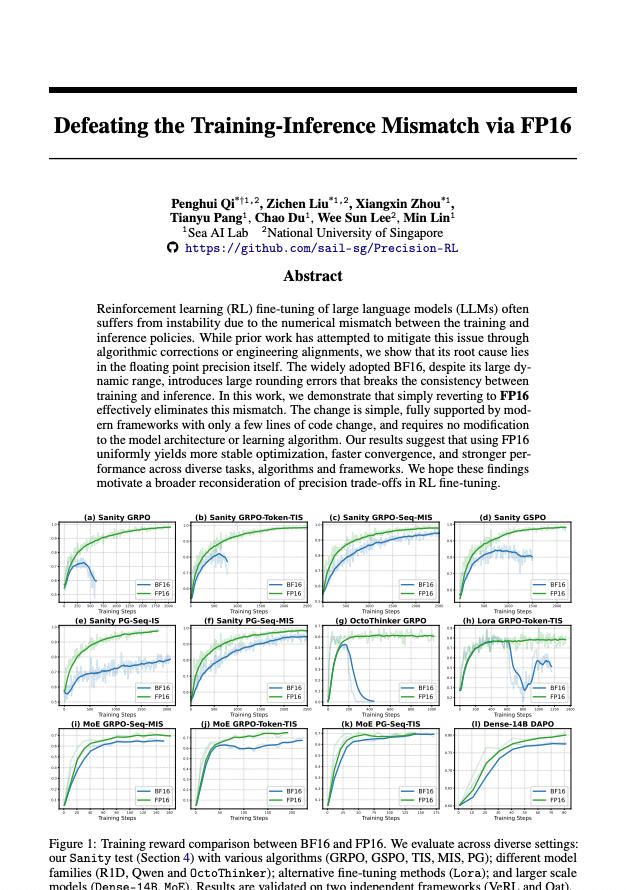
#8 - Superando a discrepância entre treinamento e inferência por meio do FP16 arxiv.org/abs/2510.26788o8w36nc Dando continuidade ao mesmo tema dos capítulos 6 e 7, considere esta leitura obrigatória para se atualizar sobre o assunto. Trabalhos anteriores tentaram corrigir esse problema de incompatibilidade entre treinamento e inferência com técnicas de amostragem por importância ou engenharia complexa para melhor alinhar os kernels. Isso ajuda até certo ponto, mas: >custa computação extra (passagens adicionais para frente) >Não resolve realmente o problema de você estar otimizando uma e implantando outra. >ainda pode ser instável Portanto, a tese do artigo é: o verdadeiro vilão é o BF16. Use FP16. Me diverti muito criando vários memes sobre isso no meu Twitter.
#9 - O Potencial da Otimização de Segunda Ordem para LLMs: Um Estudo com Gauss-Newton Completo link - https://tarxiv.org/abs/2510.09378go demonstra que, ao usar a curvatura Gauss-Newton real em vez das aproximações simplificadas que todos utilizam, é possível treinar LLMs drasticamente mais rápido: o GN completo reduz o número de etapas de treinamento em cerca de 5,4 vezes em comparação com o SOAP e 16 vezes em comparação com o muon. Eles também não oferecem garantias teóricas em relação a essa afirmação, nem ela foi testada em larga escala (apenas 150 milhões de parâmetros).
