"자기 개선 에이전트를 구축하는 더 나은 방법" 저는 @exaailabs를 사용하여 발견된 2025년 neurips 논문에 초점을 맞춰 자기 개선 에이전트를 구축하는 접근 방식을 요약한 논문을 chatgpt에서 작성해 달라고 요청했습니다. 실 속의 "종이" 👇

아직 대부분 연구 단계에 있지만 AI 에이전트가 스스로 개선할 수 있도록 돕는 다양한 접근 방식이 점점 더 늘어나고 있습니다.

초기 연구는 "반사"를 저장하는 데 초점을 맞췄습니다.

"자체 교정" 에이전트로 이어짐

생각의 나무 유형 접근 방식은 또 다른 변형입니다. 여러 경로를 시도하고 가장 좋은 것을 선택하세요.

자기 도전 에이전트

문맥 내 예 (이 접근 방식은 반성보다 먼저 이루어져야 했기 때문에 아마 몇몇 논문을 놓쳤을 수도 있습니다)

자기 개선 다중 에이전트

자체 생성 데이터

자체 미세 조정

보상

코딩 에이전트를 사용하면 보상이 더 쉽습니다.

자기 개선 코딩 에이전트(내 취향에 딱 맞음)

재사용 가능한 도구를 구축하다

잠깐, 이게 앞선 섹션과 겹치지 않나요?

보이저의 또 다른 측면과 유사한 접근 방식에 대해 이야기합니다.

안전 및 통제

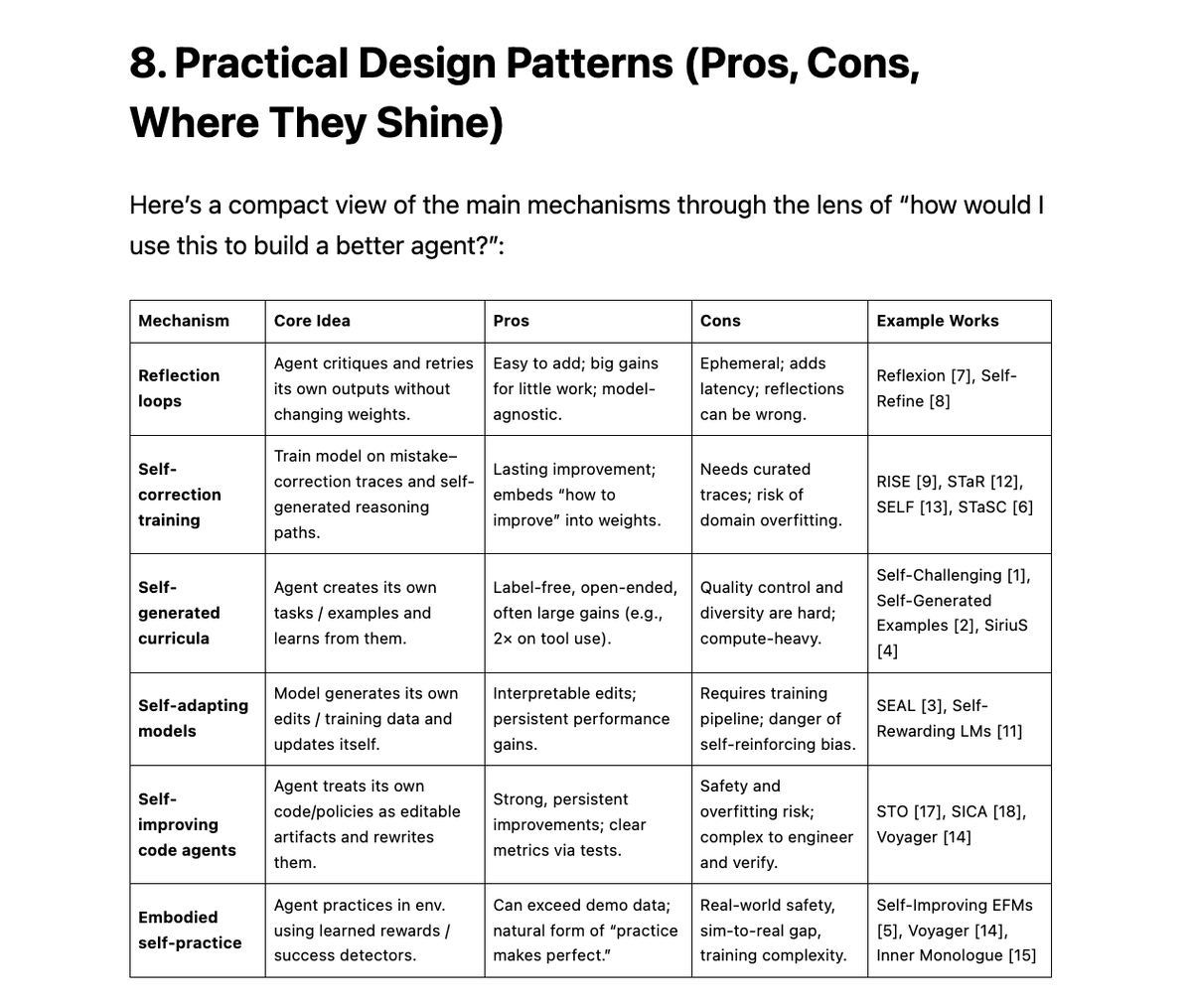
디자인 패턴 비교

다음은 뭐야?

참고문헌 전체 블로그 게시물은 여기에서 확인하세요: https:/yoheinakajima.com/better-ways-to… 제외 사항이 있을 경우 미리 사과드립니다. 제 잘못이 아닙니다. 제가 그랬습니다.)
