OlmoRL 인프라는 Olmo 2보다 4배 더 빠르며 실험 실행 비용도 훨씬 저렴해졌습니다. 몇 가지 변경 사항은 다음과 같습니다. 1. 연속 배칭 2. 기내 업데이트 3. 활성 샘플링 4. 멀티스레딩 코드에 대한 많은 개선 사항
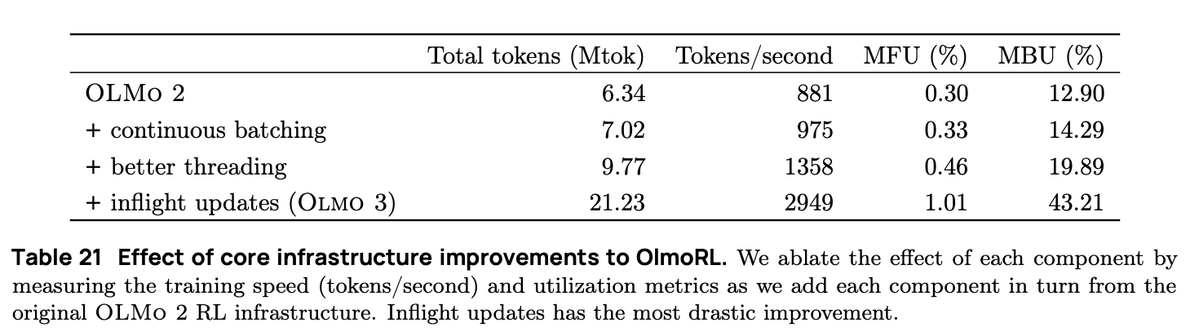
연속 배칭에서는 완전히 비동기식 생성 설정으로 전환합니다. 여기에는 프롬프트용 대기열 하나와 생성 결과용 대기열 하나가 있습니다. 우리의 액터는 완전히 비동기적으로 작동하며, 완료가 완료되면 계속해서 새로운 프롬프트를 가져와서 생성합니다.
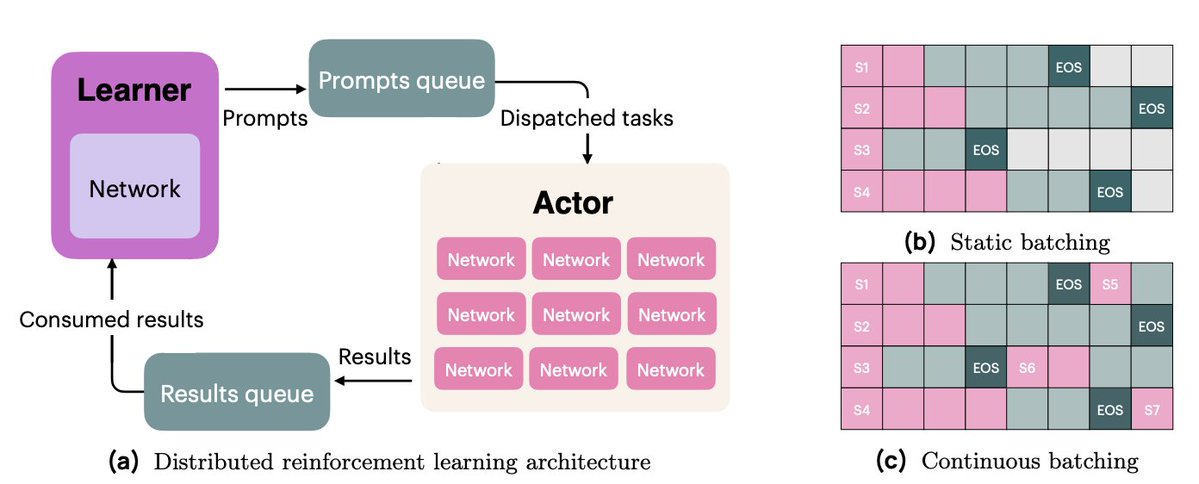
진행 중인 업데이트(PipelineRL, @alexpiche_, @DBahdanau 외)를 사용하면 생성 도중에 액터를 업데이트합니다. 가중치를 업데이트하기 위해 생성 대기열을 비울 필요가 없으므로 시스템이 훨씬 더 빠릅니다(정적 배칭과 동일한 문제).

능동 샘플링(@mnoukhov의 새로운 기여)은 GRPO에서 발생하는 저주받은 문제를 해결합니다. 이 문제에서는 보상의 분산이 0(따라서 이점이 0이고 기울기가 0)인 그룹이 필터링되어 배치 크기가 학습 단계에 따라 달라집니다.
이전 논문들은 필터링 후에도 항상 충분한 그룹이 확보되기를 바라며, 필요한 그룹의 3배를 샘플링하여 배치 크기 변동 문제를 해결했습니다. 하지만 Michael은 대신, 비상수 보상 그룹이 가득 찰 때까지 기다렸다가 학습하도록 코드를 변경했습니다.
이를 위해서는 배우와 학습자의 동기화를 유지하기 위해 까다로운 작업이 필요했습니다.
마지막으로, 액터가 비동기적으로 작동할 수 있도록 동기화를 줄이고 코드베이스를 리팩토링하는 데 엄청난 시간을 투자했습니다. 이 작업에는 Python의 threading 및 asyncio API를 활용한 광범위한 엔지니어링 작업이 포함되었습니다.
저희의 RL 인프라 작업은 저 자신, @hamishivi, @mnoukhov, @saurabh_shah2, @tyleraromero의 기여로 이루어진 그룹 작업이었고, @vwxyzjn이 남긴 기반을 바탕으로 구축되었습니다.
저희의 업무에 대해 더 자세히 알아보려면 논문, 블로그 게시물, 관련 작업물, 그리고 오전 9시(태평양 표준시)에 시작되는 라이브 스트리밍을 확인해 주세요.