형제들이여, 이거 정말 멋지네요! Qwen-Image-i2L: "모든 이미지를 LoRA 모델로 변환"할 수 있습니다. "이미지를 입력하면 자동으로 LoRA(정교하게 조정된 AI 스타일 모듈)를 생성할 수 있습니다." 특정 아트 스타일, 캐릭터 스타일 또는 아트워크만 제공하면 Qwen-Image-i2L이 이미지의 시각적 특징을 분석하여 자동으로 LoRA 모듈을 생성합니다. 그러면 이 LoRA를 다른 모델에서도 사용할 수 있습니다. Qwen-Image-i2L은 SigLIP2 + DINOv3 + Qwen-VL 특징 추출 시스템을 활용합니다. 이미지는 "스타일 + 콘텐츠 + 구도 + 어조"와 같은 학습 가능한 특징으로 분해됩니다. 그런 다음 이를 경량 LoRA 모듈로 압축했습니다. 생성된 LoRA는 생성 모델에 직접 로드하여 사용할 수 있으므로 "단일 이미지 스타일 전송"이 가능합니다.

Qwen-Image-i2L은 다양한 용도에 맞는 네 가지 "모델 스타일"을 제공합니다. 🎨 스타일 – 순수 심미 추출 (2.4B) 🧩 거친 입자 – 콘텐츠와 스타일을 모두 캡처합니다 (7.9B) ✨ 미세 조정 – 1024x1024 디테일 향상 (7.6B, 거친 버전과 함께 사용) ⚖️ 편향 – 통이완샹(30M)의 고유한 스타일과 일관된 결과물을 유지하기 위함

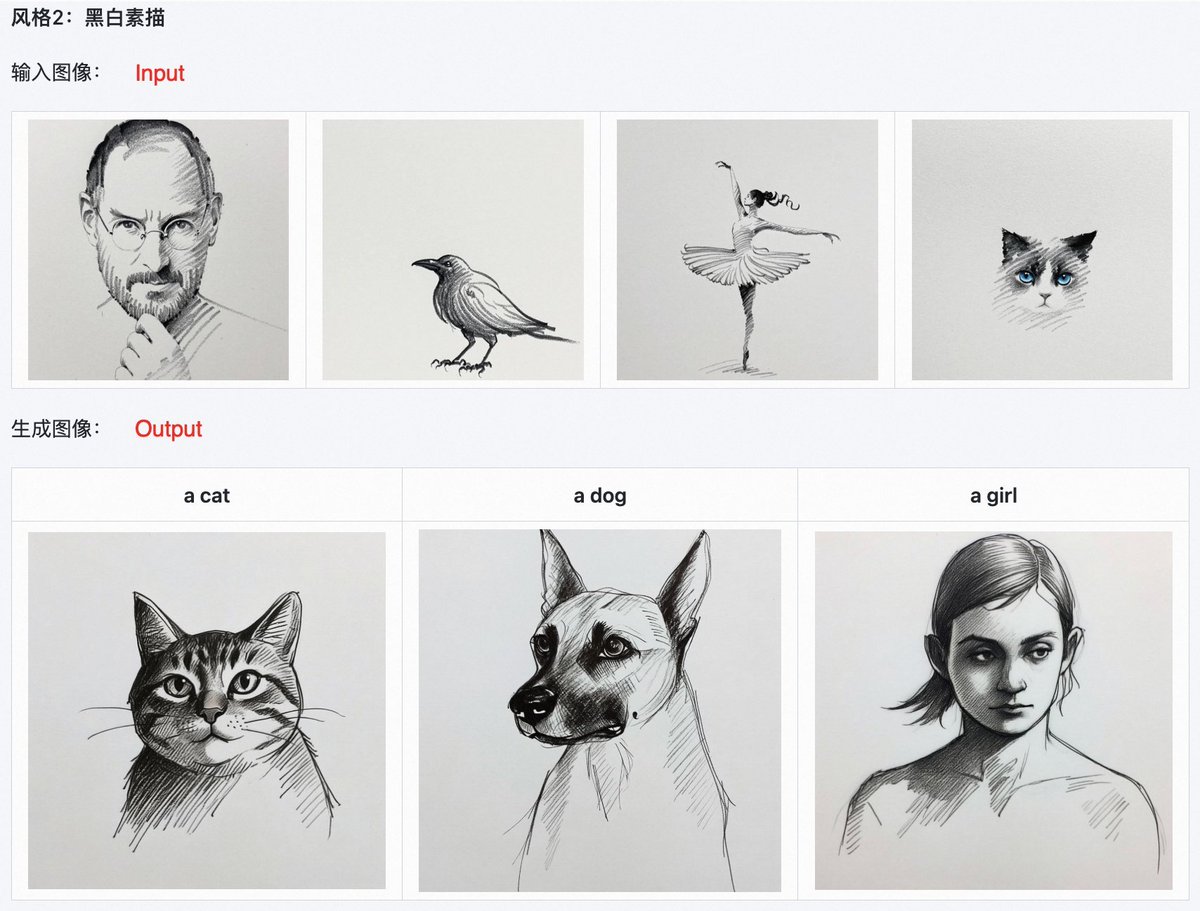
사례 연구

자세한 소xiaohu.ai/c/a066c4/qwen-…vGL 모modelscope.cn/models/DiffSyn…ADMKKHb9
