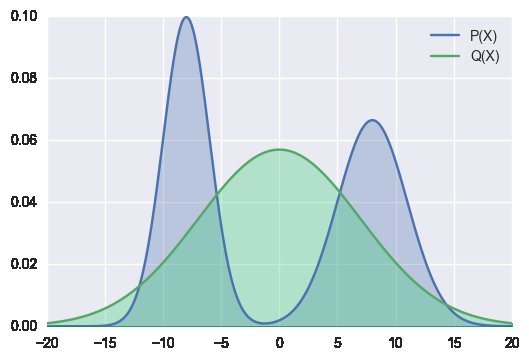
왜 우리는 전방 KL(왼쪽 그림)을 사용하여 데이터/모델로부터 근사 분포를 수용할까요? (오른쪽 그림)과 비슷한 알고리즘을 향해 노력해보는 건 어떨까요?

아니면 전체 분포에 대한 것이 아니라 최근성 편향으로 KL을 최소화하고 있기 때문에 이미 그렇게 하고 있는 걸까요?
스레드를 불러오는 중
깔끔한 읽기 화면을 위해 X에서 원본 트윗을 가져오고 있어요.
보통 몇 초면 완료되니 잠시만 기다려 주세요.
트윗 2개 · 2025. 11. 2. 오전 7:14
왜 우리는 전방 KL(왼쪽 그림)을 사용하여 데이터/모델로부터 근사 분포를 수용할까요? (오른쪽 그림)과 비슷한 알고리즘을 향해 노력해보는 건 어떨까요?
아니면 전체 분포에 대한 것이 아니라 최근성 편향으로 KL을 최소화하고 있기 때문에 이미 그렇게 하고 있는 걸까요?