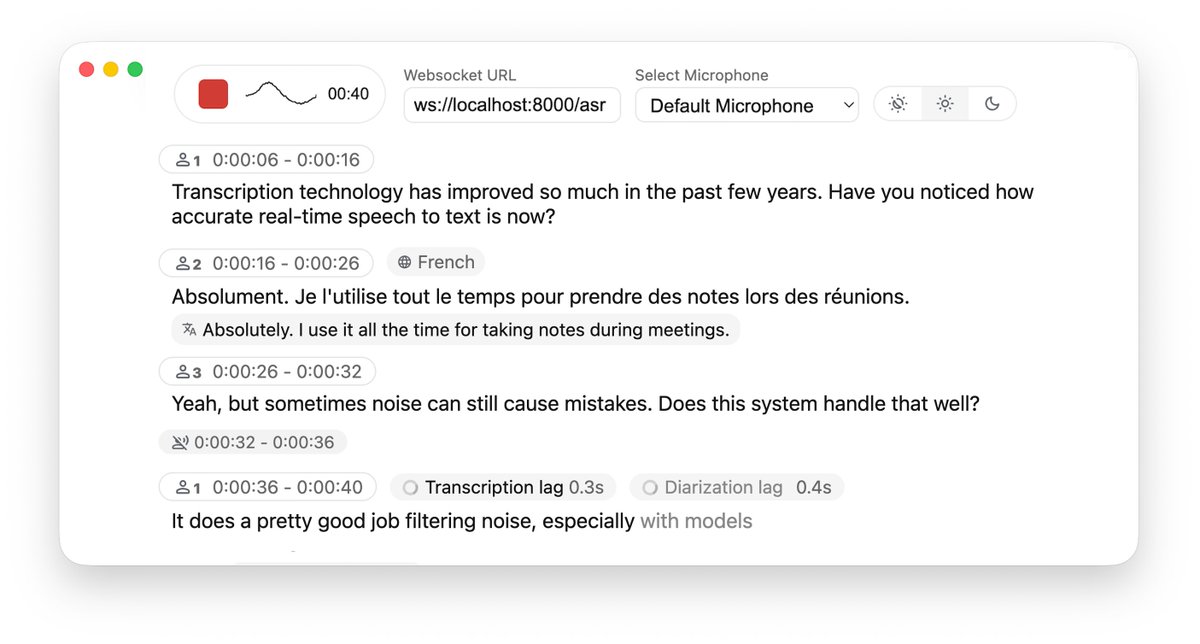
프로젝트에서 실시간 음성-텍스트 변환을 구현하려면 일반적으로 클라우드 API를 선택해야 하는데, 이는 비용이 많이 들 뿐만 아니라 데이터 개인 정보 보호에 대한 우려도 제기됩니다. Whisper의 로컬 배포는 무료이지만 스트리밍 오디오를 처리할 때 지연 시간과 문장 분할 환경이 만족스럽지 못한 경우가 많습니다. 저는 GitHub에서 WhisperLiveKit 오픈소스 프로젝트를 우연히 발견했는데, 이는 스트리밍 지연 문제에 특별히 최적화된 완벽한 로컬 실시간 음성 인식 및 번역 솔루션을 제공합니다. 이 제품은 고정밀 실시간 음성 변환을 지원할 뿐만 아니라, 음성 인식(Diarization)과 음성 활동 감지(VAD) 기능이 내장되어 있어 말하는 사람과 말하는 순간을 정확하게 구분할 수 있습니다. GitHub: https://t.co/SVCcyqdqhG 백엔드는 매우 유연하여 Apple Silicon에 최적화된 Faster Whisper나 mlx-whisper 엔진과의 통합을 지원하고, 심지어 NLLW 모델을 통합하여 200개 언어의 실시간 번역을 구현하기도 합니다. 이 프로젝트에는 Docker 배포를 지원하는 기성 Python 서버 측 및 웹 프런트엔드 예제가 포함되어 있습니다. 개인정보 보호 및 저지연 회의 녹화 또는 동시 통역 시스템 구축을 위한 매우 견고한 인프라를 제공합니다.