🚨 DeepSeek이 방금 엄청난 일을 해냈어요. 그들은 긴 텍스트를 시각적 토큰으로 압축하고, 문단을 문자 그대로 픽셀로 변환하는 OCR 시스템을 구축했습니다. 그들의 모델인 DeepSeek-OCR은 10배 압축률에서 97%의 디코딩 정확도를 달성하고, 20배 압축률에서도 60%의 정확도를 유지합니다. 즉, LLM에 필요한 토큰의 일부만 사용하여 하나의 이미지로 전체 문서를 표현할 수 있습니다. 더 놀라운 점은 무엇일까요? GOT-OCR2.0과 MinerU2.0보다 토큰 사용량이 최대 60배 적고, 단일 A100으로 하루 20만 페이지 이상을 처리할 수 있다는 것입니다. 이를 통해 AI의 가장 큰 문제 중 하나인 장기 맥락 비효율성을 해결할 수 있습니다. 더 긴 시퀀스에 더 많은 비용을 지불하는 대신, 모델은 곧 텍스트를 읽는 대신 텍스트를 보게 될 것입니다. 컨텍스트 압축의 미래는 전혀 텍스트와 관련되지 않을 수도 있습니다. 광학적일 수도 있어요 👁️ github. com/deepseek-ai/DeepSeek-OCR
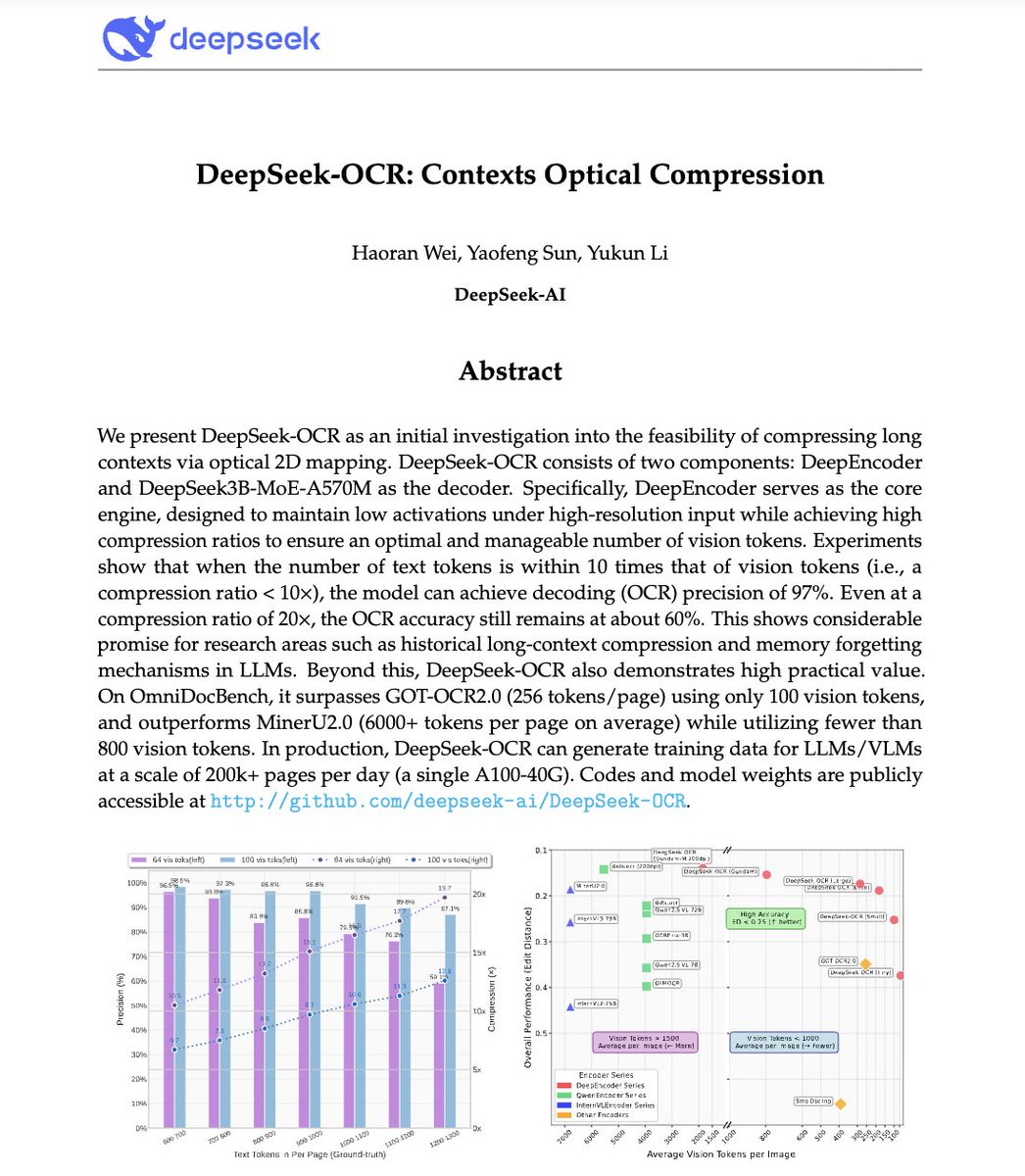
1. 비전-텍스트 압축: 핵심 아이디어 LLM은 토큰 사용량이 문서 길이에 따라 2차적으로 증가하기 때문에 긴 문서를 다루는 데 어려움을 겪습니다. DeepSeek-OCR은 이를 뒤집습니다. 텍스트를 읽는 대신 전체 문서를 시각 토큰으로 인코딩하고, 각 토큰은 압축된 시각 정보를 나타냅니다. 결과: GPT-4에서 1페이지를 처리하는 데 걸리는 시간과 동일한 예산으로 10페이지 분량의 텍스트를 처리할 수 있습니다.

2. DeepEncoder - 광학 압축기 스타를 만나보세요: DeepEncoder. 인식을 위한 SAM과 전역적 시각을 위한 CLIP이라는 두 개의 백본을 사용하며, 16배 합성 압축기로 연결됩니다. 이를 통해 활성화 메모리를 폭발시키지 않고도 고해상도 이해를 유지할 수 있습니다. 인코더는 수천 개의 이미지 패치를 수백 개의 컴팩트한 비전 토큰으로 변환합니다.

3. 멀티 해상도 "건담" 모드 문서는 송장 ≠ 청사진 ≠ 신문 등 다양합니다. 이를 처리하기 위해 DeepSeek-OCR은 소형, 저해상도, 대형, 건담 등 여러 가지 해상도 모드를 지원합니다. 건담 모드는 로컬 타일과 512×512에서 1280×1280까지 효율적으로 확장되는 글로벌 뷰를 결합합니다. 하나의 모델, 여러 가지 해결책, 재교육 없음.

4. 데이터 엔진 OCR 1.0~2.0 그들은 단순히 텍스트 스캔으로만 훈련하지 않았습니다. DeepSeek-OCR의 데이터는 다음과 같습니다. • 100개 언어로 3,000만 개 이상의 PDF 페이지 • 10M 자연 장면 OCR 샘플 • 10M 차트 + 5M 화학식 + 1M 기하학 문제 단순히 읽는 것이 아니라 과학적 도표, 방정식, 레이아웃을 분석하는 것입니다.

5. 이것은 "그저 또 다른 OCR"이 아닙니다. 이는 컨텍스트 압축에 대한 개념 증명입니다. 텍스트를 10배 적은 토큰으로 시각적으로 표현할 수 있다면 LLM은 장기 기억과 효율적인 추론을 위해 동일한 아이디어를 활용할 수 있습니다. GPT-5가 1M 토큰 문서를 100K 토큰 이미지 맵으로 처리한다고 상상해보세요.

더 이상 프롬프트를 작성하는 데 시간을 낭비하지 마세요 → 10,000개 이상의 바로 사용 가능한 프롬프트 → 몇 초 만에 나만의 것을 만들어 보세요 → 평생 이용 가능. 한 번만 결제하세요. 사본을 받으세요 👇