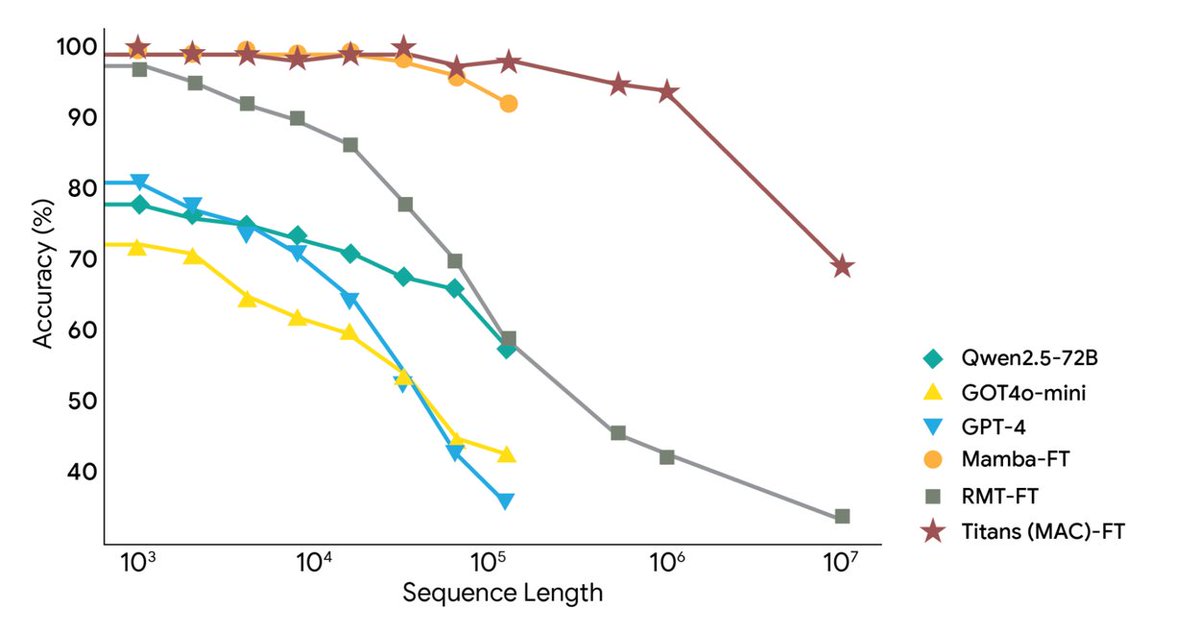
Google Research는 오늘 Titans 아키텍처와 MIRAS 프레임워크라는 두 가지 새로운 프레임워크를 출시했습니다. 이 프레임워크는 AI의 매우 긴 컨텍스트와 장기 메모리 문제를 해결하고 컨텍스트를 200만 개 이상의 토큰으로 확장했습니다. 실시간 학습을 위해 딥 뉴럴 메모리를 사용하여 대규모 모델이 실행 중에도 장기 메모리를 실시간으로 업데이트할 수 있으므로 RNN의 속도와 Transformer의 정확도를 달성합니다. Titans를 사용하면 AI가 런타임 중에 장기 메모리 모듈을 실시간으로 업데이트할 수 있습니다. MIRAS는 통합 메모리 시스템에 대한 이론적 청사진을 제공합니다. Titans는 기존 RNN의 고정 벡터 대신 다층 퍼셉트론(MLP)을 사용하여 장기 기억을 생성합니다. 새로운 단어가 읽힐 때마다 "놀람 수준"이 계산됩니다. 주목할 만한 단어는 장기 기억에 저장되고, MLP의 매개변수는 그에 따라 업데이트됩니다. 용량을 제어하기 위해 가중치 감소가 추가되어 중요하지 않은 오래된 정보가 자동으로 희미해졌습니다. 궁극적으로 주의 계층은 "요청에 따라" 장기 기억을 검색할 수도 있고, 가장 최근의 맥락만을 살펴볼 수도 있습니다. MiRAS는 통합된 관점을 제시하며, 주류 시퀀스 모델들이 본질적으로 동일한 문제, 즉 중요한 정보를 잊지 않고 새로운 정보와 기존 기억을 효율적으로 결합하는 방법을 해결하고 있다고 주장합니다. 이 모델들은 모두 서로 다른 형태의 "연상 기억" 시스템입니다. 이는 AI 모델의 메모리 시스템을 메모리 구조, 주의 편향, 보존 게이트, 메모리 알고리즘의 네 가지 핵심 부분으로 분류합니다. 나아가 이 논문은 판단을 위해 더욱 복잡하고 정교한 수학적 방법을 사용할 것을 제안하는데, 이를 통해 더욱 강력하고 견고한 메모리 시스템을 설계할 수 있을 것이다. 실험 결과, Titans는 언어 모델링, 상식적 추론, DNA 모델링, 시계열 예측, 2M 토큰 BABILong 작업에서 비슷한 규모의 Transformer++, Mamba-2, Gated DeltaNet보다 성능이 뛰어나고, 심지어 GPT-4보다 뛰어나다는 것이 밝혀졌습니다. #AI 메모리 #타이탄