구글, 새로운 제미니 2.5 플래시 네이티브 오디오 모델 출시 다양한 실시간 음성 애플리케이션을 구동하는 데 사용됩니다. "네이티브 오디오"란 모델이 텍스트를 먼저 생성한 다음 음성을 합성하는 방식이 아니라, 자연스러운 음성 출력을 직접 생성할 수 있는 기능을 의미합니다. 이 기기는 "사용자의 말을 이해할 뿐만 아니라" 더욱 자연스러운 어조, 리듬, 그리고 멈춤을 사용하여 "사람의 목소리로 즉시 응답"할 수 있습니다. 세 가지 핵심 역량이 종합적으로 강화되었습니다. 1️⃣ 더욱 스마트해진 "함수 호출" 이제 Gemini는 음성 대화 중에 다음과 같은 외부 정보 소스에 능동적으로 접근할 수 있습니다. 날씨 API를 호출합니다. 데이터베이스를 조회합니다. 실시간 뉴스 또는 주식 정보를 받아보세요. 단순히 "답변"하는 것뿐만 아니라, 대화 도중 언제 정보를 찾아보고 언제 대화를 계속할지 판단할 수 있으며, "말하는 동안 정보를 검색"하여 원활한 음성 흐름을 유지할 수 있습니다.
2️⃣ 향상된 지시 이해도 Gemini 2.5 플래시 네이티브 오디오는 복잡한 음성 지시를 이해하는 데 더 정확합니다. Google 테스트 데이터에 따르면 다음과 같습니다. 지시사항 준수율이 84%에서 90%로 증가했습니다. 출력 콘텐츠의 완전성과 정확성이 크게 향상되었습니다. 3️⃣ 대화 유창성 향상 Gemini 2.5 Flash Native Audio는 여러 대화의 맥락을 기억하여 음성 전환을 더욱 자연스럽게 만듭니다.
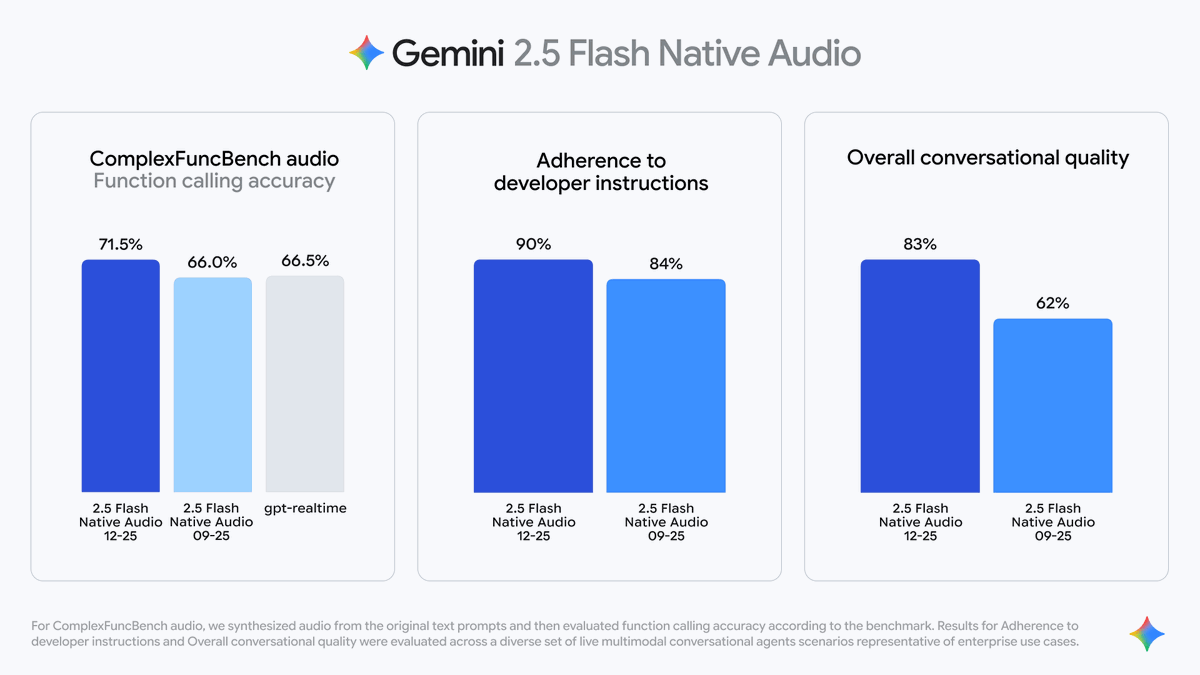
Gemini 2.5 플래시 네이티브 오디오 모델이 이제 Vertex AI에서 완전히 사용 가능하며 Gemini API(미리 보기)에서도 사용할 수 있습니xiaohu.ai/c/xiaohu-ai/go…co/CnBlan3RBh