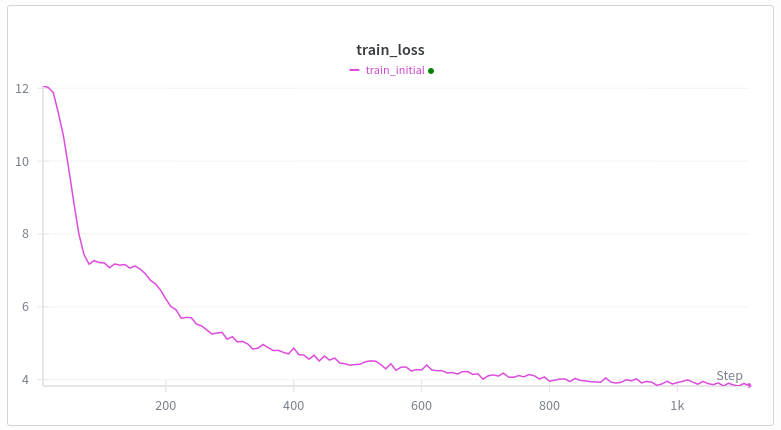
웹텍스트에서 변환기를 처음부터 학습할 때마다 손실 곡선은 다음과 같습니다. 첫 번째 감소는 이해가 되는데, 두 번째 감소는 왜 그럴까요? 쌍둥이자리가 나에게 말도 안되는 소리를 해요. gpt2와 동일한 아키텍처(swiglu, 로프, 묶이지 않은 임베딩 제외) 훈련: 뮤온 + 아담 선형 워밍업(최대 500걸음) 제가 생각하기에 가장 좋은 건 유도 헤드 형성 밈인데, 제가 아는 바로는 이 밈은 꽤 늦게, 즉 수천 개의 훈련 단계나 10억 개의 토큰이나 그런 식으로 발생하는 것 같아요. 그리고 저는 배치당 10만 개의 토큰을 가지고 있어요. 변압기 훈련을 하는 사람 중에 이런 일이 왜 일어나는지 아는 사람이 있나요?