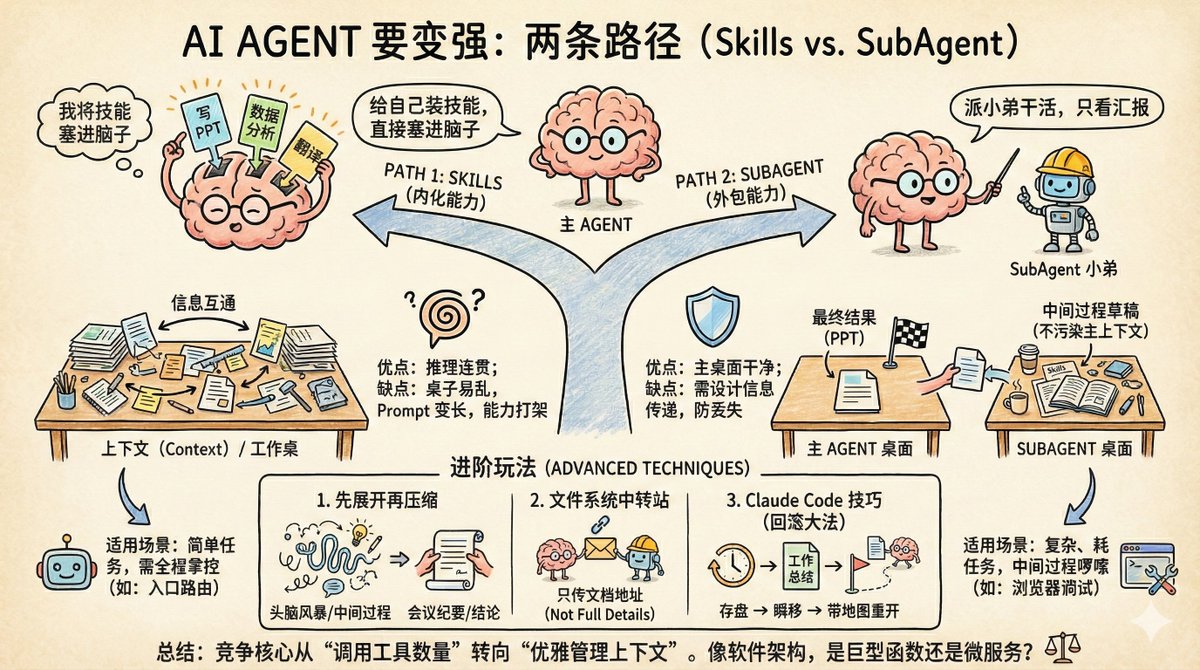
AI エージェントが強くなるには、まったく異なる 2 つの方法があります。 1つは「スキル」で、これは自分自身にスキルを身につけさせ、新しい能力を脳に直接詰め込むことを意味します。 もう 1 つのアプローチは、SubAgent です。これは、レポートのみを参照しながら、部下に作業を任せるようなものです。 どちらのアプローチもエージェントの性能を高めるように見えますが、適用可能なシナリオは異なります。間違ったアプローチを採用すると、エージェントは使用すればするほど動作が遅くなり、混乱が生じる可能性があります。 スキルはメインエージェントのプラグインのようなものです。 例えば、チャットしかできないエージェントにPowerPointプレゼンテーションを作成させたい場合、SkillsはPowerPoint作成機能の説明、ツールの使い方、重要な注意事項をメインエージェントのコンテキストに埋め込みます。メインエージェントはコンテキストを通じてこのスキルを学習し、独自にPowerPointプレゼンテーションを作成できるようになります。 2 番目のタイプはサブエージェントと呼ばれ、アウトソーシングのようなものです。 同様に、PowerPointプレゼンテーションを作成する場合、サブエージェントアプローチは次のように機能します。メインエージェントは、プレゼンテーション作成専用のサブエージェントにタスクを割り当てます。サブエージェントは、タスクを独立して完了し、結果を送信します。メインエージェントは実際の実行には関与せず、タスクの割り当てと受け入れテストのみを担当します。 一つは内製化された能力、もう一つは外注された能力です。どちらもタスクを処理できるように見えますが、違いは何でしょうか? 違いはコンテキスト管理にあります。コンテキストは AI のメモリです。 AIのコンテキストは作業台に例えることができます。机のサイズは固定されており、机の上に物を置くほど、必要な書類を見つけるのが難しくなります。これがコンテキスト容量の問題です。 スキルモードでは、すべての能力の説明が同じテーブルに配置されます。利点は情報共有です。メインエージェントはすべての中間結果を確認でき、推論プロセスに一貫性が保たれます。欠点は、テーブルがすぐに乱雑になり、プロンプトが長くなり、能力が競合する可能性があり、AIが混乱し始めることです。 サブエージェントモードでは、サブエージェントは別のテーブルで作業します。作業が完了すると、結果を引き継ぎますが、プロセス中に生成されたすべてのドラフトと中間ファイルはそのまま残されます。メインエージェントのデスクトップはクリーンな状態のままです。ただし、情報の受け渡しは慎重に設計する必要があります。そうしないと、引き継ぎ中に重要な情報が失われる可能性があります。 これが文脈汚染の問題です。この汚染は誇張された比喩ではなく、エンジニアリングにおける真のボトルネックなのです。 どの方法をいつ使用すればよいですか? 判断基準は実際には非常にシンプルです。サブタスクの複雑さと、タスク完了プロセス中に生成される情報が必要かどうかです。 スキルは、タスク自体がそれほど複雑ではないシナリオや、メインエージェントに完全な制御権限を与える必要があるシナリオに適しています。 例えば、エージェントはエントリポイントルートとして機能し、ユーザーのリクエストに基づいて様々な「シナリオモード」をロードします。例えば、YouTubeの要約モードやレポート作成モードなどです。スキルの遅延ロード機能はまさにこの点で威力を発揮します。最初はアビリティ名と説明のみをロードし、スキルが実際に必要になった時にのみ詳細な説明をロードします。これは、各ツールの詳細なドキュメントをコンテキストに詰め込むMCPとは異なります。 SubAgent は、サブタスクが重く、時間がかかり、中間プロセスが冗長なシナリオに適しています。 最も典型的な例はブラウザのデバッグツールです。Chrome DevToolsのMCP機能は強力ですが、ドキュメントが膨大すぎるため、メインエージェントに含めるとコンテキストを著しく消費してしまいます。これをサブエージェントとしてカプセル化することで、「ログを確認してスクリーンショットを撮り、分析する」という指示だけで、処理が実行され、分析結果が返されます。スクリーンショット、DOMツリーの詳細、ネットワークリクエストの詳細はすべてサブエージェントに保持され、メインエージェントのコンテキストを汚染することはありません。 高度なゲームプレイ 興味深いことに、スキルモードとサブエージェントモードは組み合わせることができます。このテクニックは@yan5xuさん(https://t.co/uSkwSUvNiJ)から学びました。 最初のアプローチは、「最初に展開し、次に圧縮する」と呼ばれます。 例えば、2時間のブレインストーミングセッションがあり、ホワイトボードには草稿、議論、却下された解決策が山積みになっているとします。しかし、最終的に議事録に書き込まれた結論はたった3つだけです。これらの中間プロセスは結論に至る上で重要ですが、後でそれを実行する人にとっては単なるノイズに過ぎません。 エージェントもこのように動作します。メインエージェントは特定のスキルの必要性を検知し、それをロードし、一連の操作を実行して結果を取得します。その後、「スキルのロード」から「結果の取得」までのプロセス全体が集約され、最終的な結論のみが保持されます。後続の推論処理では、会議を開催しながら議事録のみを保存するようなものです。 2 番目のアプローチは、ファイル システムを「転送ステーション」として使用することです。 アウトソーシングチームを管理していると想像してみてください。要件の詳細をすべてWeChatのメッセージ1つに詰め込むようなことはしないでしょう。代わりに、「要件ドキュメントはこのリンクにあります。ご確認ください」と言うでしょう。同様に、アウトソーシングチームはソースコードをそのままコピー&ペーストするのではなく、「コードはこのリポジトリにあり、デプロイメントドキュメントはこちらです」と言うでしょう。 エージェントも同様に連携できます。メインエージェントがタスクを委任する際、コマンドには長々とした背景情報は含めず、代わりにドキュメントとして保存し、1つのアドレスのみを送信します。サブエージェントも同様に応答し、「完了/行き詰まっている/判断が必要」といった簡単なステータスサマリーと、詳細なドキュメントアドレスを送信します。メインエージェントは状況に応じて、クリックして詳細を確認するかどうかを判断します。これにより、双方にとって状況が簡潔になります。 3 番目のタイプは、Claude Code による実践的なテクニックです。 コンテキストがほぼ使い果たされたら、クロードに現在完了している作業をドキュメントにまとめさせます。その後、巻き戻し機能を使用してタスク開始前の状態にロールバックし、「このタスクを完了し、このファイルに記録しました」と伝えます。 これは何に似ているでしょうか?マラソンを走っていて、ゴールライン付近で疲れ果てていることに気づくようなものです。そこで、既に走ったルートを地図に描き、保存し、エネルギーに満ち溢れた状態でスタート地点に「テレポート」して戻り、「行き方はわかっている。地図はここにある」と言います。コンテキストは消去されますが、結果は保存されます。この方法により、コンテキストが切れる前に状況を挽回することができます。 やっと エージェント間の競争は、「どれだけ多くのツールを呼び出せるか」から「それらのツールをいかにエレガントに管理するか」へと移行しています。 多くの人が最新のエージェントフレームワークや最先端の機能拡張を追い求めますが、最も根本的な問題を見落としています。AIのワーキングメモリは限られており、それをどのように整理するかによって、AIが実行できる複雑な処理が決まるのです。スキルとサブエージェントは互いに排他的な選択肢ではなく、適切なコンテキストで使用したときにのみ価値を発揮する2つのツールです。 結局のところ、エージェント アーキテクチャ設計とソフトウェア アーキテクチャ設計には多くの類似点があります。 ロジックを巨大な関数で記述する必要がありますか、それともモジュール式のマイクロサービスに分割する必要がありますか? グローバル変数を共有する方が簡単でしょうか、それとも厳密な分離を通じてクリーンさを維持する方が簡単でしょうか? これらの古い問題が新たな形で再び現れました。