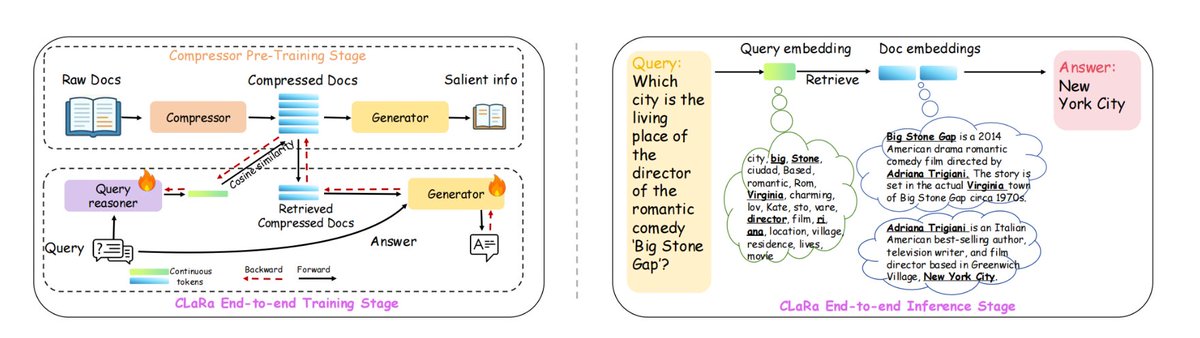
Apple은 ml-clara라는 새로운 RAG 프레임워크를 개발했는데, 이는 긴 컨텍스트를 처리하는 데 따르는 비효율성과 검색 및 생성 최적화 프로세스를 분리하는 문제를 해결합니다. 핵심 아이디어는 전체 텍스트를 큰 모델에 공급하지 않고 대신 "검색" 및 "생성" 프로세스를 동일한 미분 가능한 연속 벡터 공간으로 압축하여 통합된 학습과 단일 단계 추론을 가능하게 하는 것입니다. 이는 다음과 같은 문제를 해결합니다. 1) 컨텍스트의 길이가 늘어나 계산 비용이 폭발적으로 증가함. 2) 검색 및 생성기의 독립적인 학습으로 인해 최적화 목표가 일치하지 않음. 3) 그래디언트 연결 해제 문제. NQ, HotpotQA, MuSiQue, 2Wiki에서는 4×/16×/32×의 다양한 압축률에서 선두 자리를 유지했으며, 32× 압축률에서도 압축되지 않은 순수 검색 기준선보다 여전히 우수했습니다. 정확한 답변을 생성하는 데 필요한 필수 정보를 그대로 유지하면서 컨텍스트 길이를 최대 32×~64×까지 압축할 수 있습니다. 구체적으로, 1. 먼저 사전 학습을 압축하여 QA/반복 의미론을 보존하면서 문서를 32~256차원 벡터로 압축합니다. 2. 그런 다음 압축된 벡터를 하위 질의응답 작업에 맞게 조정하기 위해 지침을 미세 조정합니다. 3. 검색과 생성을 모두 최적화하여 엔드투엔드 조인트 훈련을 더욱 강화합니다. #래그 #ml클라라
깃허브: https://t.co/vf7TFI1Wna