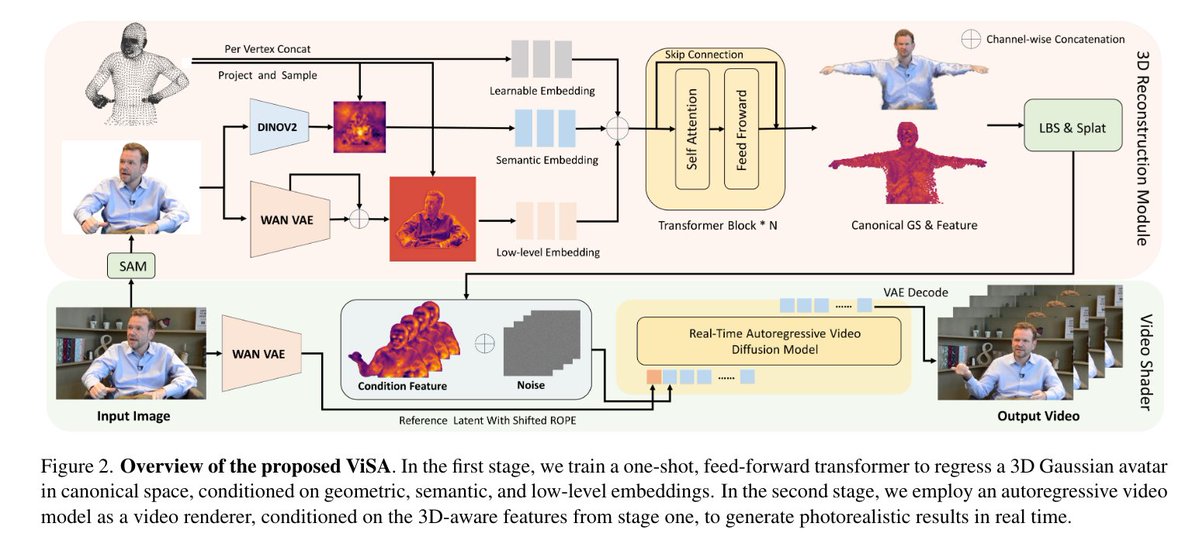
ViSA: 실시간 상체 아바타 생성을 위한 3D 인식 비디오 셰이딩 기여: i) 우리는 원샷 3D 아바타 재구성과 실시간 자기회귀 비디오 셰이더를 통합하여 기하학적 안정성과 생성적 렌더링 성능을 통합하는 새로운 프레임워크를 제안합니다. ii) 우리는 새로운 적대적 분포 보존 손실을 소개하는데, 이는 사전 정제된 몇 단계의 비디오 확산 모델을 효율적으로 미세 조정하여 일반적인 품질 저하를 완화하면서 강력한 신경 렌더러 역할을 할 수 있게 해줍니다. iii) 우리의 방법은 실시간 상체 아바타 생성에 있어 최첨단 기술을 확립하여, 포괄적인 질적, 양적 비교를 통해 검증된 뛰어난 시각적 품질과 동작 사실성을 달성합니다.
논문: httarxiv.org/abs/2512.07720로젝트: https://t.co/1dA7fWqWtT