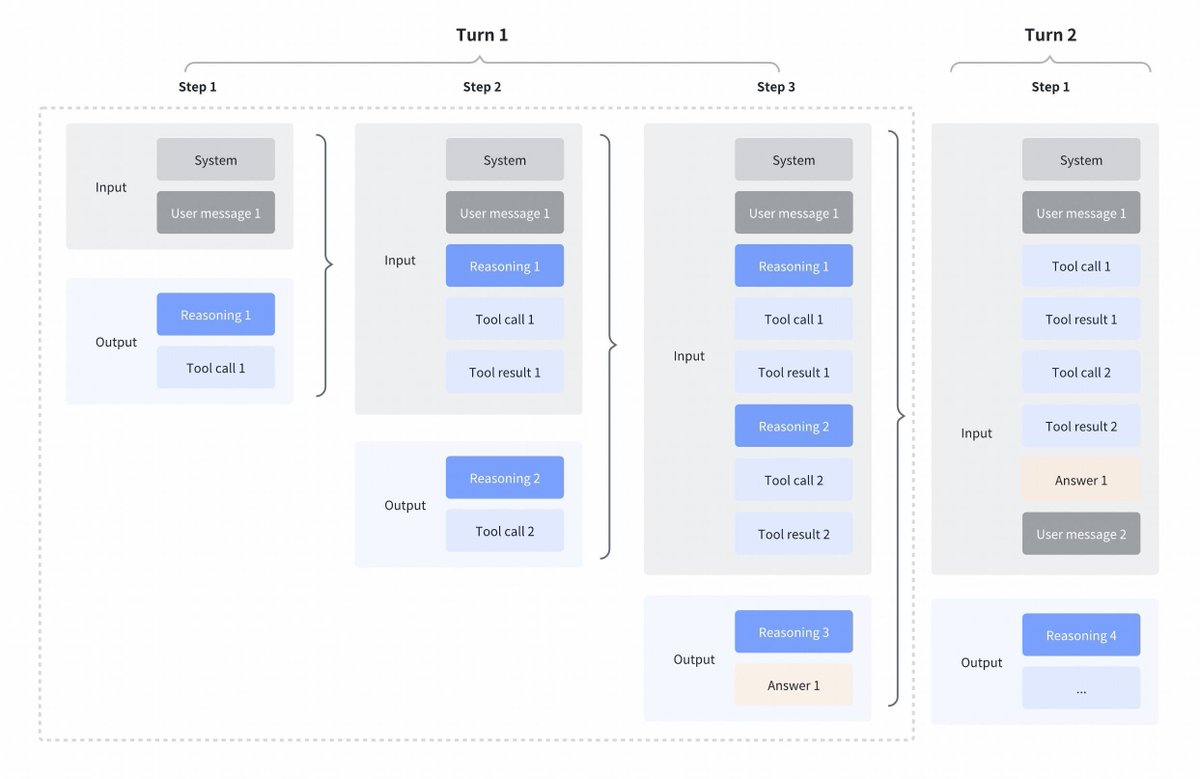
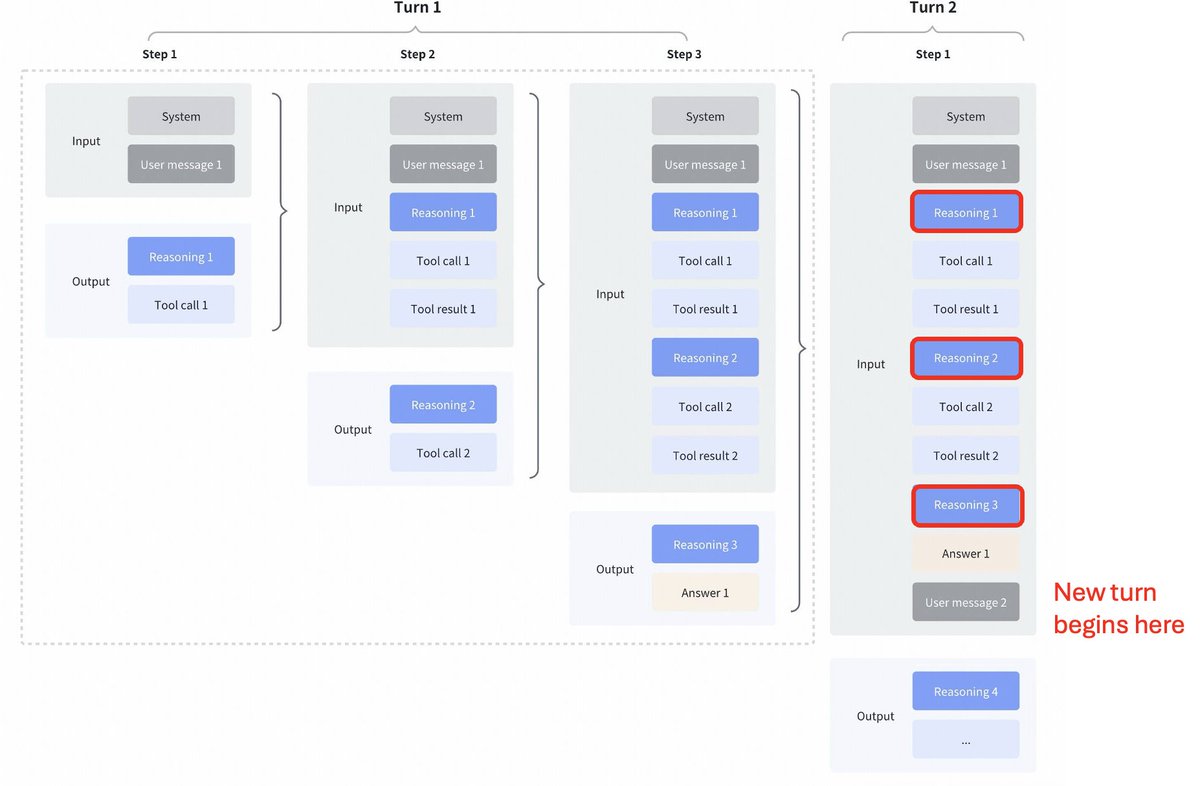
GLM4.7의 전략 변화가 흥미롭네요. Kimi K2 Thinking, DeepSeek V3.2 및 MiniMax M2.1과 비교 도구 호출 사이에 생각을 교차적으로 진행함: 이 모든 모델은 도구 호출에 대한 교차 사고를 지원했지만, 아래 첫 번째 스크린샷에서 볼 수 있듯이 이전 단계에서의 사고를 명확히 했습니다. GLM 4.7에서 보존된 사고 방식: 아래 스크린샷(빨간색 블록 참조)에서 볼 수 있듯이 GLM 4.7(코딩 엔드포인트만 해당)은 이전 턴의 추론을 유지합니다. 다른 API 엔드포인트의 동작은 이전과 동일합니다(이전 설명은 무시하세요). 이렇게 하면 모델이 이전 컨텍스트를 갖게 되므로 성능이 확실히 향상될 것입니다. @peakji 님의 조언처럼 모델은 나중에 좋은 결정을 내리기 위해 과거의 사고 과정이 필요합니다. 이는 문맥 압축과는 반대되는 개념이지만, 코딩 시나리오에서는 충분히 가치 있을 수도 있습니다. 설정을 변경할 수 있게 해줬으면 좋겠어요. 그러면 우리가 직접 그 영향을 확인할 수 있을 텐데요.