NVIDIA는 GPT-OSS-120B 전용으로 설계된 가속 모델을 방금 출시했습니다. NVIDIA는 gpt-oss-120b와 함께 작동하도록 특별히 설계된 새로운 모델인 gpt-oss-120b-Eagle3-throughput를 출시했습니다. 이 모델은 gpt-oss-120b의 투기적 디코딩을 위한 사전 모델로 사용될 수 있으며, 이를 통해 gpt-oss-120b 모델의 출력 속도를 향상시킬 수 있습니다. 추측 디코딩에 익숙하지 않은 분들을 위해 설명드리자면, 이는 작은 모델을 사용하여 데이터를 출력한 다음, 이러한 출력을 일괄적으로 더 큰 모델에 입력하여 오류를 수정하는 방식입니다. 이렇게 하면 작은 모델이 "정확하게 예측"할 경우 처리 속도가 매우 빨라집니다. 또한, 일반적인 문맥에서는 불용어(언어에서 사용 빈도는 매우 높지만 문장의 핵심 의미를 구분하는 데 거의 기여하지 않는 단어)가 여전히 많이 존재합니다. 따라서 속도 향상은 매우 중요합니다.

모델 정보 / 1




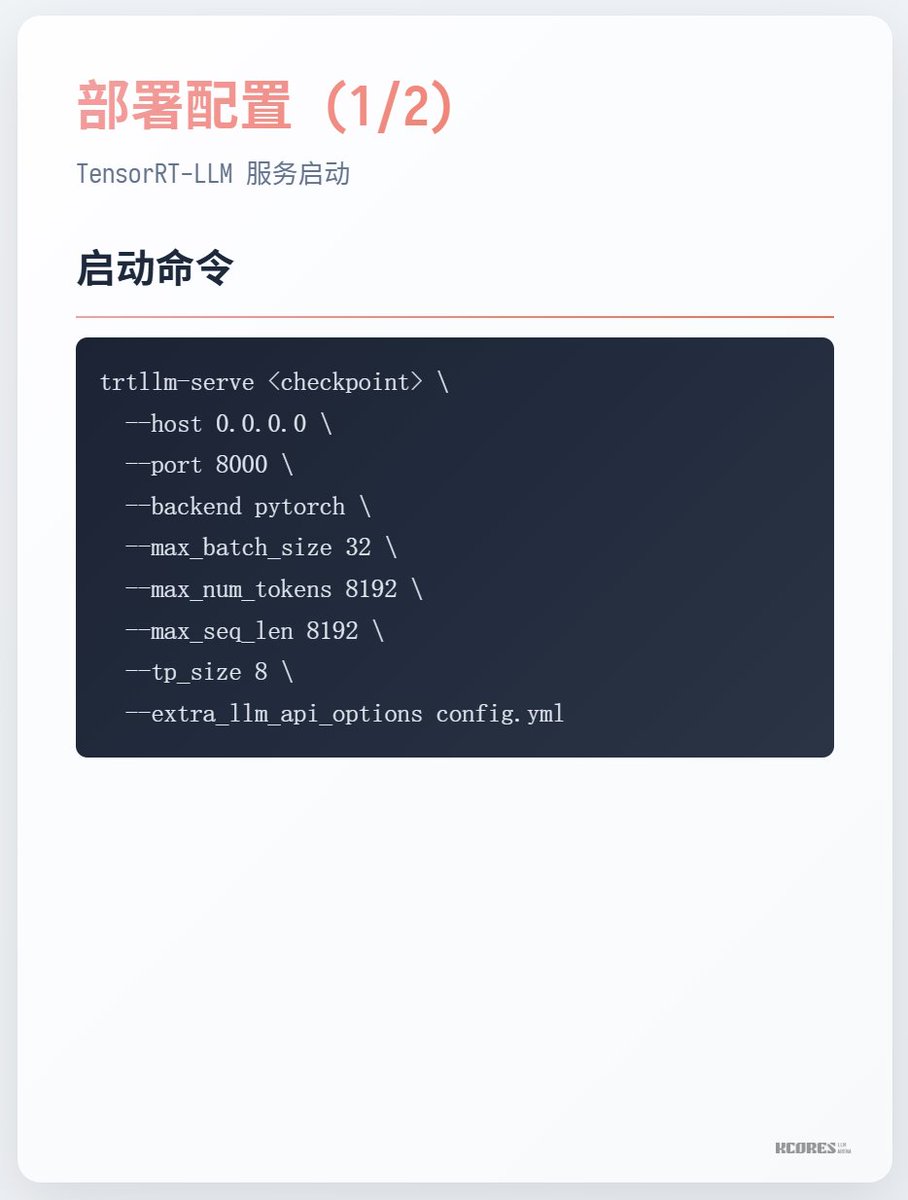
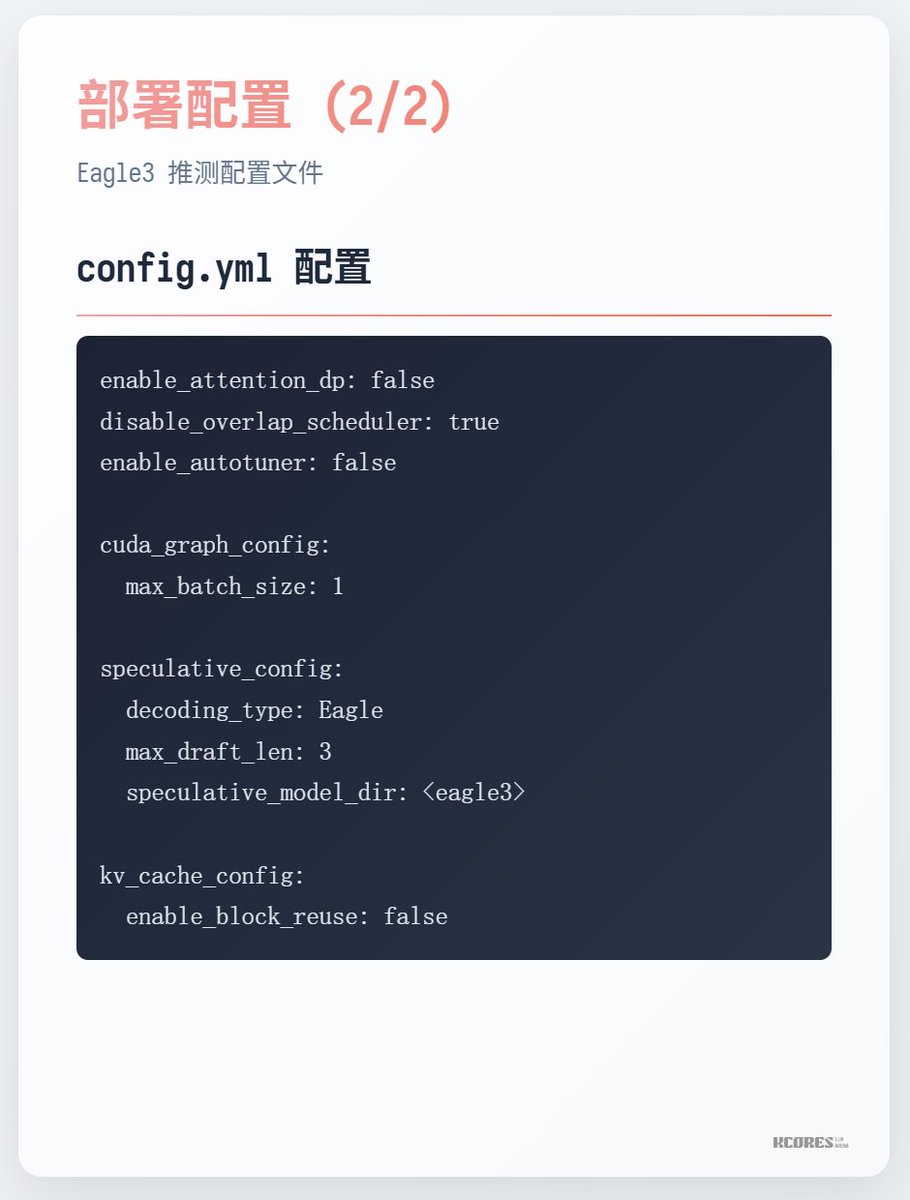
실행 방법