이 스탠포드 대학 논문은 읽어볼 가치가 있습니다 👇🏻 그들은 데이터가 전혀 없고, 인간의 주석도 없고, 신중하게 설계된 작업도 없고, 어떤 시연도 없이 AI 에이전트 프레임워크를 구축했지만, 기존의 모든 셀프 게임 방법을 능가했습니다. 이 프레임워크의 이름은 Agent0입니다. 도구를 통해 추론을 통합하여 데이터가 없는 상태에서도 스스로 진화하는 지능형 에이전트를 해방합니다. 그 성과는 놀랍습니다. 여러분이 지금까지 본 모든 "자체 개선" 에이전트는 치명적인 결함이 하나 있습니다. 이미 알고 있는 것보다 약간 더 어려운 작업만 생성할 수 있기 때문에 즉시 병목 현상에 부딪힙니다. Agent0가 이 한계를 깨뜨렸습니다. 핵심은 다음과 같습니다. 그들은 동일한 기본 LLM에서 두 개의 에이전트를 생성하여 서로 경쟁하게 합니다. • 과정 에이전트 - 점점 더 어려운 작업을 생성합니다. • 실행 에이전트 - 추론과 도구를 사용하여 이러한 작업을 해결하려고 시도합니다. 실행 에이전트가 개선될 때마다, 과정 에이전트는 난이도를 높여야 합니다. 작업이 더 어려워질 때마다, 실행하는 에이전트는 진화할 수밖에 없습니다. 이로 인해 폐쇄 루프, 자체 강화 커리큘럼 나선형이 만들어졌고, 모든 것이 데이터도 없고, 사람도 없고, 아무것도 없는 상태에서 시작되었습니다. 간단히 말해서, 두 지적인 주체가 서로를 밀어붙여 더 높은 수준의 지능을 달성하려는 것입니다. 그리고 그들은 치트 코드를 추가했습니다: 완전한 Python 도구 인터프리터가 루프에 빠졌습니다. 실행 에이전트는 코드를 통해 문제에 대한 추론을 학습합니다. 코스 에이전트는 도구 사용이 필요한 작업을 만드는 법을 배웁니다. 따라서 두 지능형 에이전트는 지속적으로 업그레이드됩니다. 그리고 그 결과는 어땠나요? → 수학적 추론 능력 +18% 향상 → 일반 추론 능력 24% 증가 → R-Zero, SPIRAL, Absolute Zero, 심지어 외부 독점 API를 사용하는 프레임워크보다 뛰어납니다. → 이 모든 것은 단순히 자체 진화하는 순환인 0 데이터에서 시작됩니다. 그들은 반복 과정에서 난이도 곡선이 상승한다는 것을 보여주었습니다. 작업은 기본 기하학에서 시작하여 결국 제약 만족, 조합론, 논리 퍼즐, 다단계 도구 종속 문제와 관련된 문제에 도달합니다. 이는 LLM에서 자율적인 인지적 성장에 가장 가까운 모습입니다. Agent0은 단순히 "더 나은 RL" 그 이상입니다. 이는 지능형 에이전트가 자신의 지능을 스스로 관리하기 위한 청사진입니다. 지능형 에이전트의 시대가 열렸습니다.

읽기 전에 이 게시물에 '좋아요'를 누르거나, 공유하거나, 저장하는 것을 잊xaicreator.com는 인간-컴퓨터 협업 콘텐츠 엔진에 의해 게시되었습니다. https://t.co/Gxsobg3hEN
핵심 아이디어: Agent0은 동일한 LLM 기반에서 두 에이전트를 생성하여 경쟁적인 피드백 루프에 강제로 진입시킵니다. 한 에이전트는 작업을 생성하고, 다른 에이전트는 생존을 위해 노력합니다. 이러한 지속적인 밀고 당기기는 어떤 정적 데이터 세트와도 비교할 수 없는 최첨단 난이도 문제를 생성합니다.
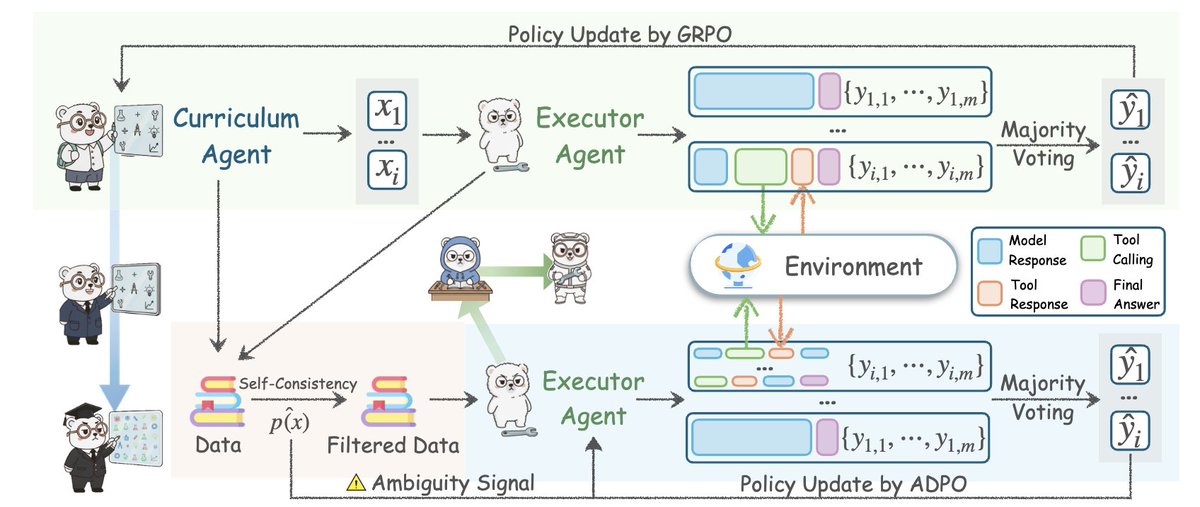
획기적인 발전은 자가 학습이 아니라 추론에 도구를 통합하는 데 있습니다. 실행 에이전트는 솔루션 내에서 실제 파이썬 코드를 실행하고, 출력을 얻고, 추론을 업데이트할 수 있습니다. 이를 통해 커리큘럼 에이전트는 도구를 사용해야 하는 질문을 생성하여 응답할 수 있습니다. 이는 선순환입니다.

그들은 자가 진화 에이전트의 가장 큰 실패 모드인 정체를 다루었습니다. 대부분의 에이전트는 현재 수준보다 약간 더 어려운 문제만 생성합니다. Agent0은 불확실성, 샘플링된 arxiv.org/abs/2511.16043 활용하여 실행 에이전트의 취약점을 탐지합니다. 전체 논문은 여기에서 읽을 수 있습니다: https://t.co/7UheEMgrBw

제 개인적인 이해로는 이 시스템이 본질적으로 LLM을 사용하여 두 에이전트가 경쟁하도록 구성하는 방식이며, 이는 일종의 GAN 사고 논리이기도 합니다. 다시 말해, 음과 양의 갈등을 끊임없이 해결하는 과정에서 발전이 이루어진다는 것입니다. 하지만 이 시스템이 제대로 작동하려면 에이전트에게 "도구를 탐색하고 생성하는" 능력을 부여하지 않을 수 없습니다. 이러한 능력이 있는 한, 에이전트는 강화학습을 통해 세상과 끊임없이 충돌하고 결국 문제에 대한 해결책을 찾을 수 있습니다. 이는 인간의 행동과 유사합니다.
마지막으로, 이 트윗을 읽어주셔서 감사합니다! AI 정보, 비즈니스 통찰력, 성장 전략을 알아보려면 @Yangyixxxx를 팔로우하세요. 이 콘텐츠가 마음에 드셨다면 첫 번째 트윗에 좋아요를 누르고 공유해 주시면 귀중한 정보를 더 많은 사람에게 전파할 수 있습니다.