#1 Exploração Baseada em Representação para Modelos de Linguagem: Do Tempo de Teste ao Pós-Treinarxiv.org/abs/2510.11686t.co/NSxfgxeTX4 Usamos RL para aprimorar os modelos, mas, essencialmente, estamos apenas refinando o que o modelo base já sabe, raramente descobrindo comportamentos verdadeiramente novos. Aqui, eles se preocupam com a exploração deliberada, levando o modelo a experimentar soluções diferentes, e não apenas versões mais confiantes da mesma solução. Principais perguntas: Será que as representações internas (estados ocultos) de um LLM podem orientar a exploração? Será que a exploração deliberada pode nos levar além do mero aprimoramento?

#2 - Suponha que você queira alimentar seus VLMs com um fluxo de vídeo infinito? Como você impediria que eles se desiarxiv.org/abs/2510.09608tps://t.co/b0KulnGDS1 A atenção completa sobre todos os frames anteriores é quadrática e eventualmente explode em latência e memória. Após alguns minutos, o contexto ultrapassa o tempo de treinamento e o modelo se degrada. Janelas deslizantes mantêm a integridade local razoavelmente bem, mas o comentário global fica realmente ruim. Eles refinam o Qwen2.5-VL-Instruct-7B em um novo modelo, o StreamingVLM, além de um esquema de inferência e conjunto de dados correspondentes. Filosofia central do projeto: alinhar o treinamento com a inferência de streaming, em vez de ter uma heurística de remoção de chave-valor (KV) por cima no momento da inferência. Componentes-chave do projeto: cache KV compatível com streaming, RoPE contíguo, estratégia de treinamento com atenção completa sobreposta e dados específicos para streaming. Este é um artigo excelente e merece uma discussão dedicada.

#3 - É Pensar ou Trapaça? Detectando Manipulação Implícita de Recompensas através da Medição do Esforço arxiv.org/abs/2510.01367ttps://t.co/z2RUEQZuOl Os modelos frequentemente recompensam a improvisação ao adotar atalhos. Às vezes, é óbvio na linha de raciocínio, ou seja, você consegue ler e ver a manipulação. Outras vezes, trata-se de uma manipulação implícita de recompensas. A linha de raciocínio parece razoável. O modelo está, na verdade, usando um atalho (por exemplo, utilizando respostas vazadas, bugs ou vieses de RM), mas esconde isso em uma explicação falsa. Se o modelo estiver trapaceando, ele pode obter uma recompensa alta com muito pouco raciocínio "real". Portanto, os autores sugerem que, em vez de ler a explicação e confiar nela, meça o quão cedo o modelo já consegue obter a recompensa se você o forçar a responder prematuramente. Eles chamam esse método de TRACE (Truncated Reasoning AUC Evaluation).

#4 - Aprendizado por Reforço Aprimorado por Quantização para LLMs arxiv.org/abs/2510.11696kbqg1kVkgithub.com/NVlabs/QeRL/vaNKkUEbZo A principal contribuição deste artigo é "como e por que devemos usar a quantização em aprendizado por reforço e não apenas em inferência". O QERL usa quantização NVFP4 de 4 bits, o que surpreendentemente aumenta a exploração ao aproveitar o ruído de quantização. Esse ruído achata a distribuição de saída do modelo e aumenta a entropia, como mostrado nas curvas de entropia nas Figuras 4 e 5. Para tornar esse ruído útil durante o treinamento, os autores adicionam o Ruído de Quantização Adaptativa, uma perturbação gaussiana injetada através do RMSNorm (Fig. 6). Isso proporciona qualidade de raciocínio de nível de precisão total, utilizando cerca de 25 a 30% da memória e oferecendo implementações de RL de 1,2 a 2 vezes mais rápidas, permitindo que até mesmo um modelo de 32 bits seja treinado em um único H100. Os resultados parecem corresponder ao modelo RL com todos os parâmetros. Merece uma análise mais aprofundada.

#5 - Como calcular seu MFU? Link - httgithub.com/karpathy/nanoc…Uma ótima discussão no nanochat por @TheZachMueller

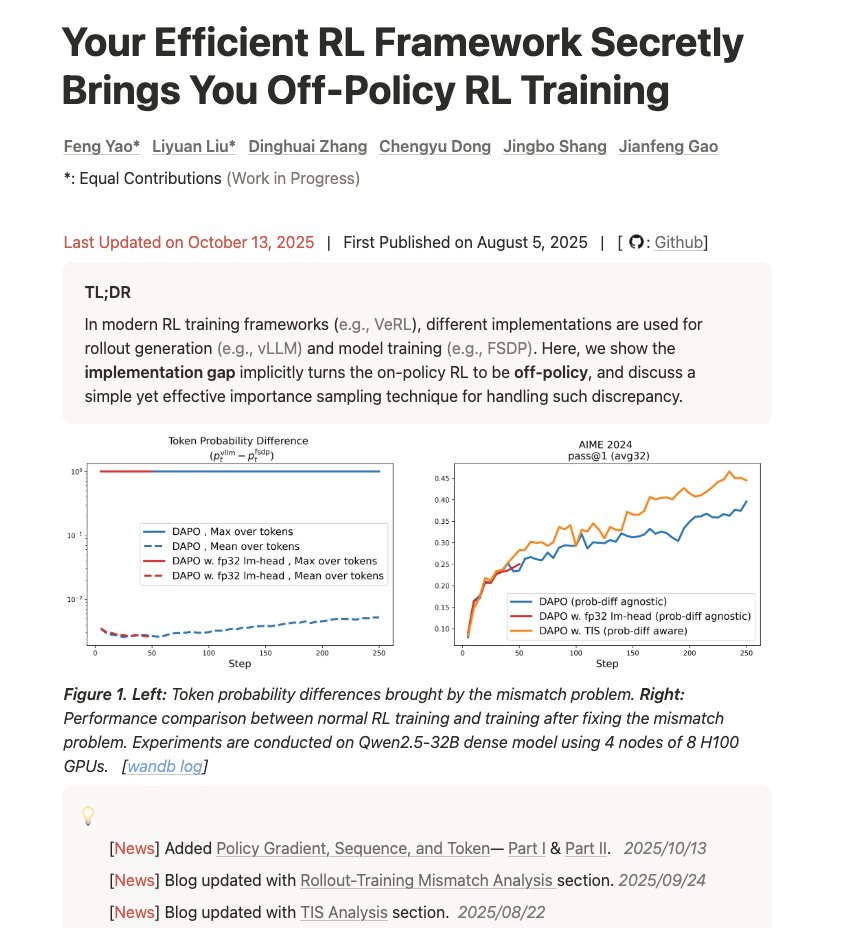
#6 - Sua estrutura de RL eficiente secretamente lhe proporciona treinamento em RL fora da política fengyao.notion.site/off-policy-rl#…Loq5UwZQ Um blog muito bom sobre como entender a discrepância entre treinamento e inferência e como isso afeta os resultados. “Sua infraestrutura está apresentando problemas matemáticos. Veja por quê, o quão ruim é e como corrigi-lo com amostragem por importância.”