Estou animado para lançar um novo repositório: nanochat! (está entre os mais desequilibrados que já escrevi). Ao contrário do meu repositório similar anterior, nanoGPT, que abordava apenas o pré-treinamento, o nanochat é um pipeline de treinamento/inferência full-stack mínimo, do zero, de um clone simples do ChatGPT em uma única base de código com dependências mínimas. Você inicializa uma GPU na nuvem, executa um único script e, em apenas 4 horas, pode conversar com seu próprio LLM em uma interface web semelhante ao ChatGPT. Ele ocupa cerca de 8.000 linhas de código, na minha opinião, bastante limpo para: - Treinar o tokenizador usando uma nova implementação Rust - Pré-treinar um LLM do Transformer no FineWeb, avaliar a pontuação CORE em uma série de métricas - Treinar conversas entre usuários e assistentes no SmolTalk, questões de múltipla escolha e uso de ferramentas. - SFT, avaliar o modelo de chat em múltipla escolha de conhecimento mundial (ARC-E/C, MMLU), matemática (GSM8K), código (HumanEval) - RL do modelo opcionalmente em GSM8K com "GRPO" - Inferência eficiente do modelo em um mecanismo com cache KV, pré-preenchimento/decodificação simples, uso de ferramentas (interpretador Python em um sandbox leve), comunicação via CLI ou WebUI semelhante ao ChatGPT. - Escrever um único boletim em Markdown, resumindo e gamificando tudo. Mesmo por um custo tão baixo quanto ~US$ 100 (~4 horas em um nó 8XH100), você pode treinar um pequeno clone do ChatGPT com o qual você pode conversar, escrever histórias/poemas e responder a perguntas simples. Cerca de ~12 horas superam a métrica GPT-2 CORE. À medida que você escala para ~$1.000 (~41,6 horas de treinamento), ele rapidamente se torna muito mais coerente e pode resolver problemas simples de matemática/código e realizar testes de múltipla escolha. Por exemplo, um modelo de profundidade 30 treinado por 24 horas (isso é aproximadamente igual aos FLOPs do GPT-3 Small 125M e 1/1000 do GPT-3) atinge 40s no MMLU e 70s no ARC-Easy, 20s no GSM8K, etc. Meu objetivo é reunir toda a pilha de "linha de base forte" em um repositório coeso, mínimo, legível, hackeavel e maximamente bifurcável. O nanochat será o projeto final do LLM101n (que ainda está em desenvolvimento). Acredito que ele também tem potencial para se tornar um recurso de pesquisa, ou um benchmark, semelhante ao nanoGPT anterior. Não está de forma alguma finalizado, ajustado ou otimizado (na verdade, acho que provavelmente há bastante trabalho pela frente), mas acho que está em um ponto em que o esqueleto geral está bom o suficiente para que possa ser publicado no GitHub, onde todas as partes podem ser aprimoradas. O link para o repositório e um passo a passo detalhado do nanochat speedrun estão na resposta.

Repositório Ggithub.com/karpathy/nanoc…3Dc44rY Um passo a passo muito mais detalhado e tgithub.com/karpathy/nanoc…HaZfNjcJ Exemplo de conversa com o nanochat de US$ 100, com duração de 4 horas, na WebUI. É... divertido :) Modelos maiores (por exemplo, uma profundidade de 26 em 12 horas ou uma profundidade de 30 em 24 horas) tornam-se rapidamente mais coerentes.

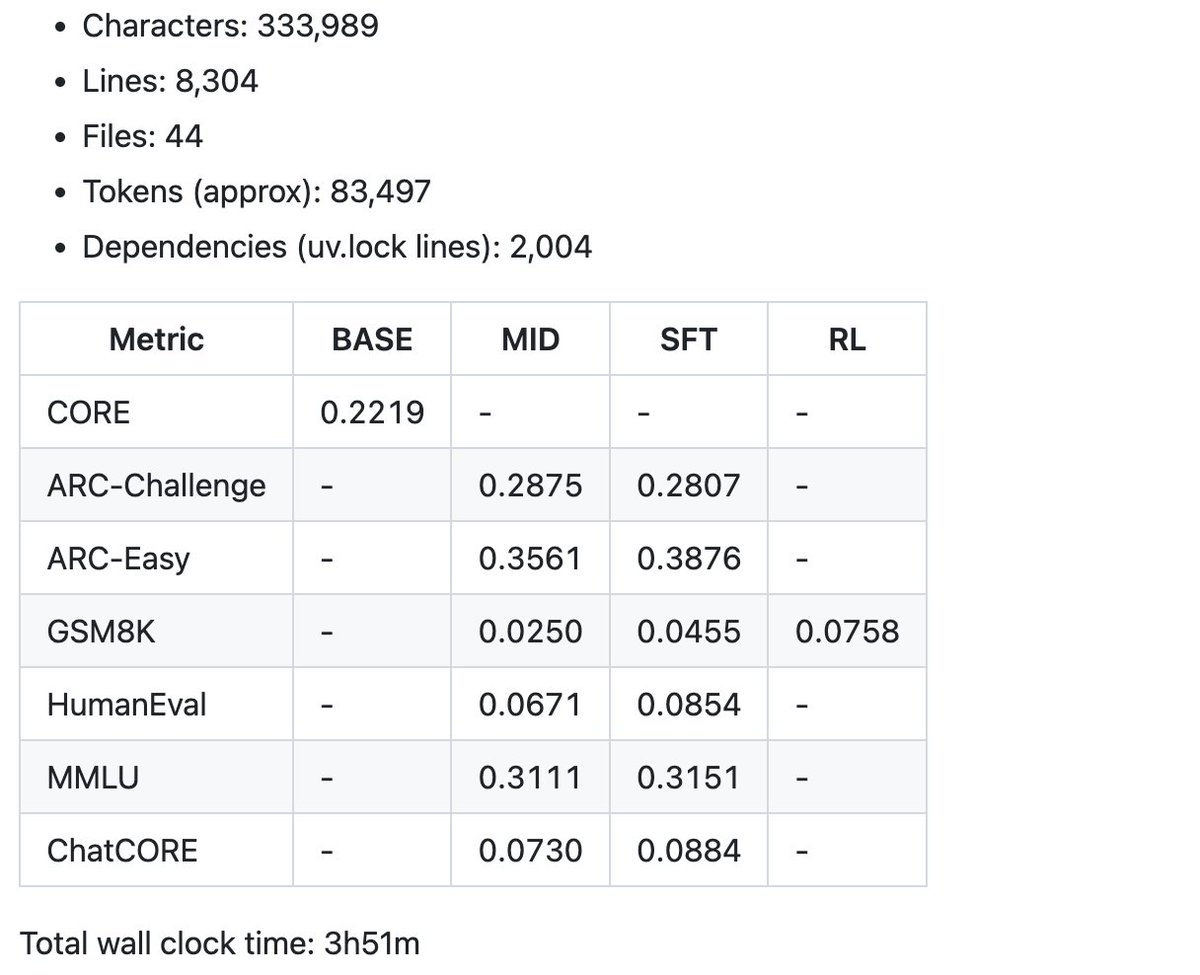
E um exemplo de algumas das métricas resumidas produzidas pelo speedrun de US$ 100 no boletim para começar. A base de código atual tem pouco mais de 8.000 linhas, mas tentei mantê-las limpas e bem comentadas. Agora vem a parte divertida — o ajuste e a escalada.