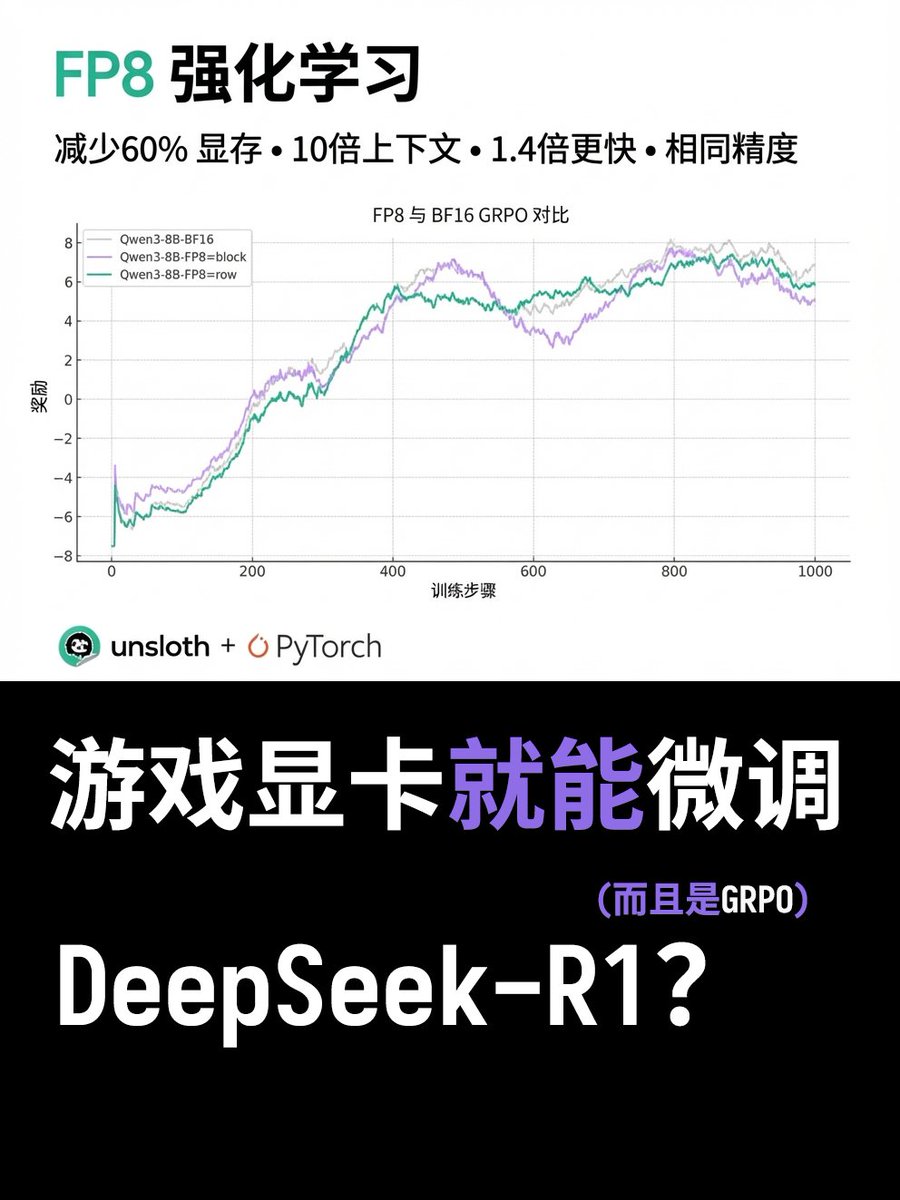
게임 카드에서도 FP8 GRPO를 사용할 수 있나요? Unsloth가 최소한의 VRAM으로 DeepSeek-R1의 FP8 GRPO를 미세 조정하는 방법을 보여주는 새로운 튜토리얼을 공개했습니다! PyTorch와 협력하여 FP8 RL 추론 속도를 1.4배 향상시켰습니다. 그 후, GPU 메모리를 60% 줄이고 컨텍스트 길이를 12배 늘리는 방식으로 프로세스를 미세 조정했습니다. 이 기능은 이제 Unsloth 프레임워크에서 사용할 수 있습니다. FP8 정밀도의 광범위한 도입을 직접적으로 가능하게 하는 이 강화 학습 접근법을 통해 FP8 GRPO를 이제 소비자용 GPU(예: RTX 40, 50 등)에 구현할 수 있습니다. 테스트 데이터에 따르면 Qwen3-1.7B에서 FP8 GRPO를 실행하는 데 5GB의 VRAM만 필요합니다. 튜토리얼 주소: