Por que aceitamos aproximar a distribuição a partir de dados/modelo com KL progressivo (imagem à esquerda)? Por que não trabalhar em algoritmos que se pareçam com (imagem à direita)?
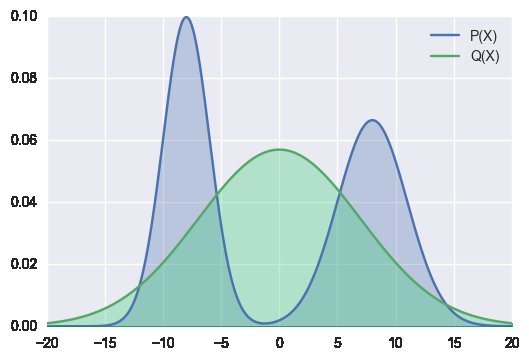

Ou será que já fazemos isso porque estamos minimizando o viés de Kullback-Leibler com maior ênfase na recência do que em toda a distribuição?