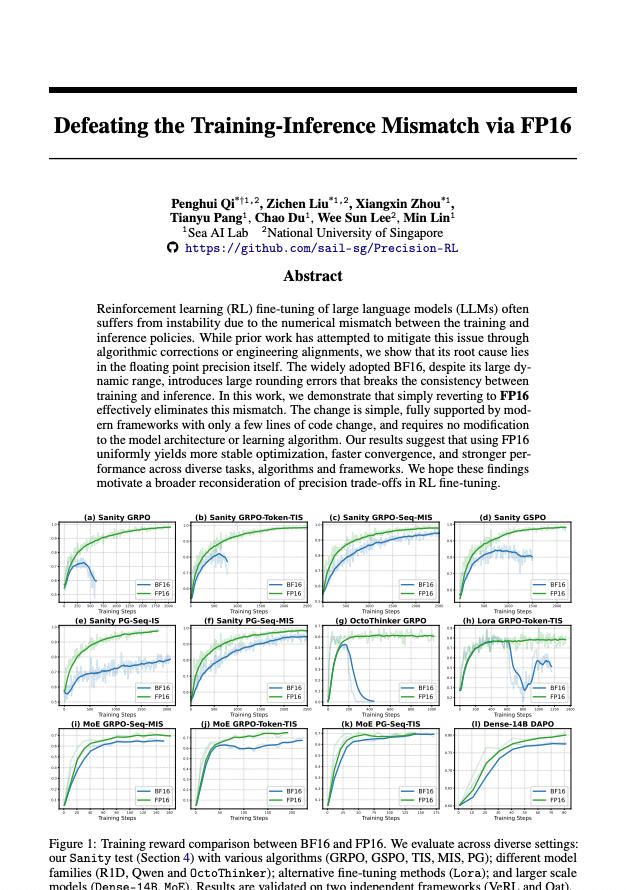
#8 - FP16을 통한 학습-추론 불일치 해소 링크 - https://t.co/rFKo8w36nc 6번과 7번에서 다룬 것과 같은 주제arxiv.org/abs/2510.26788 논의를 따라잡으려면 이 글을 꼭 읽어야 합니다. 이전 연구에서는 중요도 샘플링 해킹이나 대규모 엔지니어링을 통해 커널을 더 잘 정렬하여 이러한 학습-추론 불일치 문제를 해결하려고 시도했습니다. 어느 정도 도움이 되지만: >추가 컴퓨팅 비용(추가 포워드 패스) > 하나를 최적화하고 다른 하나를 배포한다는 사실이 실제로 해결되지 않습니다. >아직도 불안정할 수 있음 그래서 논문의 주제는 진짜 악당은 bf16이다. fp16을 사용하세요. 저는 트위터에 이것에 대한 여러 밈을 만들면서 정말 재미있었습니다.
#9 - LLM을 위한 2차 최적화의 잠재력: 전체 가우스-뉴턴을 사용한 연구 링크 - https://t.co/wlkpXHz4sf 이 논문에서는 모든 사람이 사용하는 약화된 근사치 대신 실제 가우arxiv.org/abs/2510.09378 빠르게 훈련할 수 있다는 것을 보여줍니다. 전체 GN은 SOAP에 비해 훈련 단계 수를 약 5.4배, 뮤온에 비해 16배 줄입니다. 그들은 이 주장에 대해 이론적인 보장을 하지 않으며 대규모로 테스트도 하지 않았습니다(매개변수 1억 5천만 개만).
