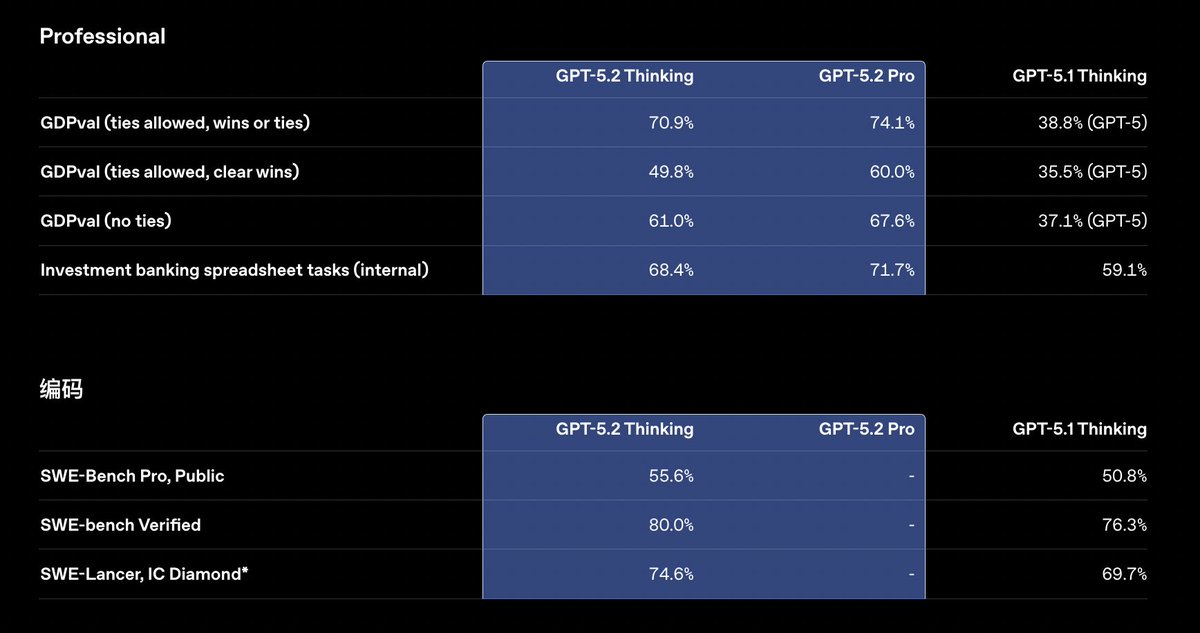
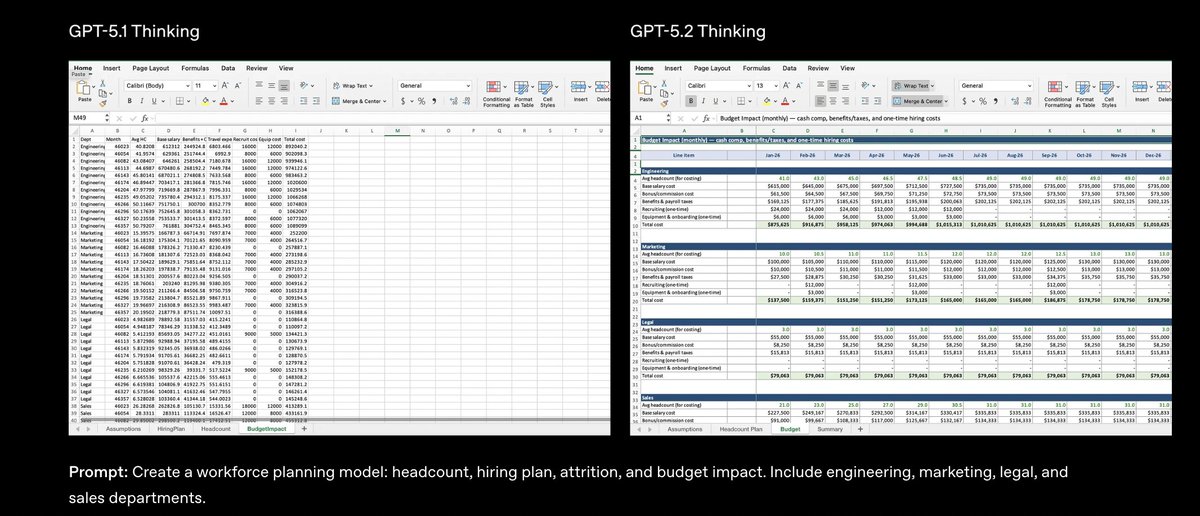
GPT-5.2가 출시되어 지식 작업, 프로그래밍, 과학 연구, 장문 문서 작성 및 비전 작업 분야에서 업계의 한계를 대폭 끌어올렸습니다. 즉시, 사고, 전문가의 세 가지 레벨로 구성되어 있습니다. GDPval(44가지 직업 지식 과제를 측정하는 평가)에서 "인간 전문가 수준"을 달성한 GPT-5.2 Thinking은 70.9%의 사례에서 업계 전문가와 동등하거나 그 이상의 성능을 보였으며, 속도는 11배 빠르고 비용은 전문가 비용의 1% 미만이었습니다. 그들은 특히 스프레드시트와 프레젠테이션 제작에 능숙하며, 투자 은행 스프레드시트 모델링 작업에서 평균 점수가 GPT-5.1보다 9.3% 더 높습니다. 다시 말해, 과거에는 AI에게 코드를 작성하거나, PPT 프레젠테이션을 만들거나, 금융 모델을 구축하도록 요청하면 초안만 제공되었고, 형식, 공식, 참고 자료 및 미적 요소는 모두 수동으로 수정해야 했습니다. 이제, 요구 사항을 충족하면 수식, 서식, 색 구성표 및 주석이 모두 포함된 Excel/Slide 파일을 한 번에 제출할 수 있습니다. 코딩 능력: SWE-Bench Pro에서 55.6%, SWE-Bench Verified에서 80%를 기록했으며, 향상된 기능으로 프런트엔드 3D 및 복잡한 UI를 한 번에 생성할 수 있습니다. 수학 및 물리 연구: AIME 2025 수학 경시대회에서 100% 정확도 달성 FrontierMath T1-3 40.3%(+9.3%)의 향상은 연구자들이 통계적 학습 이론에 대한 새로운 증명을 완성하는 데 도움이 되었습니다. GPQA 다이아몬드 졸업생 레벨 질의응답: 92.4%; 프로 레벨: 93.2%. 긴 텍스트와 이미지: 256,000개의 토큰 내에서 "4-needle" 토큰의 검색률은 거의 100%에 달하며, MRCRv2 세그먼트는 평균 30개의 플롯에서 앞서고 있습니다. 차트, 대시보드 및 마더보드 이미지 인식 오류율이 절반으로 줄었으며, 파이썬 도구와의 통합을 지원합니다. 도구 호출 및 지능형 에이전트: Tau2-bench는 차이나텔레콤 시나리오에서 98.7%의 성공률을 자랑하며, 사용자가 항공편 변경, 수하물 추적, 특별 좌석 요청 등 10단계 이상의 작업을 여러 시스템을 거쳐 단일 프로세스로 완료할 수 있도록 지원합니다. 환각 증상 감소: 실제로 ChatGPT 응답의 오류율은 30% 감소했으며, 검색 기능을 활성화한 후에는 오류율이 93.9%까지 떨어졌습니다. 입력 1.75 / 1M 토큰 (0.175 캐시됨), 출력 14; 프로 버전 21 / 168$ ChatGPT Plus 이상 사용자에게 오늘부터 단계적으로 서비스가 제공될 예정이며, API는 완전히 출시되었습니다. #GPT52 #OpenAIGPT
블로그openai.com/zh-Hans-CN/ind…IL