Zhipu AI, GLM-4.7에 3단계 사고 모드 도입 GLM-4.7은 답변을 생성하기 전에 자동으로 내부 추론을 수행합니다. 과제 목표를 분석하고, 추론 과정을 수립하고, 잠재적 장애물을 예측하고, 최종적으로 가시적인 결과물을 생성합니다. 또한 여러 차례의 대화 과정에서 "이전의 사고 과정을 기억"할 수도 있습니다. 사용자는 또한 "사고의 강도를 조절"할 수 있습니다. 동시에 코딩과 프런트엔드 디자인을 크게 개선하며, 성능은 GPT-5 및 Claude 4.5에 근접합니다. 이전에는 GLM-4.7로 생성된 웹 페이지가 "개발자 작업물"과 유사했지만, 이제는 "디자이너 작업물"과 유사합니다. 깔끔하고 현대적인 웹 페이지를 생성하고, 아름답게 구성된 슬라이드쇼와 포스터를 만들 수 있습니다. 레이아웃, 색상 및 텍스트 비율을 자동으로 제어하여 시각적 일관성을 유지합니다. 아래는 GLM-4.7로 생성된 PPT입니다.

GLM-4.7은 생성된 콘텐츠의 **시각적 일관성**을 크게 최적화했습니다. 레이아웃과 비율이 개선된 구조화된 HTML, CSS 및 JavaScript 코드 슬라이드를 자동으로 생성하여 현대적인 스타일과 사용성을 갖춘 웹 페이지를 만들 수 있습니다.
GLM-4.7로 디자인된 웹사이트 ↓

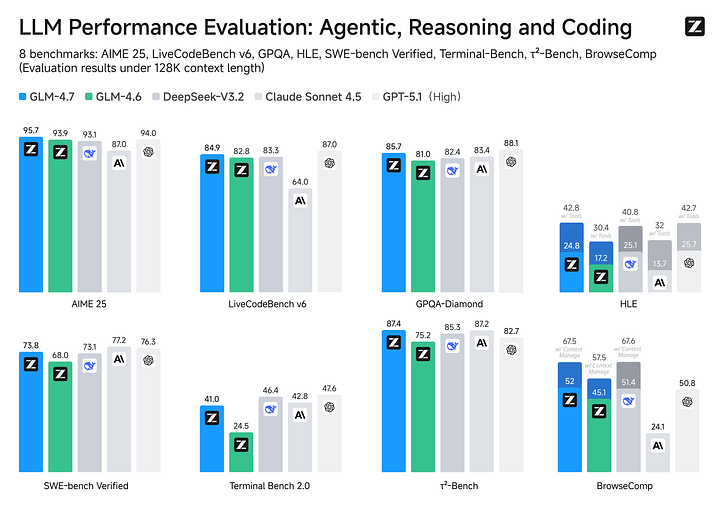
"행동하기 전에 생각하라"는 추론 모델 덕분에 GLM-4.7은 코딩 기능이 크게 향상되었으며, 작업 완료율이 이전 버전보다 10%~15% 크게 높아졌습니다. 프로그래밍 작업 수행 능력은 클로드 4.5 수준의 90%에 도달하며, 시각 및 웹 페이지 생성 능력은 클로드 4.5 수준 이상입니다. 이는 "코드 생성 + 사고 메커니즘 + 시각적 출력" 측면에서 장점이 있습니다.
GLM-4.7의 전반적인 성능은 GPT-5와 Claude 4.5 사이에 있습니다. 수학적 논리 능력은 GPT-5에 근접하며 Claude 4.5보다 우수합니다. 추론 능력 측면에서 GLM-4.7은 평균적으로 GPT-5 시리즈보다 약간 떨어지지만 Claude Sonnet 4.5 및 Kimi K2보다는 우수한 성능을 보입니다. GLM-4.7은 온라인 검색이나 외부 API 호출과 같은 도구를 적극적으로 사용할 수 있습니다. 이 알고리즘은 τ²-Bench에서 87.4%의 성능을 달성하여 GPT-5(82.7%)를 능가합니다.
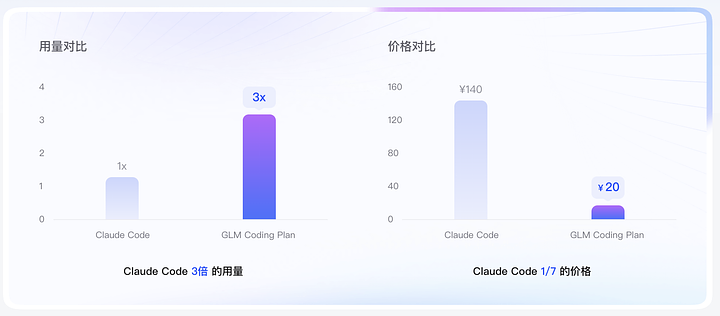
온라인에서z.aiAfaqxyMkip 가격에 관하여: GLM 코딩 플랜 사용자는 GLM-4.7로 자동 업그레이드됩니다. 클로드 코드 모델과 비교했을 때: 비용은 원래 비용의 7분의 1입니다. 프로그래밍 작업량의 세 배에 달하는 할당량을 사용했을 때, 성과는 클로드의 수준의 90%에 도달했습니다. 가격 대비 성능이 뛰어난 제품입니다.
자세한 소xiaohu.ai/c/a066c4/ai-gl…hMl 모델 다운로huggingface.co/zai-org/GLM-4.7CEr Gitgithub.com/zai-org/GLM-4.5cjYYc docs.bigmodel.cn/cn/guide/model…6U7WxNrW