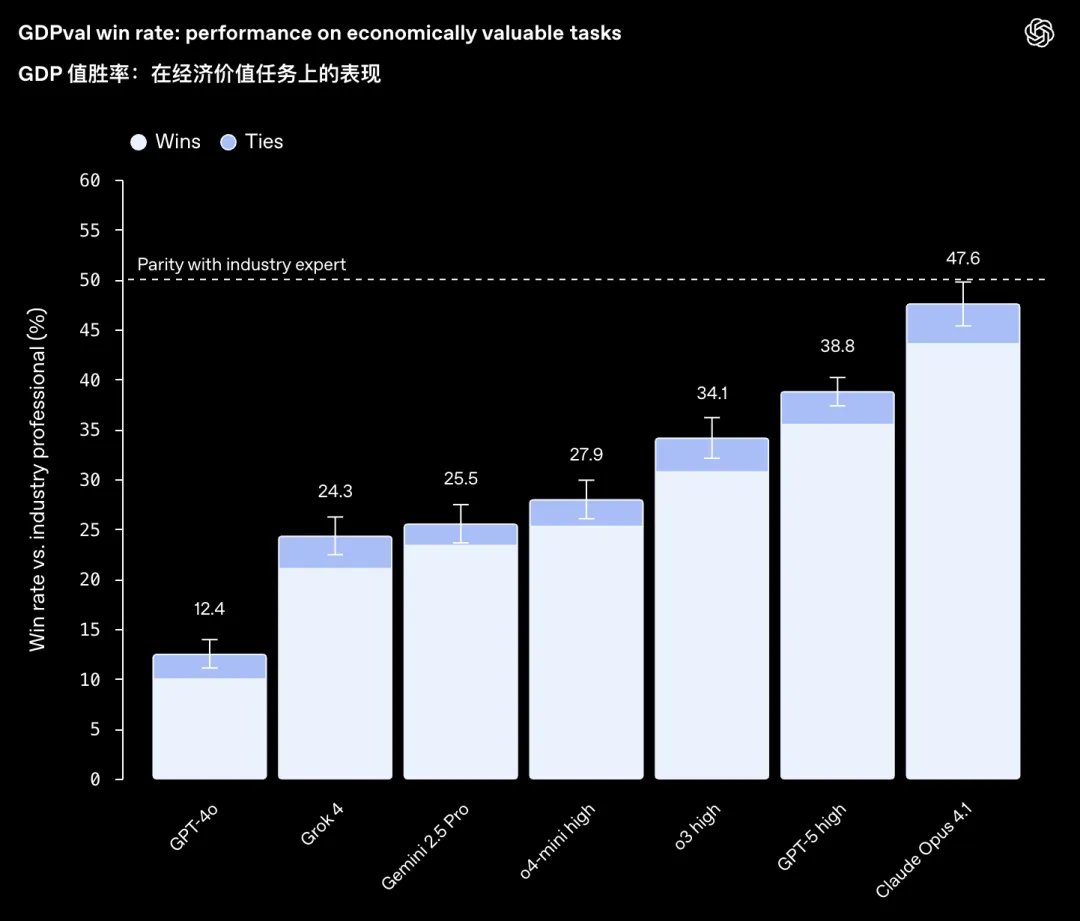
Sam 狂喜,OpenAI 的年底答卷 GPT 5.2 正式发布 不要被他的版本号欺骗,这是今年 OpenAI 的年底大招。 官方定位是:迄今为止面向专业知识工作的最强大模型。 模型性能大幅提升,价格也大幅提升了 40%。 在降本的大趋势下,模型涨价,一般都需要底气。 这个模型的底气在哪里? 前阵子 OpenAI 设计了 GDPval,一个以国内生产总值(GDP)这一关键经济指标为灵感。 1320个专业任务,覆盖了美国 GDP 贡献排名前 9 大行业中精选出的 44 个职业。 任务要求提交真实的成果作品,例如销售演示文稿、会计电子表格、急诊排班表、制造流程图,或短视频。 刚发布 GDPval 的时候,Claude Opus 4.1 以 47.6 的分数遥遥领先。 但是今天, GPT-5.2 直接把分数刷到了 70% 以上。
Coding 编码能力 SWE-Bench Pro 是一项针对真实世界软件工程的严格评估。 与仅测试 Python 的 SWE-bench Verified 不同,SWE-Bench Pro 测试四种语言,并致力于具备更强的抗污染能力、更高的挑战性、更丰富的多样性以及更强的工业相关性。 GPT‑5.2 Thinking 在 SWE-Bench Pro 上取得了 55.6%的全新最先进水平。超过了 Claude Opus 4.5 的 52% 和 Gemini 3 Pro 的 43.3% 。

GPT‑5.2 在长上下文推理领域树立了新的行业标杆。 MRCR v2(多轮共指消解)指标衡量的是,多个完全相同的“针”式用户请求会被插入到由大量相似请求和响应组成的“ haystack”长文档中,然后要求模型重现第 n 个“针”对应的响应。 GPT‑5.2 的第一个在 4 针 MRCR 变体(最长可达 256k token)上实现接近 100%准确率的模型。

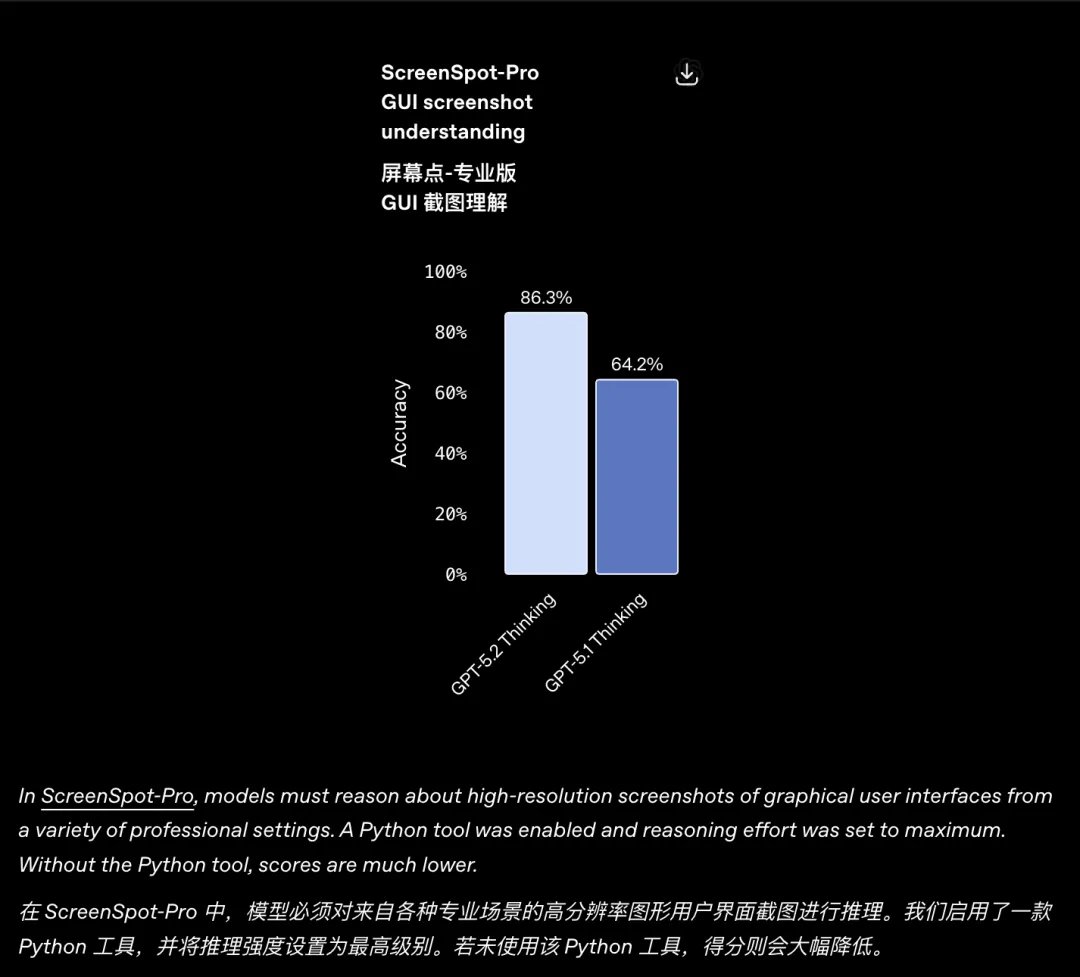
幻觉降低 GPT-5.2 的另一大进步在于显著降低了“幻觉”。错误率相比前代降低了 30%。 视觉理解 GPT‑5.2 Thinking 在图表推理和软件界面理解任务上的错误率几乎降低了一半。

普通版:输入 1.75 美元,输出 14 美元。 专业版:输入 21 美元,输出 168 美元。 总体比 GPT 5.1 涨价 40% 。 太强了。 太贵了。 AI 今年的趋势,一个是文本模型涨价(GPT 5.2),一个是图像模型涨价(banana Pro)。 AI 明年的趋势,会不会是,视频模型涨价?
