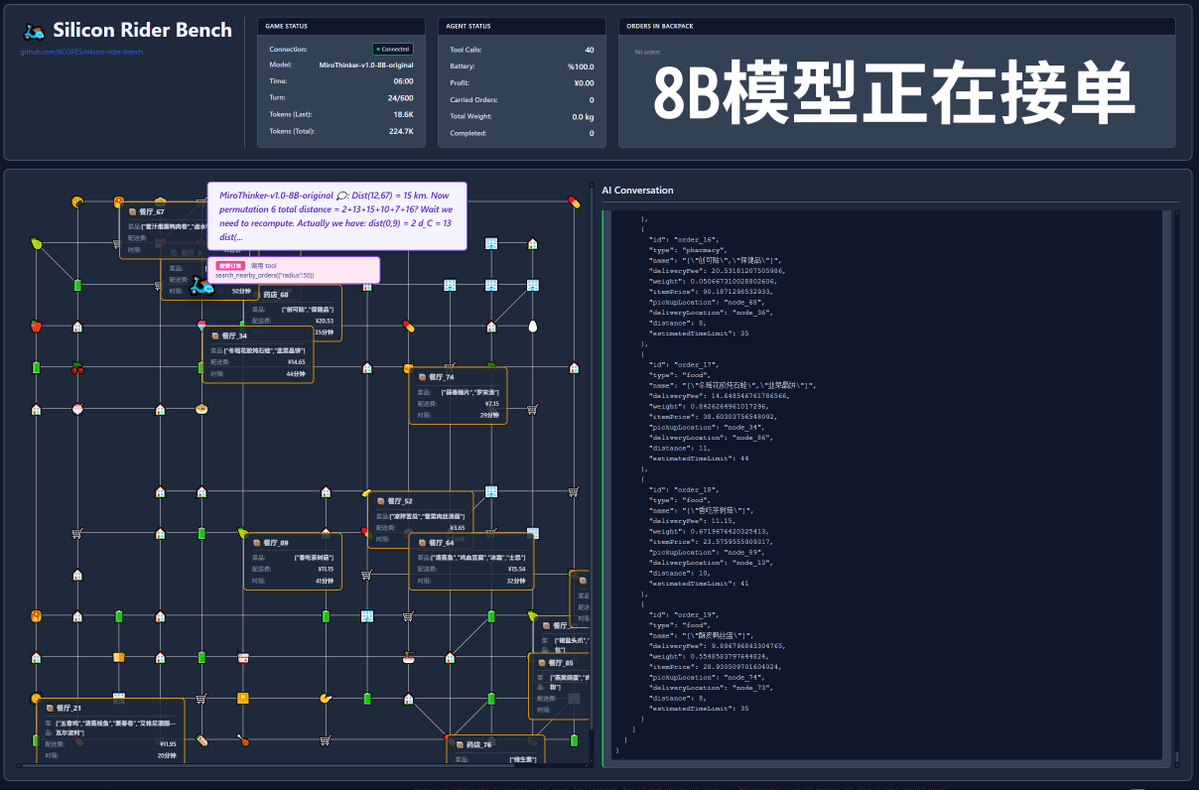
도구 호출이 600건이라고요? MiroThinker-v1.0 모델로 실제 테스트를 확인해 보세요! MiroMind AI가 연구 에이전트에 최적화된 새로운 모델인 MiroThinker-v1.0을 출시했습니다. 72B, 30B, 8B 크기로 제공됩니다. 이 모델의 가장 큰 장점은 향상된 도구 기반 추론 및 정보 검색 기능으로, 최대 컨텍스트 내에서 최대 600개의 도구 호출을 지원합니다! 그렇다면 제 독특한 프로젝트를 주목해볼 때가 됐습니다. 이 모델이 테이크아웃 서비스를 제공한다면 성공할 수 있을까요? 이 테스트에는 https://t.co/5Eyuq3f8be에서 제공되는 공식 모델이 사용되었습니다. 사용된 하드웨어는 H100 80G SXM *4이며, 추론 엔진은 SGLang입니다. 이 테스트를 위해 SiliconRiderBench라는 새로운 테스트 프레임워크를 개발했습니다. 이 프레임워크는 음식 배달 주문을 무작위로 생성하고, AI는 배달 라이더 역할을 해야 합니다. 도구 호출을 통해 주문을 받고, 음식을 픽업하고, 배달하고, 심지어 전기 스쿠터 배터리까지 교체해야 합니다. 이 프레임워크를 사용하여 도구 호출을 효과적으로 활용할 때 모델의 최대 수익성을 테스트하고 있습니다! #MiroThinker #MiroMindAI #ToolCall #KCORES 대형 모델 아레나



먼저 벤치마크 테스트를 살펴보겠습니다. 모델이 100개의 대화를 수행하고, 컨텍스트 창에는 최근 대화 20개가 표시되도록 했습니다. 결론은 다음과 같습니다. 72B 모델이 가장 좋은 성능을 보였으며, 100개의 대화에서 총 155개의 도구 호출을 수행하고, 총 4건의 음식 주문을 처리했으며, 65.31의 수익을 올렸습니다. 다음은 8B 모델로, 총 102건의 툴 콜을 실행하고 총 4건의 테이크아웃 주문을 처리하여 49.17의 수익을 올렸습니다. 그 다음은 30B 모델로, 총 145건의 툴 콜을 실행하고 총 1건의 테이크아웃 주문을 처리하여 22.57의 수익을 올렸습니다.
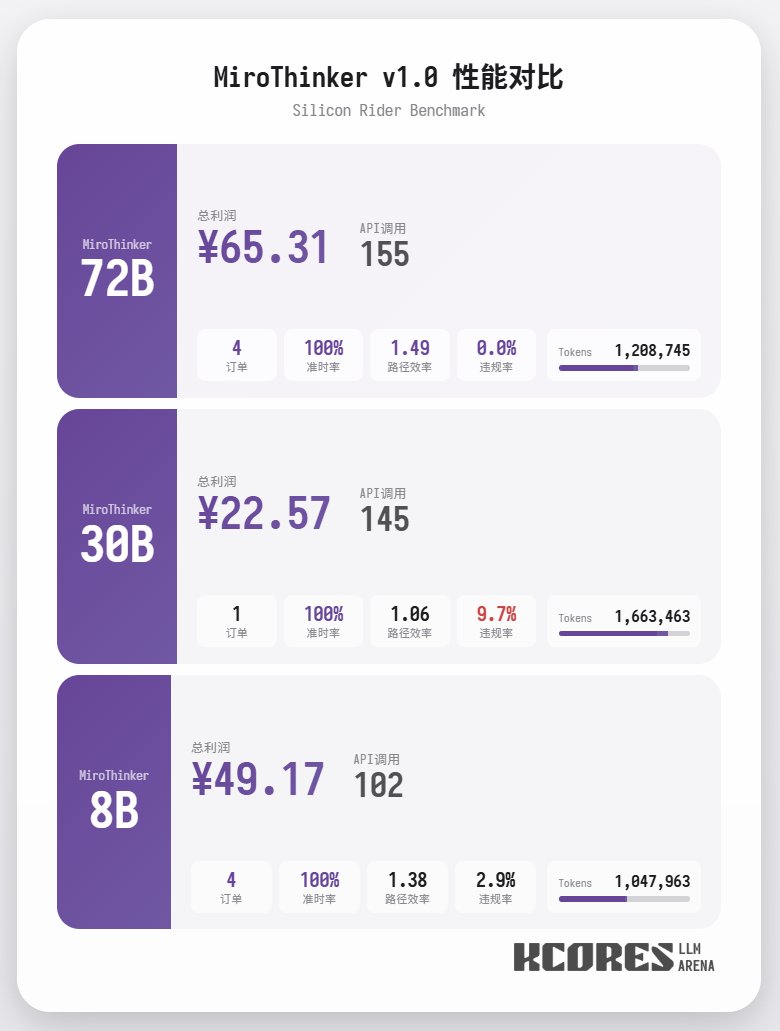
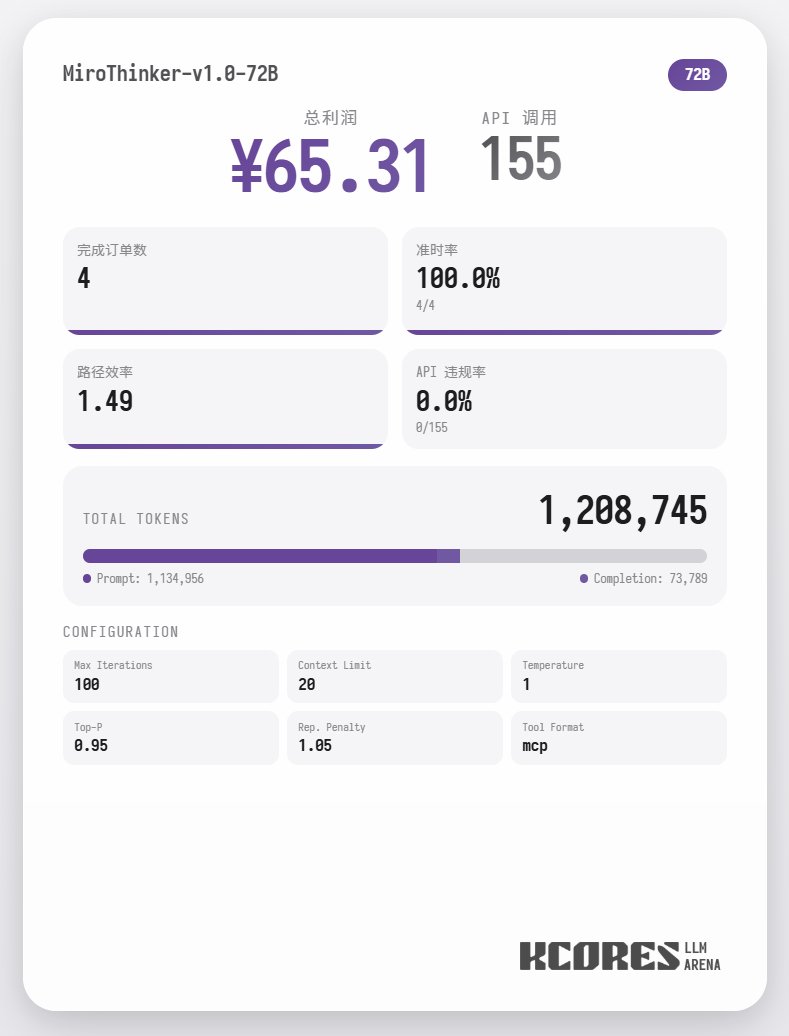
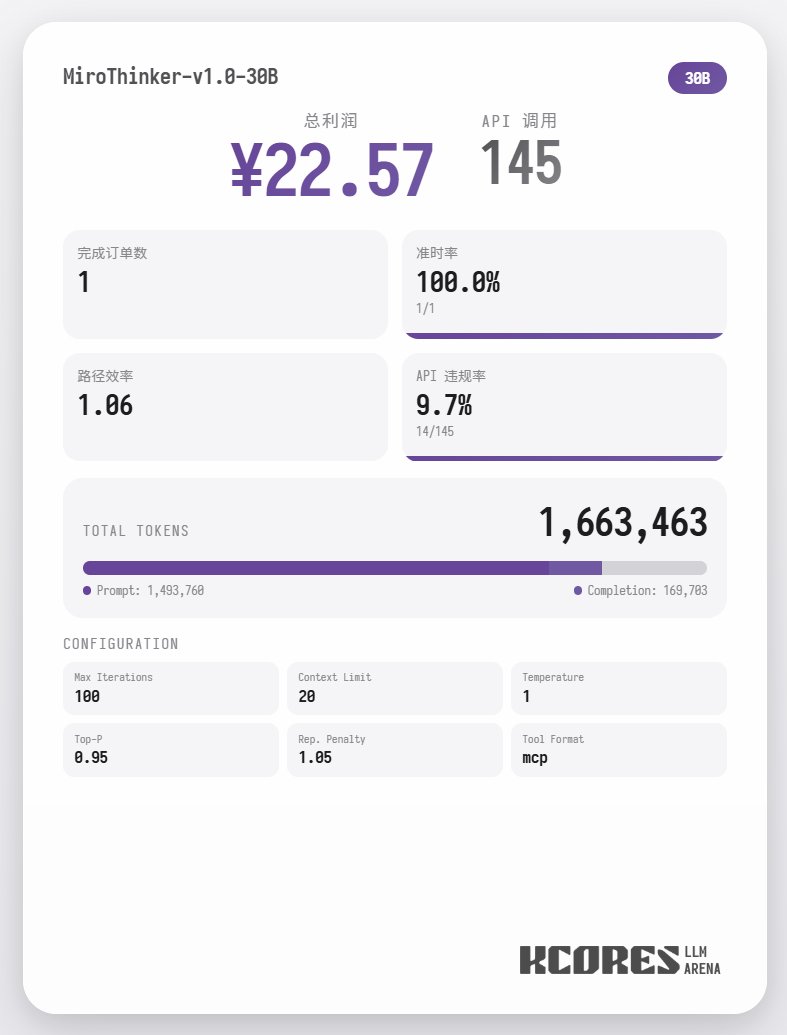
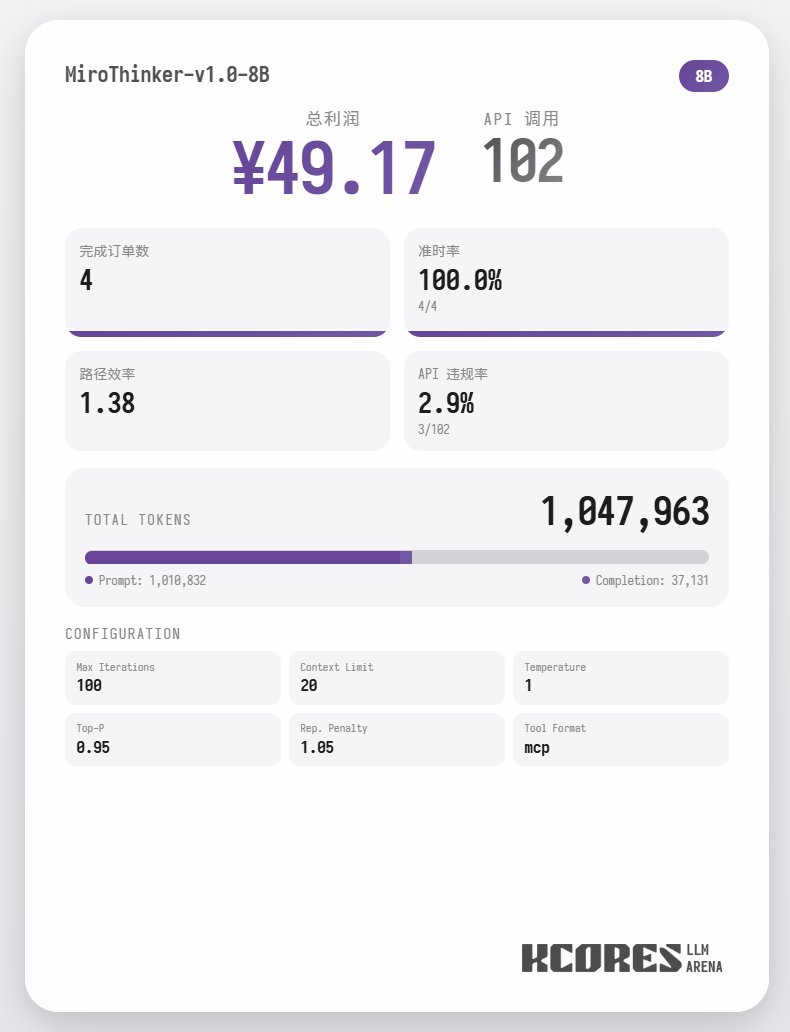
분석 결과 72B 모델이 가장 우수한 성능을 보였고, 그 다음으로 8B 모델이 우수한 성능을 보였습니다. 72B 모델은 주문 접수 및 테이크아웃 주문 처리 방식을 체계적으로 계획할 수 있는 반면, 8B 모델은 전력 소비량과 수익성까지 정량적으로 평가할 수 있습니다. 30B 모델은 주문 스캐닝 도구에 반복적으로 호출되는 문제로 인해 성능이 다소 저조했습니다. 이는 기본 모델의 장문 맥락 재현 능력이 고르지 않기 때문으로 추정됩니다.



자세한 데이터
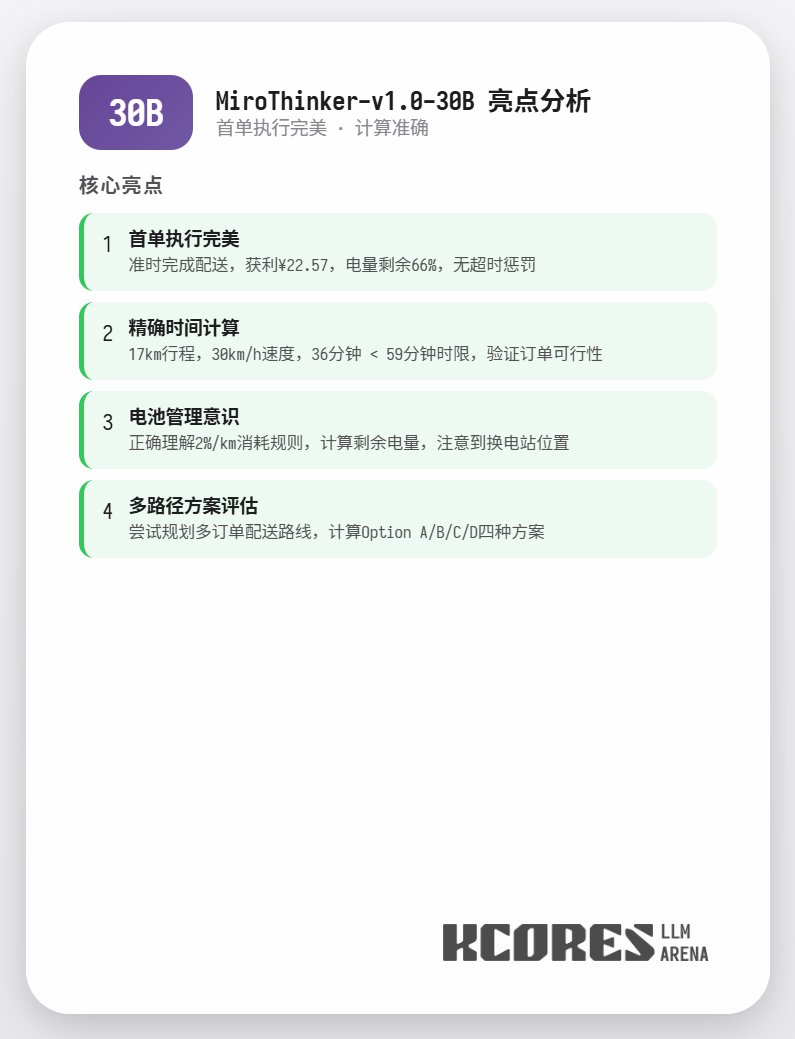



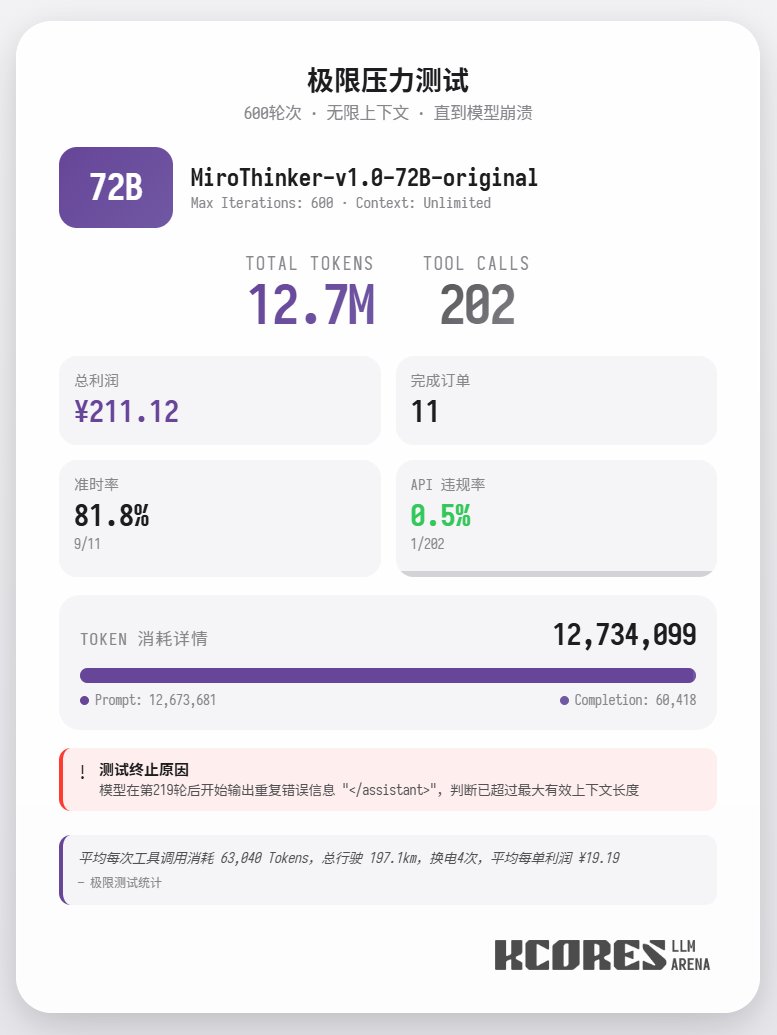
또한, 72B 모델을 컨텍스트 제한 없이 사용하여 음식을 배달하는 극단적인 테스트가 수행되었습니다. 이 모델은 최종적으로 202회의 도구 호출을 수행하여 총 1,270만 개의 토큰을 소비하고, 11건의 주문을 완료하여 211.12를 획득했습니다. 202회의 도구 호출 중 단 한 건만 API 위반(즉, 잘못된 메서드 호출)을 발생시켰으며, 이는 72B 모델이 매우 긴 컨텍스트에서도 탁월한 리콜 성능과 도구 호출 기능을 유지함을 보여줍니다. 요약하자면, 72B는 복잡한 에이전트 작업에서 가장 우수한 성능을 보이고, 8B는 리소스 효율성에서 탁월하며, 30B는 실행 측면에서 개선이 필요합니다. 특히 연구 에이전트 시나리오에서 많은 도구를 사용해야 하는 경우, MiroThinker 시리즈 모델을 사용해 보는 것이 좋습니다.