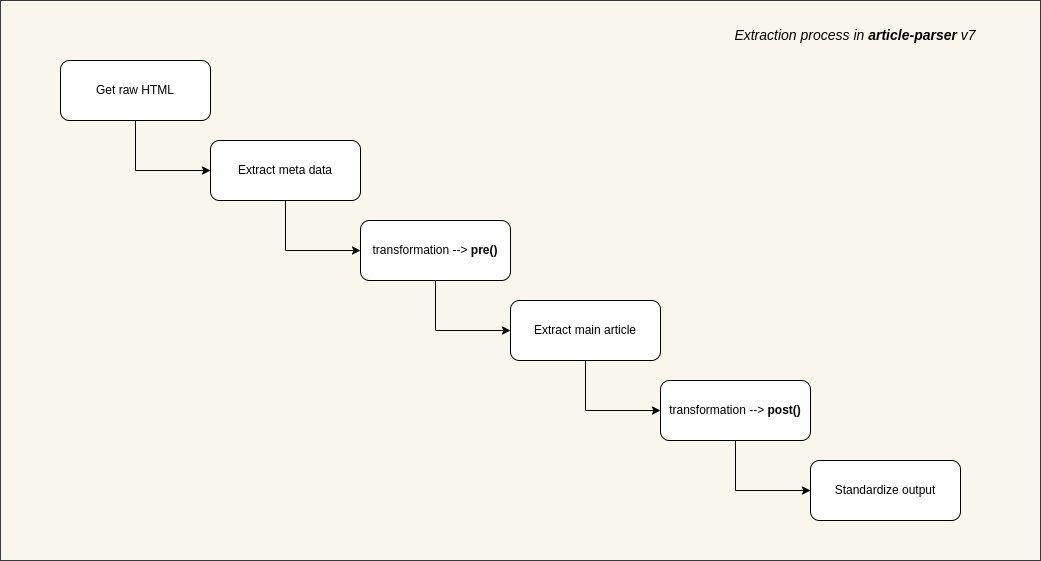
AI에 제공하기 위해 웹 페이지 콘텐츠를 스크래핑하거나 나중에 읽을 수 있는 애플리케이션을 만들 때 가장 큰 장애물은 네트워크 요청이 아니라 광고, 사이드바, 탐색 기능으로 가득 찬 화면에서 주요 텍스트를 정확하게 추출하는 방법입니다. 최근 이 문제를 해결하기 위해 특별히 설계된 오픈소스 라이브러리인 article-extractor를 발견했습니다. 이 라이브러리는 복잡한 URL에서 핵심 기사 데이터를 지능적으로 식별하고 추출할 수 있습니다. 자동으로 페이지 혼란을 제거하고 구조화된 제목, 본문 텍스트, 표지 이미지, 저자, 심지어 읽는 시간까지 반환할 수 있습니다. GitHub: https://t.co/bF0hvCYr8I 사용자 정의 변환 논리를 지원하므로 특정 도메인에 대한 전처리 또는 후처리 규칙을 작성할 수 있어 추출 정확도가 크게 향상됩니다. Node.js, Bundle 및 브라우저 환경과 호환되며, 스크래핑 방지 전략에 쉽게 대처할 수 있도록 프록시 및 사용자 정의 헤더 구성을 지원합니다. 콘텐츠 수집기나 RSS 리더를 개발 중이거나 대규모 모델을 훈련하기 위해 웹 페이지 데이터를 정리해야 하는 경우, 이 라이브러리는 툴박스에 추가해 두는 것이 좋습니다.