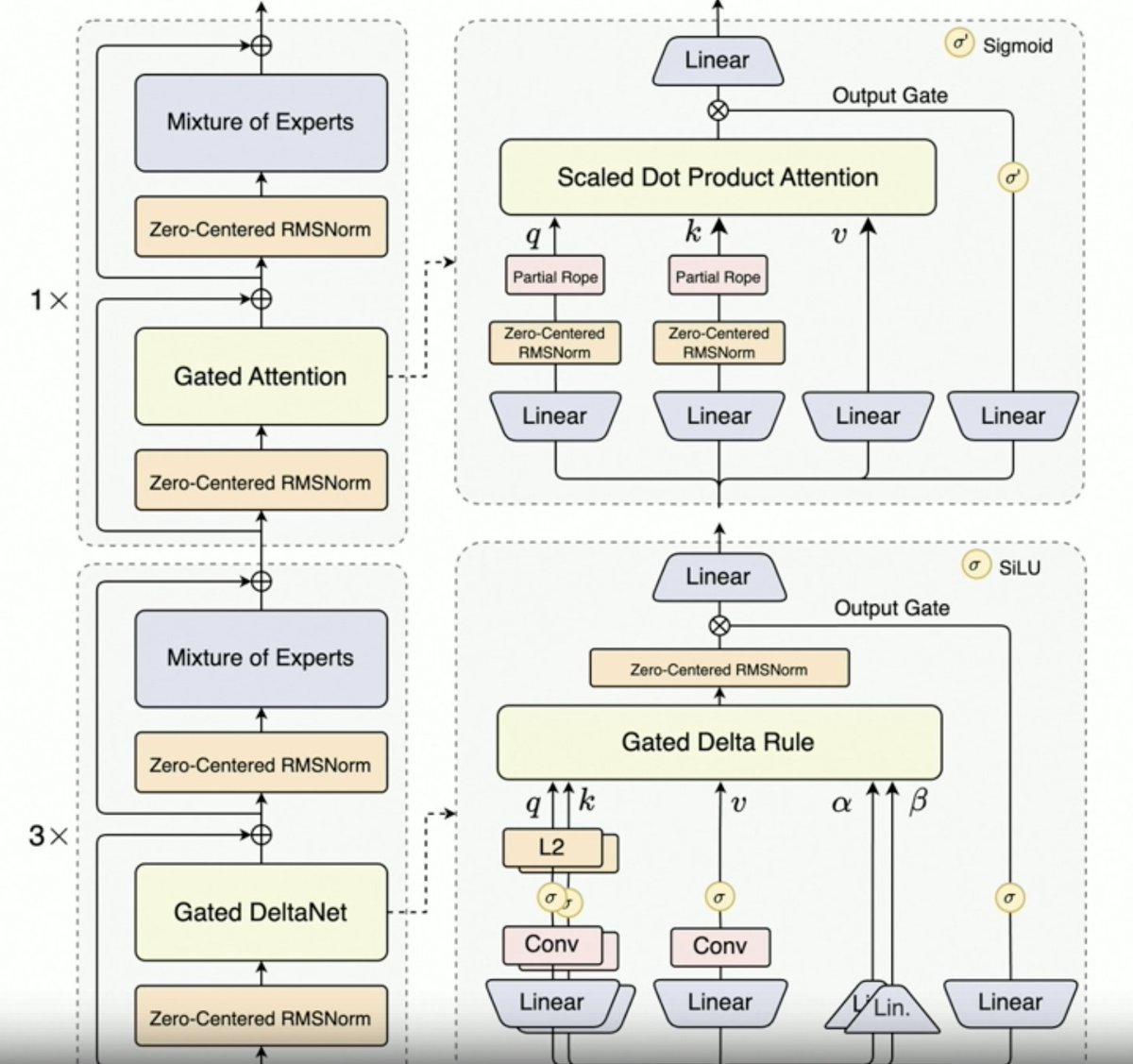
@JustinLin610(Qwen 3 Coder)이 합성 데이터, 강화 학습, 스케일링, 게이츠 주의 및 미래 방향에 대해 이야기하고 있습니다. - 사고방식이 코딩 사용 사례를 잘 지원하지 않습니다. - 컨텍스트 길이는 256K이지만, 코드가 컨텍스트에 추가되기 전에 필터링되므로 코딩 에이전트에게는 128K도 충분할 것입니다. 단, API는 100만 개의 토큰을 지원합니다. - Qwen 2.5 Coder는 Qwen 3 Coder를 사용하여 합성 데이터를 생성하는 데 도움이 되었습니다. 노이즈가 있는 데이터를 가져와 정리하고 다시 작성하는 작업이 포함되었습니다. - Qwen 팀의 대규모 RL 환경(MegaFlow 스케줄러 사용). 여러 개의 스캐폴드/에이전트를 사용하여 궤적을 생성합니다(흥미롭습니다). - RL 성능이 크게 향상되었으므로 노력할 가치가 있습니다. - Qwen3-Max는 알리바바의 규모를 키웠습니다. 혁신은 크지 않지만, 규모는 훨씬 커졌습니다. 이는 모두 확장성 덕분입니다. - 차세대 Qwen LLM은 Qwen3-Next의 성공에 힘입어 Gated Delta Attention을 도입할 것입니다. 또한, Sparse Attention 기법(DSA?)을 결합할 가능성도 있습니다. - 미래 방향 1. 장기적 맥락을 위한 새로운 아키텍처 2. 통합 검색 기능 3. 컴퓨터 사용 에이전트를 위한 코딩 모델에 비전 통합 4. 장기 작업(24시간 이상)을 위한 기술