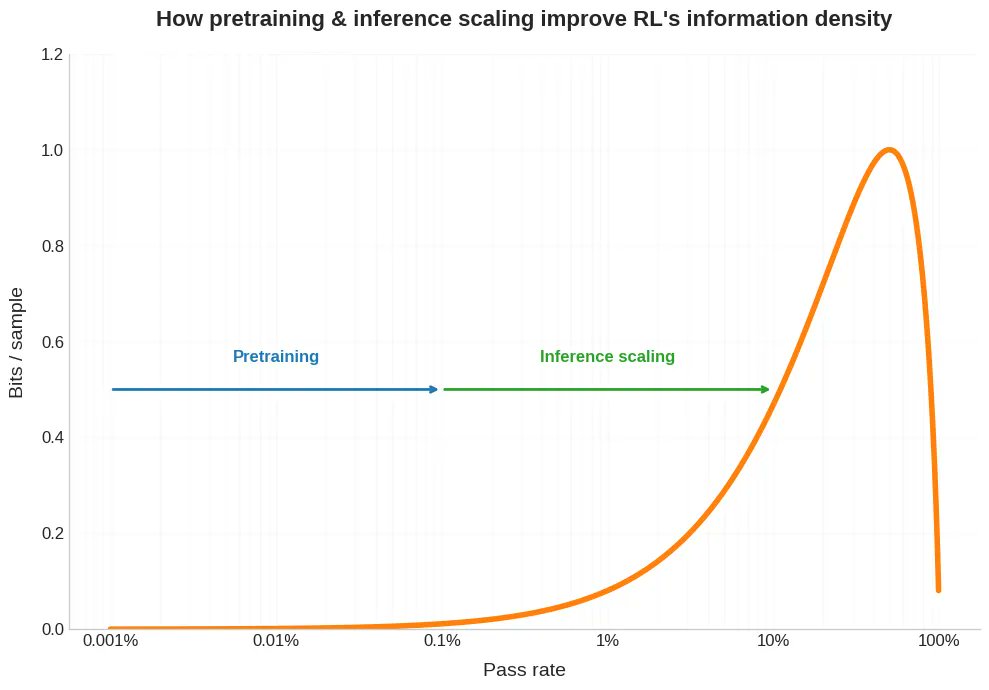
새로운 블로그 게시물입니다. 최근 사람들은 사전 학습보다 강화학습에서 단일 샘플을 얻는 데 훨씬 더 많은 컴퓨팅이 필요하다는 점에 대해 이야기해 왔습니다. 하지만 이것은 문제의 절반일 뿐입니다. 실제 현실에서 값비싼 샘플은 보통 훨씬 적은 비트를 제공합니다. 이는 RLVR이 얼마나 잘 확장될 수 있는지에 영향을 미치며, 자기 플레이와 커리큘럼 학습이 RL에 왜 그렇게 도움이 되는지, RLed 모델이 왜 이상하게 들쭉날쭉한지, 그리고 인간이 무엇을 다르게 하는지에 대해 어떻게 생각할 수 있는지 이해하는 데 도움이 됩니다. 아래 링크를 참조하세요.