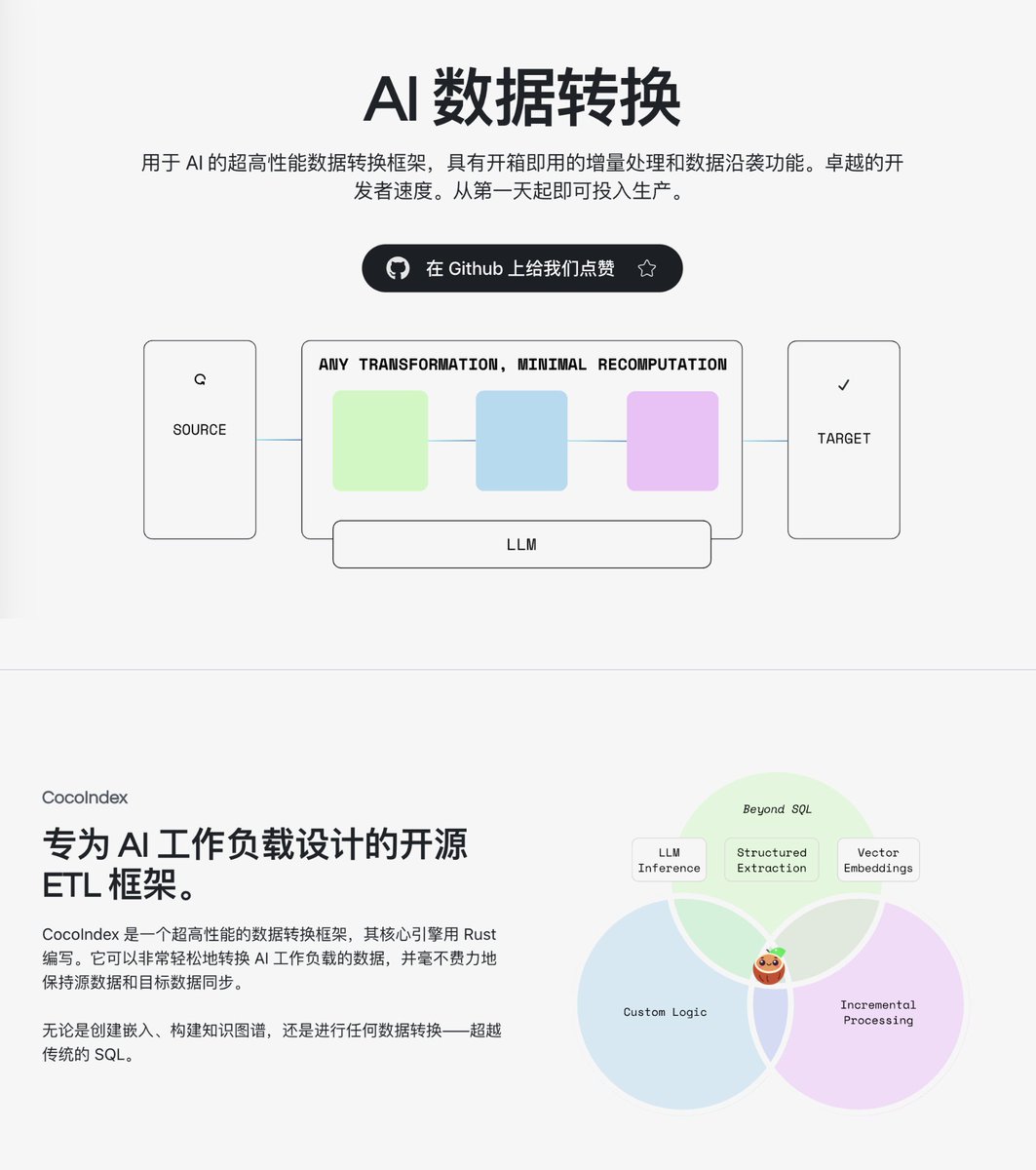
RAG 애플리케이션을 개발하거나 지식 기반을 구축할 때 가장 어려운 부분은 모델 선택이 아니라 데이터 처리 파이프라인인 경우가 많습니다. 데이터를 정리하고, 분할하고, 벡터화하려면 여러 개의 파이썬 스크립트를 작성해야 하며, 원본 데이터가 변경될 경우 전체 프로세스를 다시 실행하는 것은 시간과 비용이 많이 소요됩니다. 최근 GitHub에서 AI 시나리오에 특화된 고성능 데이터 변환 프레임워크인 CocoIndex 오픈소스 프로젝트를 접하게 되었습니다. 약 100줄의 파이썬 코드만으로 파일 읽기 및 청킹부터 라이브러리에 벡터 삽입에 이르기까지 전체 프로세스를 정의할 수 있습니다. GitHub: https://t.co/RwUjyHJEym 이 서비스는 로컬 파일, Amazon S3, Google Drive, Postgres, Qdrant, LanceDB와 같은 벡터 데이터베이스를 포함하여 다양한 데이터 소스와 대상을 지원합니다. 또한 텍스트 분할, 임베딩 생성, PDF 구문 분석 및 지식 그래프 구축과 같은 일반적으로 사용되는 변환 구성 요소도 포함되어 있습니다. 이 책은 시맨틱 검색, 지식 그래프, 제품 추천, 이미지 검색 등 20개 이상의 실제 응용 시나리오를 다루는 풍부한 예시를 제공하며, 이러한 예시들은 직접 참조하고 활용할 수 있습니다.