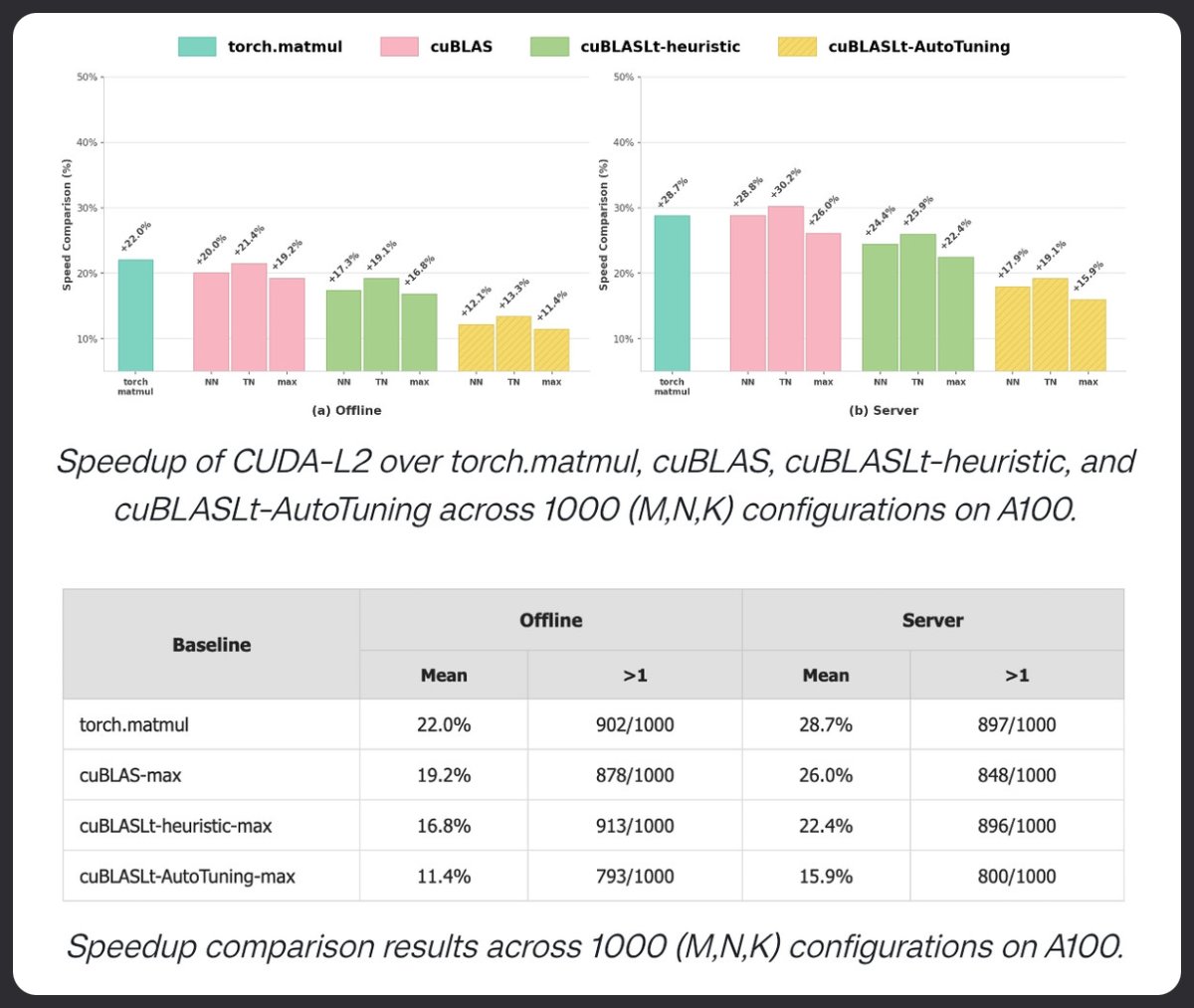
CUDA-L2는 강화 학습을 사용하여 행렬 곱셈에서 cuBLAS보다 뛰어난 성능을 보여줍니다. 1000가지 HGEMM 구성에서 테스트한 결과, A100에서 torch.matmul, cuBLAS 및 cuBLASLT AutoTuning보다 우수한 성능을 보였습니다. 오프라인 모드에서 22% 향상됩니다. 서버 모드에서 +28.7% 증가. LLM은 현재 커널을 튜닝하고 있습니다.
📄 논문: htarxiv.org/pdf/2512.02551🔗 GitHub: github.com/deepreinforce-…