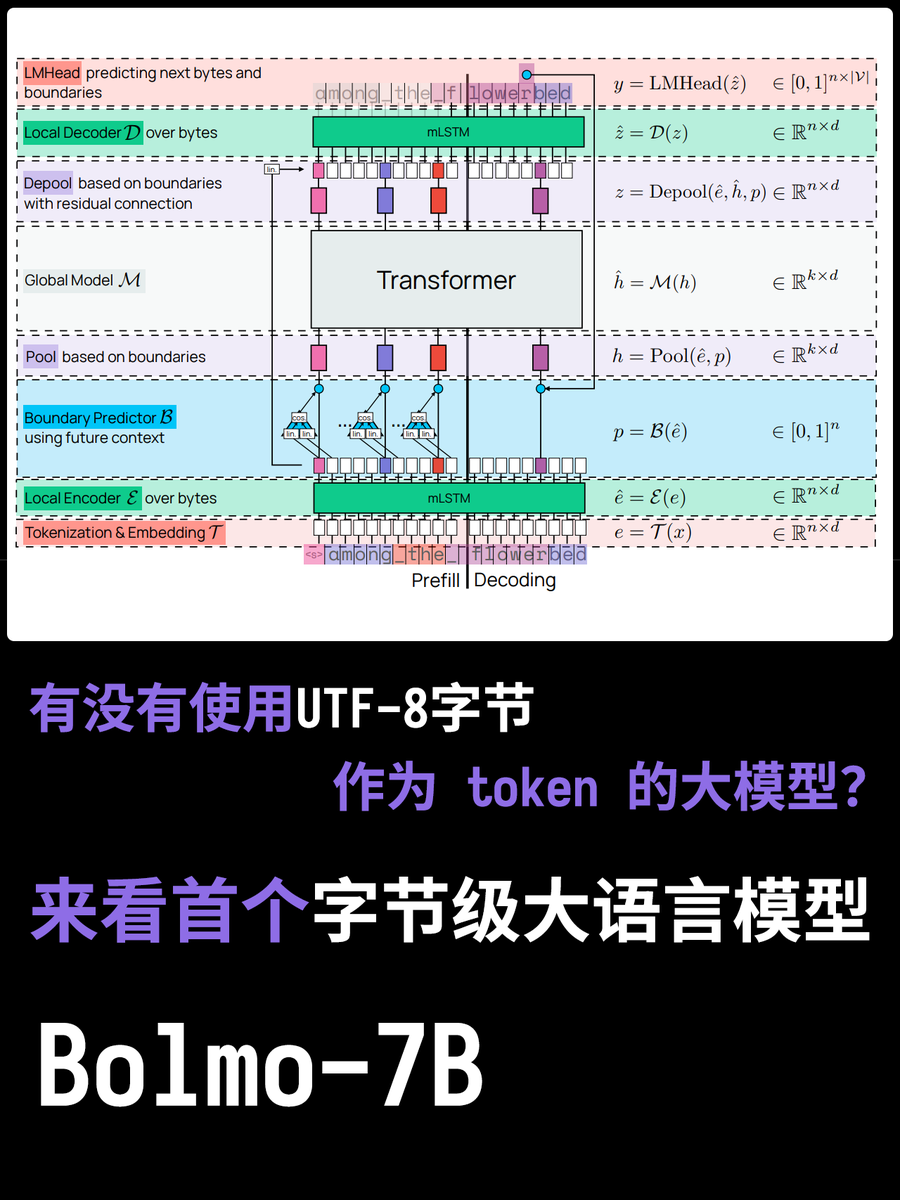
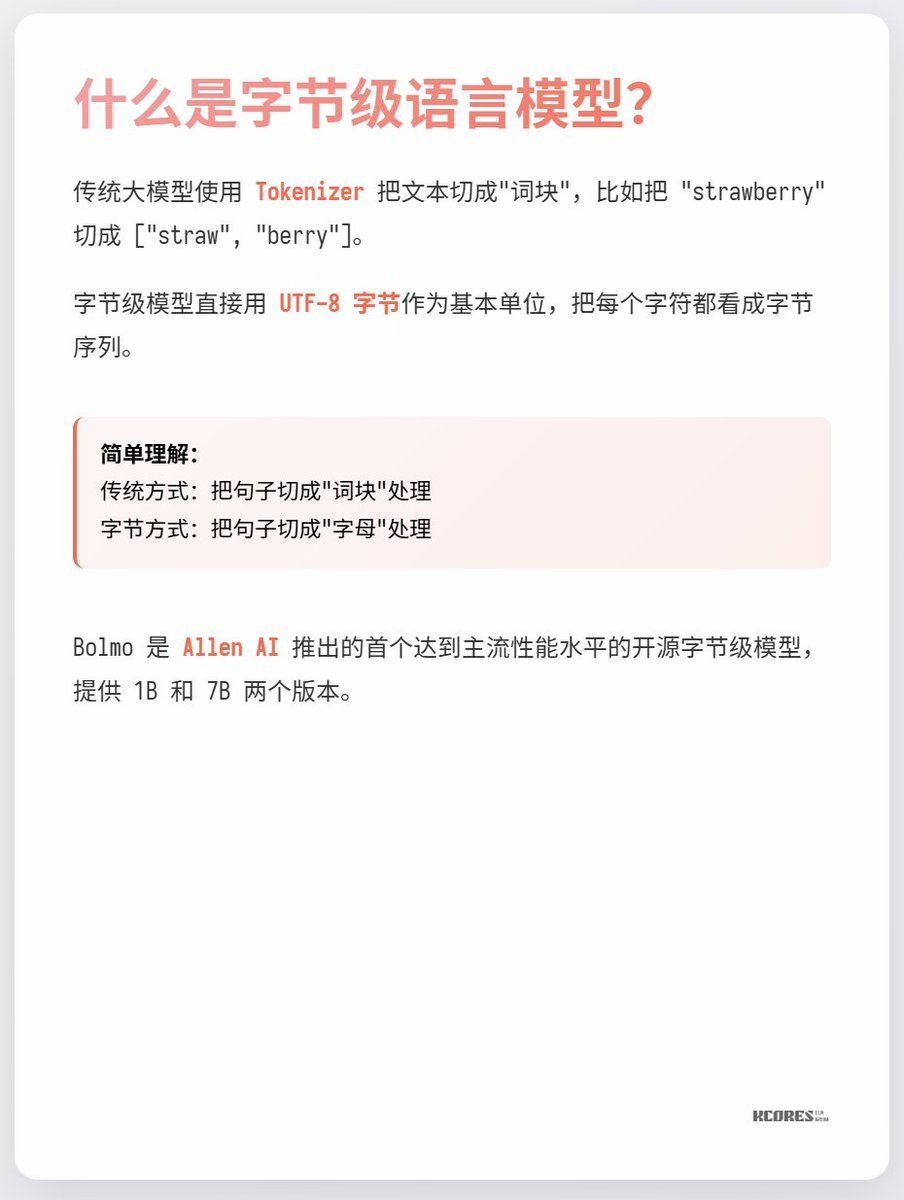
대규모 모델에는 토크나이저가 있다는 것은 누구나 알고 있습니다. 토크나이저는 모델에서 사용하는 단어 분할 테이블을 기록하며, 의미를 이해하고 계산을 수행하는 데 있어 가장 작은 단위입니다. 하지만 단어 분할이 왜 필요한지 생각해 본 적이 있나요? UTF-8 인코딩을 사용하여 토큰을 직접 입력하는 것이 더 효율적이지 않을까요? 오늘 소개할 새로운 모델인 Bolmo-8B를 살펴보겠습니다. 이 모델은 기존 방식을 완전히 버리고 UTF-8 바이트를 기본 단위로 사용하여 각 문자를 바이트 시퀀스로 처리합니다.
이렇게 하는 가장 큰 장점은 "Strawberry에는 'r'이 몇 개 있을까요?"와 같은 질문에 쉽게 답할 수 있다는 것입니다! UTF-8에서는 각 문자가 독립적으로 인코딩되기 때문입니다. 하지만 이로 인해 발생하는 문제점 또한 매우 현실적입니다. 단어는 매우 복잡할 수도 있고, 매우 단순할 수도 있습니다. 기존 토크나이저는 이러한 문제를 어느 정도 해결할 수 있지만, UTF-8을 사용할 경우 각 단어에 단어 길이만큼의 토큰을 할당해야 하므로 컴퓨팅 자원 할당이 매우 비효율적입니다.



볼모의 모델은 독창적인 접근 방식을 취합니다. 처음부터 학습하는 대신 기존 모델을 "바이트 인코딩"하는 것입니다. 내장된 로컬 인코더/디코더는 바이트 시퀀스를 "잠재적 토큰"으로 압축한 후 기존 트랜스포머에 입력하여 처리합니다. 이를 통해 최소한의 오버헤드로 변환이 가능합니다.

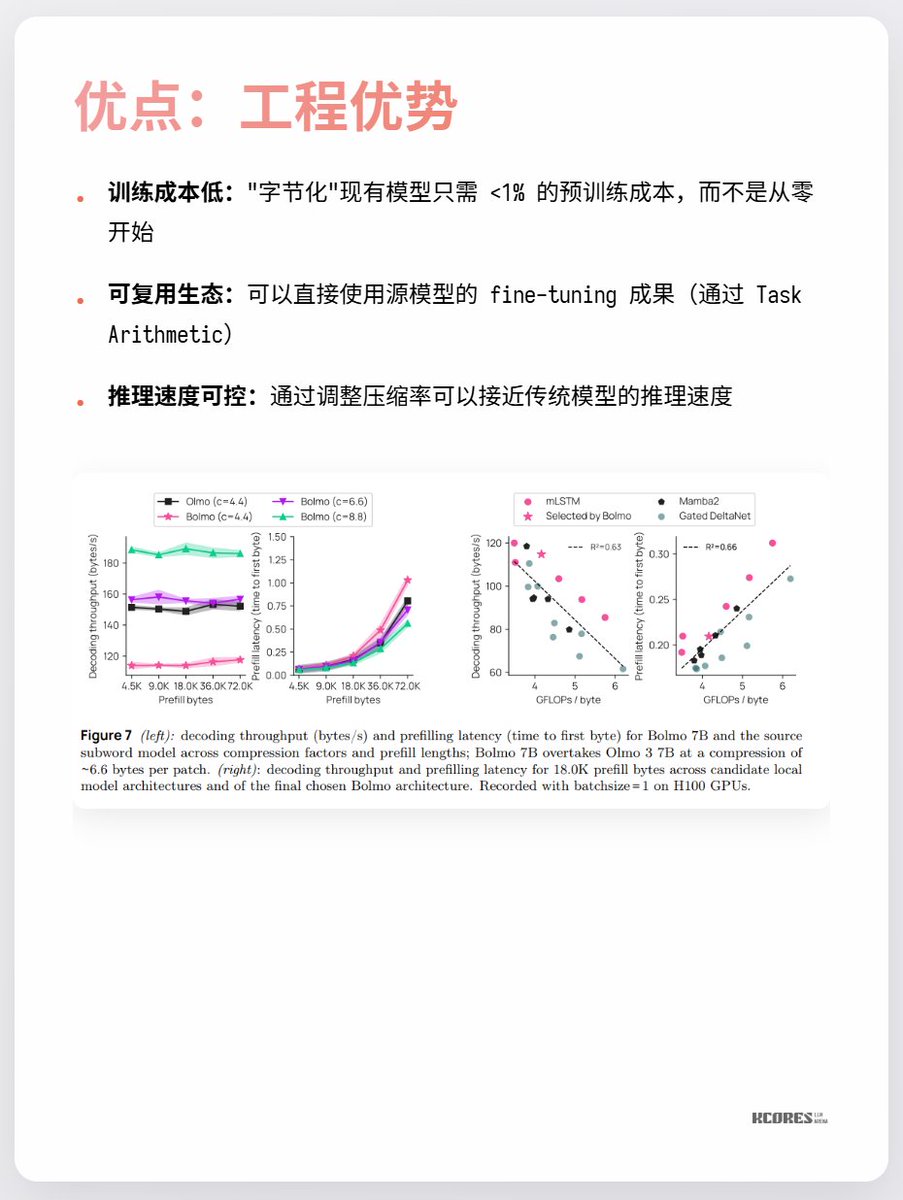

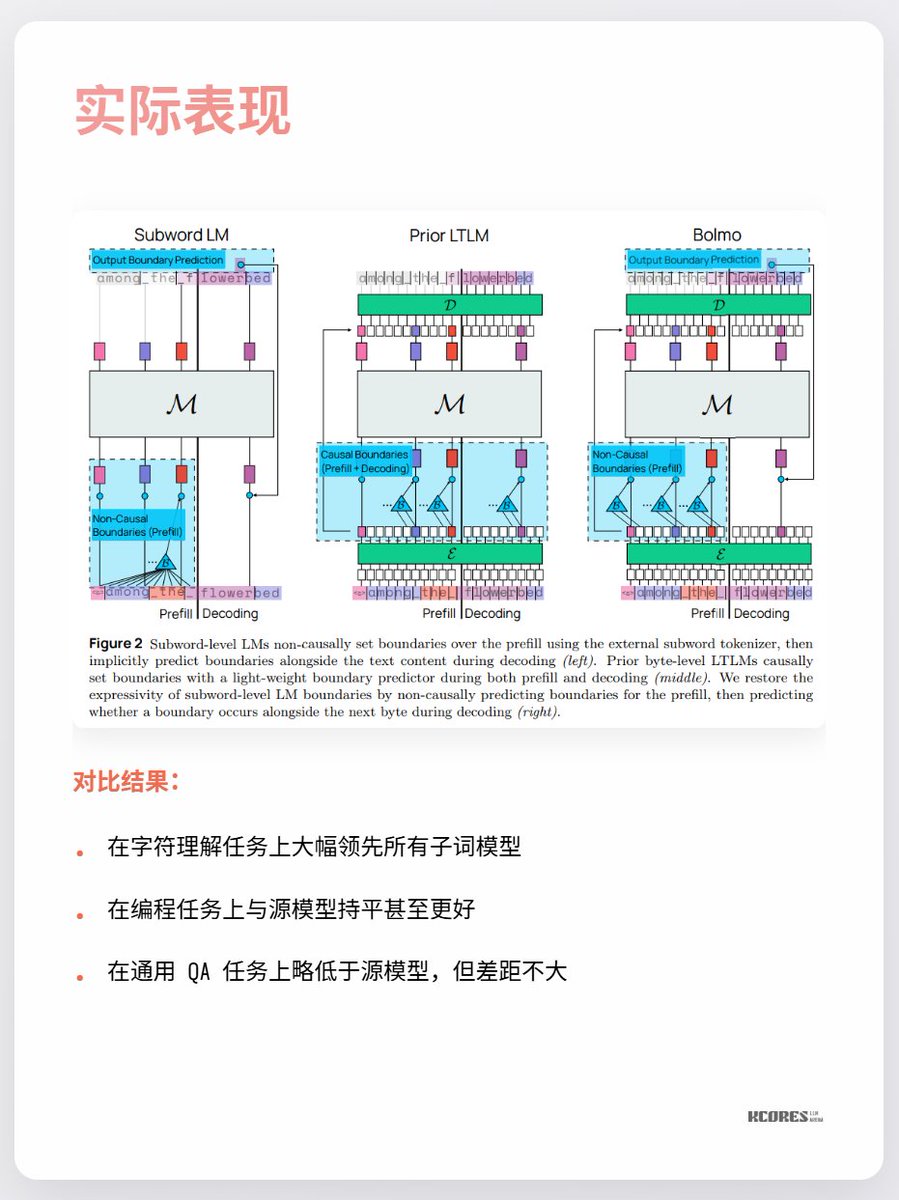
현재 가장 큰 논쟁거리는 눈에 띄는 이점이 거의 없다는 점과, 시퀀스 길이가 길어질수록 키-값 캐시 용량이 늘어나 GPU 메모리에 부담이 가중된다는 점입니다. 또한, 상당한 성능 향상은 문자 인식이라는 단일 작업에서만 나타나고, 다른 작업에서는 눈에 띄는 개선이 거의 없습니다. 요컨대, 주목할 만한 가치가 있습니다. 기술적 혁신 시기에 나타나는 나선형 탐구는 언제나 매우 흥미롭습니다. 예를 들어, 저는 개인적으로 수은 정류기(마지막 사진)를 좋아했지만, 지금은 IGBT로 대체되었습니다.

