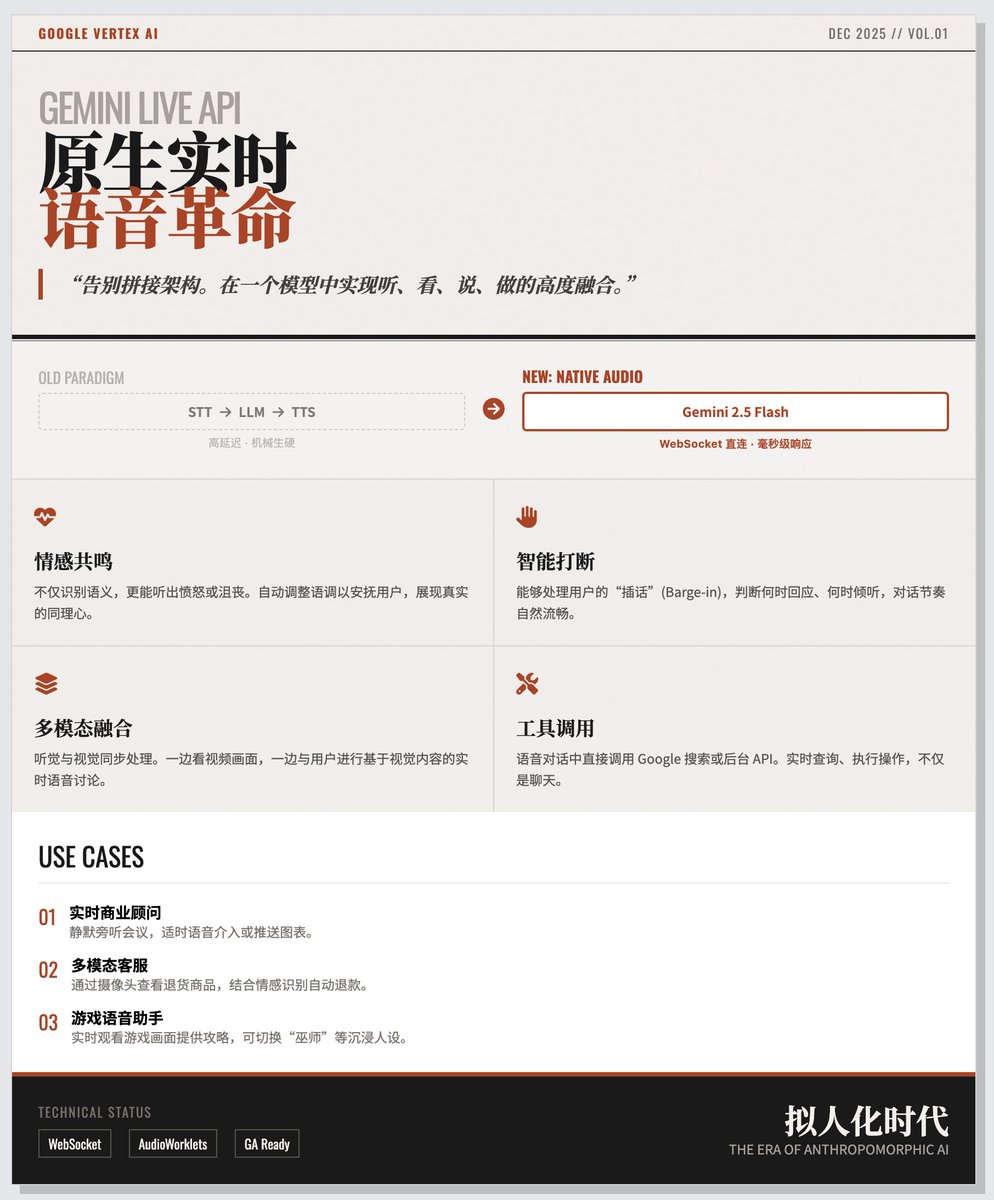
구글은 최신 Gemini 2.5 플래시 네이티브 오디오 모델을 기반으로 하는 Gemini Live API를 공식 출시했습니다. 개발자는 더 이상 복잡한 음성 처리 연결 고리를 힘들게 조립할 필요 없이, 단일 모델 내에서 듣기, 보기, 말하기, 행동하기를 고도로 통합할 수 있습니다. 핵심 혁신: "높은 지연 시간"을 수반하는 어셈블리 방식에 작별을 고하고 "네이티브" 실시간 통신을 도입하세요. 음성 대화 AI를 구축하는 데는 일반적으로 STT -> LLM -> TTS의 세 단계가 필요합니다. 이 과정은 지연 시간이 길 뿐만 아니라 대화가 기계적이고 딱딱하게 들리게 합니다. Gemini Live API의 획기적인 특징은 다음과 같습니다. • 네이티브 오디오 처리: Gemini 2.5 플래시 모델은 원본 오디오를 직접 "듣고" 이해하여 오디오 응답을 직접 생성할 수 있습니다. • 극도로 낮은 지연 시간: 중간 변환 단계를 제거하고 단일 WebSocket 연결을 통해 밀리초 수준의 실시간 응답을 구현합니다. • 멀티모달 융합: 이 모델은 음성뿐만 아니라 비디오 스트림, 텍스트 및 시각 정보를 동시에 처리할 수 있습니다. 예를 들어, 사용자는 AI와 음성 대화를 나누면서 비디오 영상을 보여줄 수 있습니다. "인간과 유사한 5가지 핵심 기능"이라는 제목의 이 블로그 게시물은 이 API가 인공지능을 단순한 질문과 답변 기계가 아닌 실제 사람과 더욱 유사하게 만드는 방법을 강조합니다. • 감정적 공감: 이 모델은 화자의 어조, 속도, 감정(예: 분노, 좌절)을 감지하고 사용자를 진정시키거나 공감을 표현하기 위해 자동으로 자신의 어조를 조절합니다. • 지능형 개입 및 경청: 단순 음성 인식을 넘어, AI는 언제 응답하고 언제 침묵해야 하는지 판단하며, 사용자의 개입까지 처리하여 더욱 자연스러운 대화 흐름을 만들어냅니다. • 도구 호출: 음성 대화 중 AI는 실시간으로 외부 도구를 호출하거나 Google 검색을 사용하여 최신 정보를 얻을 수 있습니다. • 지속적 기억: 다중 모드 상호작용에서 맥락적 일관성 유지. • 엔터프라이즈급 안정성: GA 버전으로서, 프로덕션 환경에 필요한 고가용성과 다중 지역 지원을 제공합니다. 개발 및 배포: 템플릿부터 실제 애플리케이션까지 개발자가 빠르게 시작할 수 있도록 Google은 두 가지 빠른 시작 템플릿과 세 가지 대표적인 애플리케이션 시나리오 데모를 제공합니다. 개발 템플릿: 바닐라 자바스크립트 템플릿: 종속성이 전혀 없으며, 웹소켓 프로토콜과 미디어 스트리밍의 기본 원리를 이해하는 데 적합합니다. • React 템플릿: 복잡한 엔터프라이즈 애플리케이션 구축에 적합한 오디오 처리 워크플로우를 갖춘 모듈식 디자인. 세 가지 주요 실제 시나리오: 1. 실시간 비즈니스 자문: 주요 특징: "무음 모드"와 "음성 모드"를 제공합니다. AI는 마치 부기장처럼 회의 내용을 청취하면서 화면에 차트 정보만 표시하여 시청자를 방해하지 않거나, 필요할 때 음성으로 제안을 제공할 수 있습니다. 2. 복합 운송 고객 서비스: 주요 특징: 사용자는 카메라를 통해 문제가 있는 제품(예: 반품 상품)을 직접 보여줄 수 있습니다. AI는 시각적 판단과 음성 감정 인식을 결합하여 환불 처리를 위한 백엔드 도구를 직접 호출합니다. 3. 게임 음성 비서: 주요 특징: AI가 플레이어의 게임 플레이를 실시간으로 모니터링하고 전략 가이드를 제공합니다. 사용자는 AI의 "페르소나"(예: 현명한 마법사 또는 공상 과학 로봇)를 변경하여 AI를 단순한 지휘관이 아닌 게임 파트너로 활용할 수 있습니다. 구글 공식 블로그