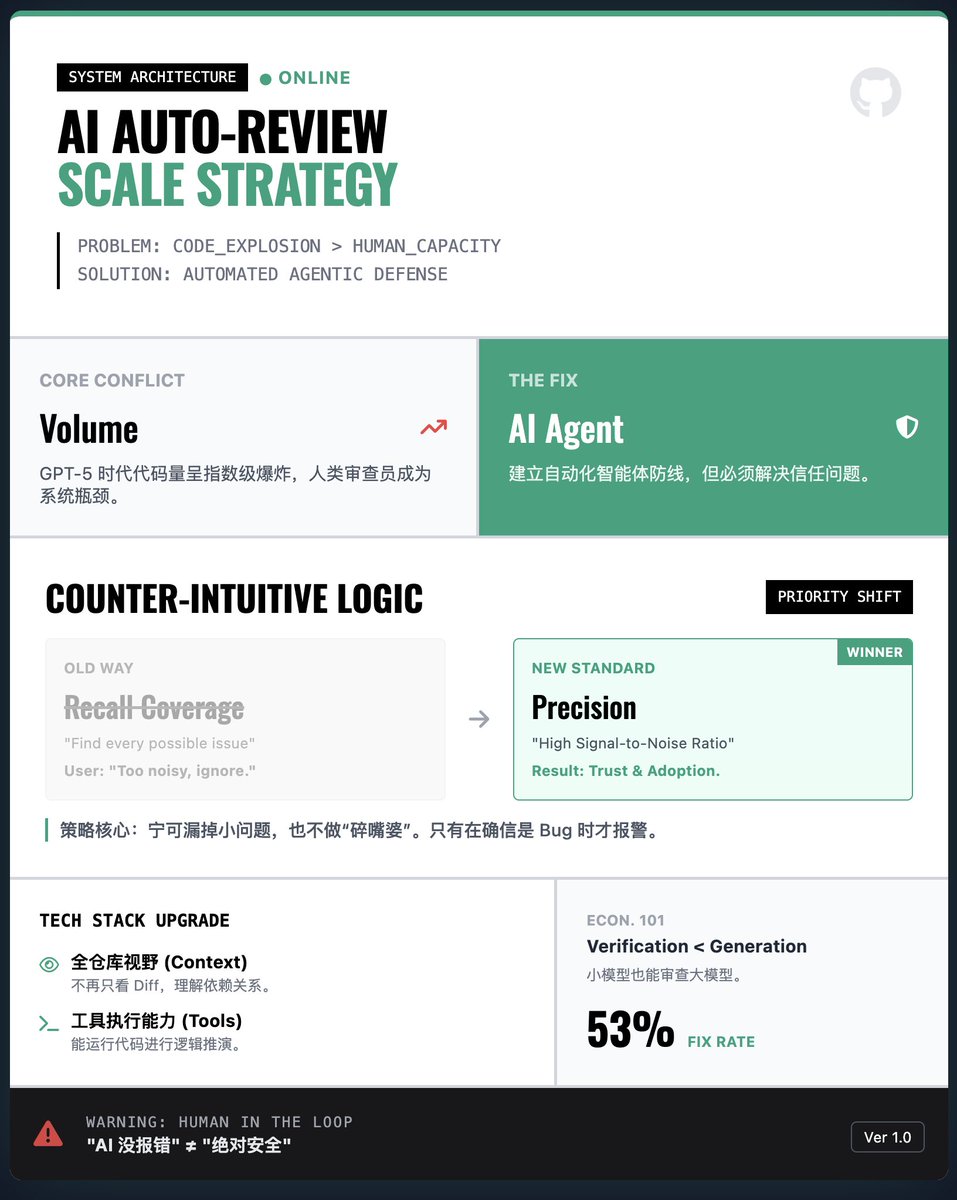
OpenAI는 어떻게 대규모 AI 자동화 코드 검토 시스템을 구축하나요? 핵심 과제: 폭발적인 코드 양 vs. 인적 자원 병목 현상. AI가 생성하는 코드(예: GPT-5-Codex)가 기하급수적으로 증가함에 따라, 인간은 코드를 한 줄 한 줄 검토할 수 없습니다. 검증 없이 AI 생성에만 의존하면 취약점과 버그를 제어하기 어렵습니다. 따라서 OpenAI는 자동화된 코드 검토 에이전트를 구축하여 방어선을 구축할 것을 제안합니다. 핵심 전략: 범위보다 정밀성(반직관적!) • 일반적인 논리는 다음과 같습니다. 우리는 AI가 모든 잠재적 문제를 찾아낼 것으로 기대합니다. • OpenAI의 연구 결과: 실제 엔지니어링에서 AI가 "수다쟁이"와 같은 사소하거나 관련성 없는 문제를 많이 보고하면 개발자는 그냥 도구를 포기할 것입니다. 해결책: 개발자의 신뢰를 얻기 위해 시스템은 "양보다 질"을 중시하도록 설계되었으며, 높은 신호 대 잡음비를 우선시하고 버그가 심각하다고 확신할 때만 알림을 발행하여 사소한 문제를 놓치는 위험을 감수했습니다. 기술적 혁신: 전체 저장소 컨텍스트 및 도구 사용 • 초기 검증 모델은 일반적으로 컨텍스트가 부족하여 코드 차이점만 살펴보았습니다. 새로운 검토 에이전트는 전체 저장소를 완벽하게 파악하고 코드를 실행할 수 있습니다. 즉, 코드를 "볼" 뿐만 아니라 전체 프로젝트의 종속성을 기반으로 논리적 추론을 수행할 수 있어 검토의 정확성이 크게 향상됩니다. 경제적 관점: 검증은 생성보다 저렴합니다. 이 기사는 흥미로운 사실을 지적합니다. 올바른 코드를 생성하는 데는 많은 컴퓨팅 리소스가 필요하지만, 코드 검증에는 일반적으로 매우 적은 리소스만 필요합니다. 비교적 적은 컴퓨팅 예산으로도 검열 에이전트는 강력한 모델에서 발생하는 대부분의 오류를 효과적으로 포착할 수 있습니다. 이는 대규모 배포를 위한 경제적 기반을 제공합니다. 실제 적용 및 경고: 실제 결과: 이 시스템은 OpenAI와 GitHub에서 널리 사용되었습니다. 데이터에 따르면 AI 리뷰 의견의 약 53%가 개발자가 채택하여 코드 수정에 사용되었으며, 이는 제안의 높은 가치를 보여줍니다. • 과도한 의존 위험: AI 검토는 "대체"가 아닌 "지원"일 뿐입니다. 팀은 "AI가 오류를 보고하지 않는다"는 것을 "절대적인 안전"과 동일시하는 안일한 태도를 경계해야 합니다. 독서 보고서