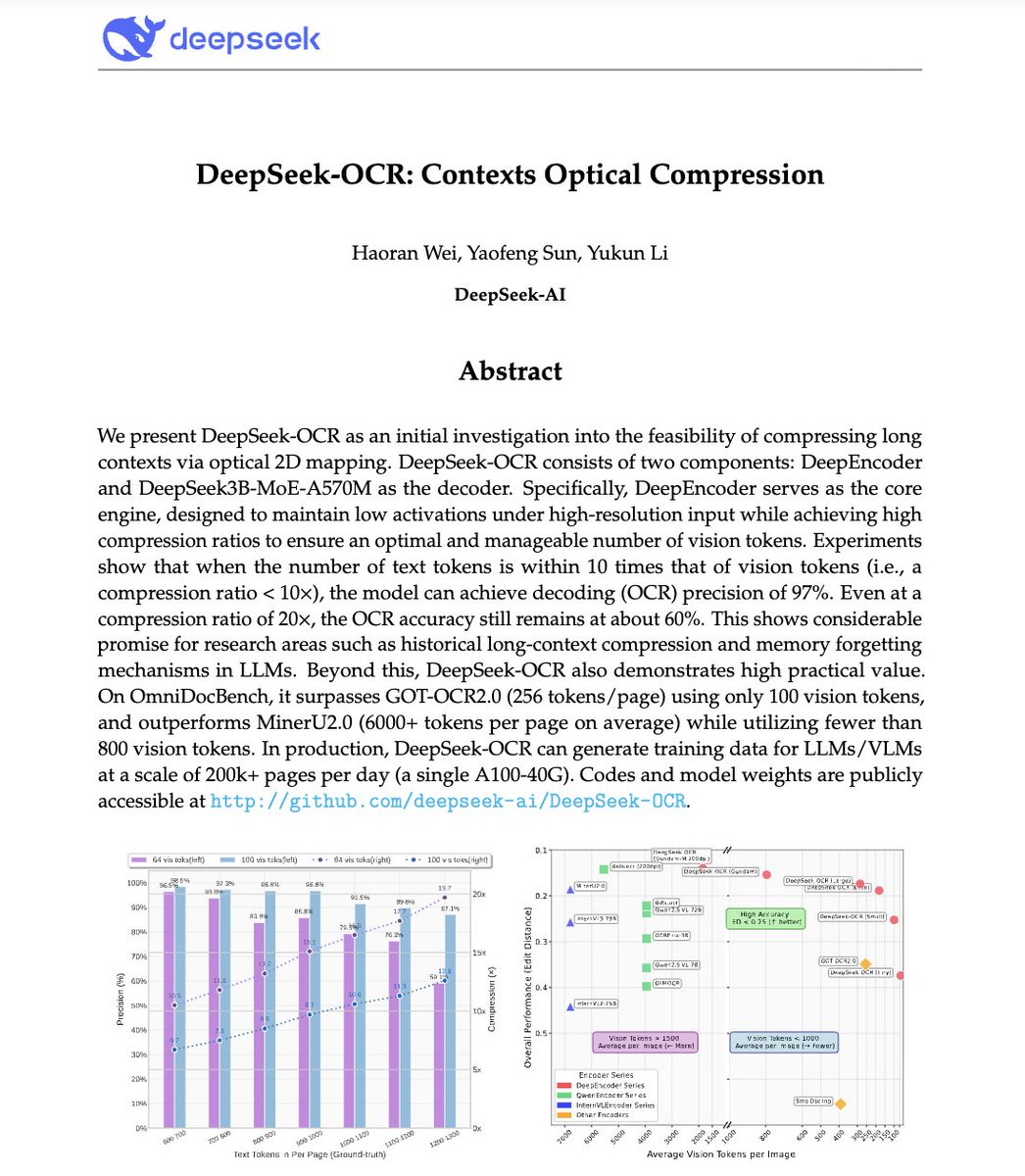
🚨 O DeepSeek acabou de fazer algo incrível. Eles criaram um sistema OCR que comprime textos longos em tokens de visão, literalmente transformando parágrafos em pixels. O modelo DeepSeek-OCR deles atinge 97% de precisão de decodificação com compressão de 10x e ainda consegue 60% de precisão mesmo com compressão de 20x. Isso significa que uma imagem pode representar documentos inteiros usando uma fração dos tokens que um LLM precisaria. Mais louco ainda? Ele supera o GOT-OCR2.0 e o MinerU2.0, usando até 60 vezes menos tokens e podendo processar mais de 200 mil páginas/dia em um único A100. Isso poderia resolver um dos maiores problemas da IA: a ineficiência de longo contexto. Em vez de pagar mais por sequências mais longas, os modelos poderão em breve ver o texto em vez de lê-lo. O futuro da compressão de contexto pode não ser textual. Pode ser óptico 👁️ GitHub. com/deepseek-ai/DeepSeek-OCR
1. Compressão de Visão e Texto: A Ideia Central Os LLMs têm dificuldades com documentos longos porque o uso de tokens aumenta quadraticamente com o comprimento. O DeepSeek-OCR inverte isso: em vez de ler texto, ele codifica documentos completos como tokens de visão, cada token representando uma parte compactada de informação visual. Resultado: você pode colocar 10 páginas de texto no mesmo orçamento de token necessário para processar 1 página no GPT-4.

2. DeepEncoder - O Compressor Óptico Conheça a estrela: DeepEncoder. Ele usa dois backbones, SAM (para percepção) e CLIP (para visão global), interligados por um compressor convolucional de 16×. Isso permite manter a compreensão em alta resolução sem explodir a memória de ativação. O codificador converte milhares de patches de imagem → algumas centenas de tokens de visão compactos.

3. Modo “Gundam” de multirresolução Documentos variam faturas ≠ plantas ≠ jornais. Para lidar com isso, o DeepSeek-OCR suporta vários modos de resolução: Tiny, Small, Base, Large e Gundam. O modo Gundam combina blocos locais + uma visão global com escala de 512×512 a 1280×1280 de forma eficiente. Um modelo, várias resoluções, sem retreinamento.

4. Mecanismo de dados OCR 1.0 a 2.0 Eles não treinaram apenas com varreduras de texto. Os dados do DeepSeek-OCR incluem: • Mais de 30 milhões de páginas em PDF em 100 idiomas • 10 milhões de amostras de OCR de cenas naturais • 10 milhões de gráficos + 5 milhões de fórmulas químicas + 1 milhão de problemas de geometria Não é apenas ler, é analisar diagramas científicos, equações e layouts.

5. Este não é “apenas mais um OCR”. É uma prova de conceito para compressão de contexto. Se o texto puder ser representado visualmente com 10 vezes menos tokens, os LLMs poderiam usar a mesma ideia para memória de longo prazo e raciocínio eficiente. Imagine o GPT-5 processando um documento de 1 milhão de tokens como um mapa de imagem de 100 mil tokens.

Pare de perder horas escrevendo prompts → Mais de 10.000 prompts prontos para uso → Crie o seu em segundos → Acesso vitalício. Pagamento único. Reivindique sua cópia 👇