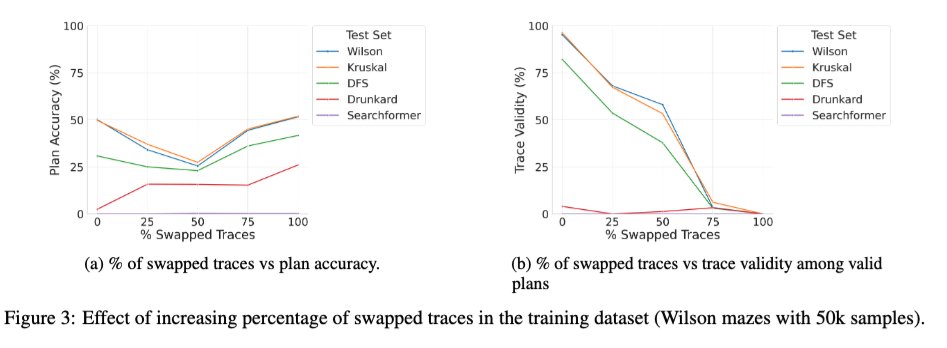
저희는 LRM에서 중간 토큰의 역할에 대한 체계적인 연구인 "의미론 너머" 논문의 확장 버전을 arXiv에 업로드했는데, 여러분 중 일부에게는 흥미로울 수도 있습니다. 🧵 1/ 흥미로운 새로운 연구 중 하나는 기본 변압기를 올바른 트레이스와 잘못된 트레이스를 혼합하여 학습시켰을 때의 효과입니다. 학습 중 잘못된(바꿔진) 트레이스의 비율이 0에서 100으로 증가함에 따라 추론 시점의 모델 트레이스 타당성은 예상대로 단조롭게 감소하지만(오른쪽 아래 그래프), 해의 정확도는 U자 곡선을 보입니다(왼쪽 그래프)! 이는 학습 중 사용된 트레이스의 정확성보다는 "일관성"이 더 중요함을 시사합니다.
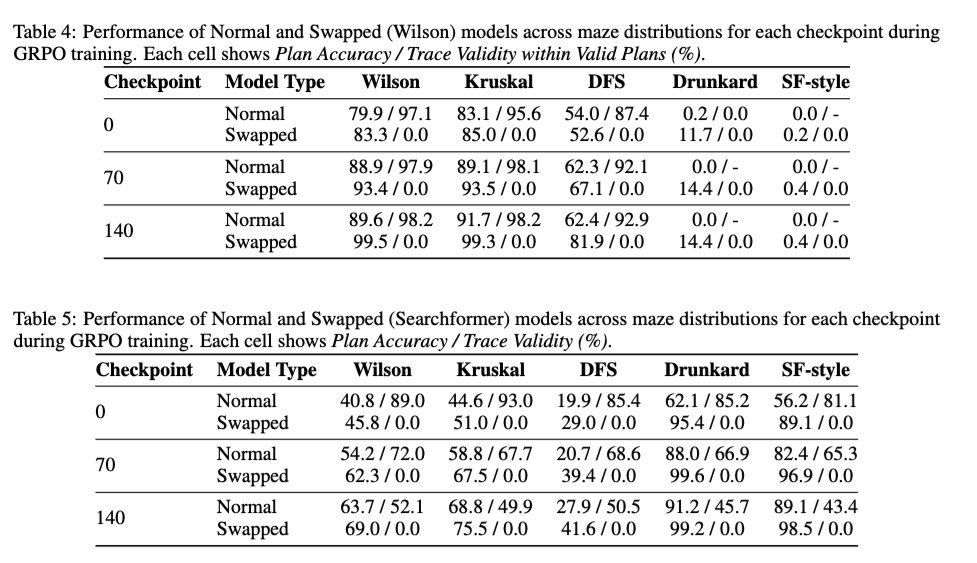
2/ DeepSeek R1 스타일의 강화학습(RL)이 추적 타당성에 미치는 영향을 살펴보았습니다. 강화학습이 기본 모델의 추적 타당성을 향상시키는지 확인하기 위해서였습니다. 결과는 강화학습이 추적 타당성에 기본적으로 중립적임을 보여줍니다. 100% 스왑된 추적으로 학습된 모델의 경우에도 추적 타당성을 높이지 않으면서 해의 정확도를 향상시킵니다.
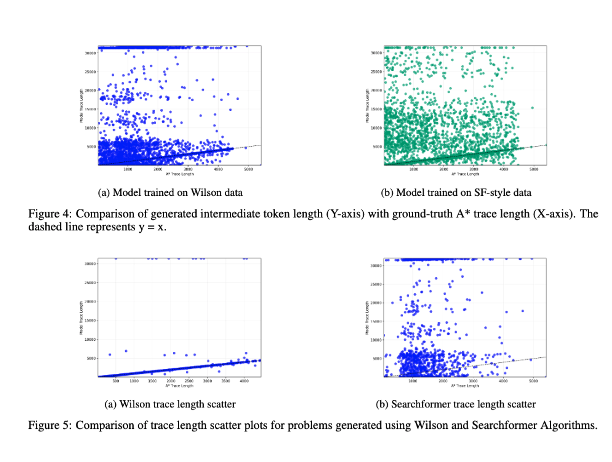
3/ 마지막으로 중간 토큰의 길이와 문제 인스턴스의 계산 복잡도 간의 상관관계에 대한 연구를 포함합니다. 결과는 두 가지 사이에 상관관계가 없음을 보여줍니다! (이 실험의 이전 버전은 https://t.co/RL9ZEOKbpQ에서 논의했습니다.)
4/ 새 버전은 https://t.co/4LGWfiCZ5e에서 arxiv.org/abs/2505.13775 #NeurIPS2025 LAW, ForLM, Efficient Reasoning 워크숍에서 주저자 @karthikv792 @kayastechly & @PalodVardh12428이 발표할 예정입니다. 들러서 이야기 나눠보세요!