唐潔(@jietang)は清華大学の教授であり、GLMシリーズモデルの開発元であるZhipuのチーフAIサイエンティストです。彼は中国における大規模モデルに関する最も詳しい知識を持つ人物の一人でもあります。彼は最近、2025年の大規模モデルに関する自身の見解を長文でWeiboに投稿しました(コメントを参照)。 興味深いことに、タン・ジエ氏とアンドレイ・カルパシー氏は多くの点で見解を共有していますが、同時に異なる重点を置いている点もあります。この二人のトップエキスパートの視点を並べて見ることで、より包括的な全体像が見えてきます。 内容はかなり長いのですが、冒頭で注目したい一文があります。 AIモデルの応用における第一原則は、新しいアプリを開発することではなく、その本質はAGIが人間の仕事を代替することです。したがって、様々な仕事を代替できるAIを開発することが、その応用の鍵となります。 AIアプリケーションを開発しているなら、この言葉を繰り返し考えてみてください。「AIアプリケーションの第一原則は、新しい製品を作ることではなく、人間の仕事を置き換えることです。」これを理解すれば、多くのことの優先順位が明確になるでしょう。 唐潔の核心的な議論には7つの論理の層がある。 --- レベル 1: 事前のトレーニングで彼が死んだわけではなく、ただ彼が唯一の主人公ではなくなっただけです。 事前トレーニングは、モデルが世界に関する知識と基本的な推論能力を獲得するための基盤となります。 より多くのデータ、より大きなパラメータ、そしてより集中的な計算こそが、モデルの知能を向上させる最も効率的な方法であり続けています。これは成長期の子供のようなものです。十分な量の食物(計算能力)と栄養(データ)が必要です。これは避けられない物理法則です。 しかし、知能だけでは不十分です。現在のモデルには問題があります。それは「アンバランス」になりがちなのです。ベンチマークスコアを向上させるために、多くのモデルは特定の問題に焦点を当てているため、複雑な現実世界のシナリオでは効果が低下しています。これは、教科書に載っていない問題に対処するために、9年間の義務教育(事前訓練)を受けた子供を実際の職場に放り込むようなものです。真のスキルはそこで培われるのです。 したがって、次の焦点は「トレーニング中期とトレーニング後」です。この2つの段階は、モデルの能力、特にロングテールシーンにおけるアライメント能力を「活性化」する役割を果たします。 ロングテールシナリオとは何でしょうか?それは、一般的ではないものの、実際に存在するニーズのことです。例えば、弁護士が特定の特別な契約書を作成するのを支援する、医師が希少疾患の画像を分析するのを支援するなどです。これらのシナリオは一般的なテストセットのごく一部を占めるに過ぎませんが、現実世界のアプリケーションでは非常に重要です。 一般的なベンチマークはモデルのパフォーマンスを評価するものですが、多くのモデルでは過学習につながる可能性があります。これは、Karpathy氏の「テストセットでのトレーニングは新しい芸術である」という見解と一致しています。誰もがランキングを上げようと努力していますが、リーダーボードで高得点を獲得することと現実世界の課題を解決できることは必ずしも同じではありません。 --- 第2層:エージェントは「学生」から「社会人」への移行を表します。 唐潔は鮮明な例え話をした。 エージェント機能がなければ、大規模モデルは単なる「理論的な博士号」に過ぎません。たとえポスドクレベルに達し、どれだけ多くの本を読んだとしても、問題を解決できなければ、単なる知識の器に過ぎず、生産性を生み出すことはできません。 このアナロジーは正確です。事前学習は授業に出席すること、強化学習は問題演習に似ていますが、これらはまだ「学習段階」にあります。エージェントはモデルを真に「機能させる」ための鍵であり、現実世界に参入して実用的な価値を生み出すための入り口です。 異なるエージェント環境間での一般化と転移は容易ではありません。コード環境で培ったスキルがブラウザ環境ではうまく機能しない可能性があります。現時点で最もシンプルなアプローチは、より多くの環境からデータを継続的に蓄積し、それぞれの環境に合わせた強化学習を行うことです。 以前は、エージェントを開発する際には、モデルに様々なツールを付加していました。現在は、これらのツールの使用から得られたデータをモデルの「DNA」に直接組み込んでトレーニングするのが主流となっています。 これは少し馬鹿げているように聞こえるかもしれないが、確かに現時点では最も効果的な方法だ。 カルパシー氏は、Agentを今年の最も重要な変更点の一つとして挙げました。彼はClaude Code氏を例に挙げ、Agentは「コンピュータの中に存在し」、ツールを呼び出したり、ループを実行したり、複雑な問題を解決したりできるべきだと強調しました。 --- 第 3 層: 記憶は基本的なニーズですが、それをどのように達成するかはまだ不明です。 唐傑氏はメモリについてかなりの時間を割いて議論しました。彼は、モデルを現実世界の環境に実装するにはメモリが不可欠だと考えています。 彼は人間の記憶を4つの層に分けました。 - 前頭前皮質に対応する短期記憶 - 海馬に相当する中期記憶 長期記憶は大脳皮質にあります。 - ウィキペディアや歴史記録に相当する人類の歴史的記憶 AI もこのメカニズムを模倣する必要があります。大規模なモデルは次のようなものに対応する可能性があります。 - コンテキストウィンドウ → 短期記憶 - RAG検索→中間記憶 - モデルパラメータ → 長期記憶 一つのアプローチは「圧縮記憶」であり、重要な情報を簡潔かつシンプルな形式でコンテキスト内に保存する。現在の「超長期コンテキスト」は短期記憶のみを対象としており、実質的には使用可能な「付箋」を長くしているに過ぎない。将来、コンテキストウィンドウが十分に長ければ、短期、中期、長期の記憶をすべて実現できる可能性がある。 しかし、さらに難しい問題があります。モデル自身の知識をどのように更新するか?パラメータをどのように変更するか?これは未解決の問題です。 --- 4 番目の層: オンライン学習と自己評価は、次のスケーリングパラダイムになる可能性があります。 この部分は、唐潔の視点が最も前向きな部分です。 現在のモデルは「オフライン」、つまり学習済みではあるものの、変化しない状態です。そのため、いくつかの問題が発生します。モデルは自律的に反復処理を実行できず、再学習によってリソースが浪費され、多くのインタラクティブデータが失われます。 理想的には、モデルはオンラインで学習し、使用するたびに賢くなる必要があります。 しかし、これを実現するには前提条件があります。モデルは、それが正しいかどうかを知る必要があります。これは「自己評価」と呼ばれます。モデルが自身の出力の品質を判断できれば、たとえそれが確率的な判断であっても、最適化の目標を認識し、自己改善することができます。 唐傑氏は、モデルの自己評価メカニズムの構築は困難な問題であるものの、それが次世代のスケーリングパラダイムの方向性となる可能性もあると考えている。彼は継続学習、リアルタイム学習、オンライン学習といったいくつかの用語を用いた。 これは、Karpathy氏がRLVRについて指摘した点と一致しています。RLVRが効果的なのは、「検証可能な報酬」を提供することで、モデルが正しいかどうかを判断できるからです。このメカニズムをより多くのシナリオに一般化できれば、オンライン学習が可能になるかもしれません。 --- 第 5 層: AI 応用の第一原則は「仕事の代替」です。 私に最もインスピレーションを与えたのは次の一文です。 AIモデルの応用における第一原則は、新しいアプリを開発することではなく、その本質はAGIが人間の仕事を代替することです。したがって、様々な仕事を代替できるAIを開発することが、AIの応用の鍵となります。 AIの本質は、新しいアプリを作成することではなく、人間の仕事を置き換えることです。 2つのパス: 1. これまで人間の介入を必要としていたソフトウェアを AI に変換します。 2. 特定の人間の仕事に合わせた AI ソフトウェアを作成し、人間の労働者を直接置き換える。 チャットはすでに検索の一部を代替し、感情的なやり取りも取り入れています。次のステップは、カスタマーサービス、ジュニアプログラマー、データアナリストの代替です。 したがって、2026年のブレークスルーポイントは「AIがさまざまな仕事を代替する」ことにある。 起業家は「ユーザーのためにどんなソフトウェアを開発したいか」ではなく、「上司が特定のポジションの人件費を削減するのに役立つ、どんな AI 従業員を作りたいか」を考えるべきです。 つまり、常に新しい「AI+X」製品を作ることを考えるのではなく、まずは人間のどの仕事が代替可能かを考え、そこから逆算して製品の形を決めていくのです。 これは、Karpathy氏が「Cursor for X」について述べたことと一致する。もしCursorが本質的に「プログラマーの仕事のAI版」であるならば、同様のものが様々な業界で登場するだろう。 --- 第 6 層: ドメイン全体のモデルは「誤った命題」です。 この見解は一部の人々を不快にさせるかもしれないが、Tang Jie氏は率直にこう述べている。「ドメイン特化型モデルは誤った命題だ。AGIについて語るなら、『ドメイン特化型AGI』の意味は何だろうか?」 ドメイン特化型の大規模モデルが存在する理由は、アプリケーション企業がAIモデル企業の前で負けを認めたくないため、ドメインノウハウで堀を築きAIをツールとして飼いならしたいと考えているからです。 しかし、AIの本質は「津波」であり、あらゆるものを巻き込んでいく。特定の分野の企業は、必然的に競争優位性から脱却し、AGIの世界に引き込まれるだろう。彼らのドメインデータ、プロセス、エージェントデータは、徐々にメインモデルに組み込まれていくだろう。 もちろん、ドメインモデルはAGIが実現するまで長い間存在するでしょう。しかし、その期間はどれくらいになるのでしょうか?AIの発展があまりにも速いため、予測は困難です。 --- 第 7 層: マルチモーダルおよび具現化されたインテリジェンス - 明るい未来だが困難な道。 マルチモーダルコンピューティングは確かに未来の技術です。しかし、現状の問題は、AGIの知能限界を高める上で、マルチモーダルコンピューティングが限られた貢献しか果たしていないことです。 テキスト、マルチモーダル、そしてマルチモーダル生成は、それぞれ個別に開発する方が効率的かもしれません。もちろん、これら3つを組み合わせるには、勇気と資金が必要です。 具現化された知能(ロボット)はさらに困難です。課題はエージェントの場合と同じです。つまり、汎用性です。ロボットにシナリオAで動作するように教えたのに、別のシナリオでは動作しません。どうすればよいでしょうか?データの収集と統合は困難で、コストもかかります。 何をすべきか?データを収集するか、それともデータを統合するか。どちらも容易ではなく、コストもかかる。しかし逆に、データ規模が大きくなり、汎用的な機能が登場すると、参入障壁は自然に形成される。 見落とされがちなもう一つの問題は、ロボット自体にも問題があるということです。不安定性と頻繁な故障は、身体化された知能の発展を制限しているハードウェアの問題です。 唐潔氏は、2026年までにこれらの分野で大きな進歩が遂げられるだろうと予測している。 --- Tang Jie 氏の記事を全体像に結び付けると、かなり明確なロードマップが明らかになります。 現在、事前トレーニング済みのスケーリングはまだ効果的ですが、アライメントとロングテール機能にさらに重点を置く必要があります。 最近、エージェントは重要なブレークスルーとなり、モデルを「話す」から「実行する」へと進化させました。 中期的には、記憶システムとオンライン学習が必須のコースであり、モデルは自己評価と反復を学習する必要があります。 長期的には、ジョブの代替がアプリケーションの本質であり、ドメインの堀は AGI によって突破されるでしょう。 長期的には、マルチモーダルアプローチと具現化されたアプローチは、技術とデータの成熟を待ちながら、独立して発展していくでしょう。 --- 唐潔氏とカルパティ氏の視点を比較すると、いくつかの共通点が見られます。 まず、2025年の核心的な変化は、研修パラダイムを「事前研修中心」から「多段階連携」へとアップグレードすることです。 2 番目に、エージェントはモデルにとって学習から実行への重要な飛躍となるマイルストーンです。 3つ目は、ベンチマークスコアと実際の能力の間にギャップがあり、この問題がますます注目を集めていることです。 4 番目に、AI アプリケーションの本質は、アプリを作成するためだけにアプリを作成することではなく、人間の仕事を置き換えたり強化したりすることです。 焦点の違いも興味深い。カルパシー氏は「AIインテリジェンスはどのような形をしているのか?」という哲学的な問いにより関心を寄せているのに対し、タン・ジエ氏は「モデルを現実世界のシナリオにどのように実装するか?」という工学的な問題により関心を寄せている。一方は「理解」を重視し、もう一方は「実装」を重視している。 両方の視点が必要です。明確な理解があって初めて、私たちが正しい方向に進んでいるかどうかを知ることができます。そして、確かなエンジニアリングがあって初めて、アイデアを現実のものにすることができるのです。 2026年は素晴らしい年になるでしょう。
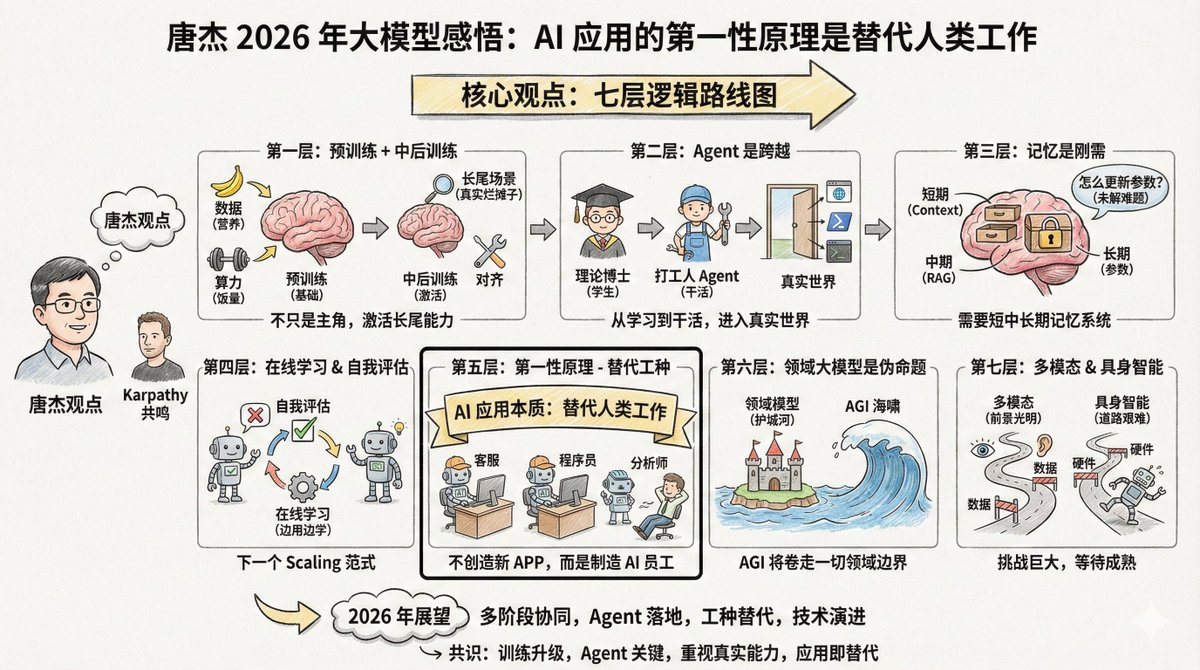
以下の内容は唐潔のWeiweibo.com/2126427211/QjI…/AOdkBXNIey 皆さんのお役に立てればと思い、最近の洞察をいくつかシェアしたいと思います。 事前学習により、大規模モデルは世界に関する常識的な知識を獲得し、基本的な推論能力を身につけることができます。より多くのデータ、より大きなパラメータ、そしてより飽和した計算は、ペデスタルモデルをスケールさせる最も効率的な方法です。 アライメントの有効化と推論機能の強化、特により包括的なロングテール機能の有効化は、モデルのパフォーマンスを確保するためのもう一つの鍵です。一般的なベンチマークはモデルの全体的なパフォーマンスを評価しますが、多くのモデルで過学習につながる可能性があります。現実世界のシナリオにおいて、モデルはロングテールの現実世界のシーンをより迅速かつ正確にアライメントし、リアリティを高めるにはどうすればよいでしょうか?トレーニングの途中と後に、より多くのシナリオで迅速なアライメントと強力な推論機能を実現します。 エージェント機能は、モデル機能拡張におけるマイルストーンであり、AIモデルを現実世界(仮想/物理)に導入するための鍵となります。エージェント機能がなければ、大規模モデルは(理論学習)段階にとどまり、人が博士号を取得するまで学習を続けるのと同じように、知識を蓄積するだけで生産性向上には繋がらないでしょう。以前は、エージェントはモデルアプリケーションを通じて実装されていましたが、現在では、モデルがエージェントデータをトレーニングプロセスに直接統合できるようになり、汎用性が向上しています。しかし、異なるエージェント環境間での一般化と転送が容易ではないという課題が残っています。したがって、最も簡単な解決策は、異なるエージェント環境からのデータを継続的に増やし、それらの環境に合わせた強化学習を実装することです。 モデルメモリの実現は不可欠であり、あらゆるモデルを現実世界の環境に適用するには必須の機能です。人間の記憶は、短期(前頭前皮質)、中期(海馬)、長期(分散大脳皮質)、そして歴史的(ウィキペディアや歴史書)の4つの段階に分けられます。大規模モデルがどのようにして異なる段階にわたる記憶を実現するかが重要です。コンテキスト、時間枠、そしてモデルパラメータは、人間の記憶の異なる段階に対応している可能性がありますが、それをどのように実現するかが鍵となります。1つのアプローチは、メモリ圧縮、つまりコンテキストを単純に保存することです。大規模モデルが十分に長いコンテキストをサポートできれば、短期、中期、長期の記憶を実現することは事実上可能になります。しかし、モデルの知識を反復処理し、モデルパラメータを変更することは依然として大きな課題です。 - オンライン学習と自己評価。記憶メカニズムの理解が進むにつれ、オンライン学習が重要な焦点となります。現在の大規模モデルは定期的に再学習が行われていますが、これにはいくつかの問題があります。モデルは真の反復処理が不可能であり、自己学習と自己反復は次の段階では必然的に可能となります。また、再学習は無駄が多く、多くのインタラクティブデータが失われることになります。したがって、オンライン学習をどのように実現するかが重要であり、自己評価はオンライン学習の重要な側面です。モデルが自己学習を行うには、まずそれが正しいか間違っているかを知る必要があります。もしモデルが(たとえ確率的であっても)知ることができれば、最適化の目的を理解し、自己改善することができます。したがって、モデルの自己評価メカニズムの構築は課題です。これは、次のスケーリングパラダイムとなる可能性もあります。継続学習/リアルタイム学習/オンライン学習? 最後に、大規模モデル開発がエンドツーエンド化していくにつれ、モデル開発と応用の融合は不可避となっています。AIモデル応用の主眼は、新しいアプリの開発ではなく、AIが人間の仕事を代替することです。したがって、様々な仕事を代替するAIの開発が、その応用の鍵となります。チャットは検索を部分的に代替し、ある意味では感情的なインタラクションを組み込んでいます。来年は、AIが様々な仕事を代替する飛躍的な年となるでしょう。 - 最後に、マルチモーダリティと身体性について議論しましょう。マルチモーダリティは間違いなく有望な未来ですが、現状の問題は、AGIの知能の上限に大きく貢献しておらず、汎用AGIの知能の上限は正確には不明であるということです。おそらく最も効果的なアプローチは、テキスト、マルチモーダリティ、マルチモーダル生成をそれぞれ個別に開発することです。もちろん、これら3つを適度に組み合わせて研究することで、全く異なる能力を発見できる可能性がありますが、そのためには勇気と相当な資金援助が必要です。 同様に、エージェントを理解していれば、身体性知能の問題点がどこにあるかが分かるでしょう。一般化は非常に困難ですが(必ずしもそうとは限りませんが)、少量のサンプルで汎用的な身体能力を活性化することは事実上不可能です。では、どうすれば良いのでしょうか?データの収集、あるいはデータの統合は、容易でも安価でもありません。逆に、データの規模が大きくなると、汎用的な能力が自然に現れ、参入障壁が生まれます。もちろん、これは知能に限った課題です。身体性知能においては、ロボット自体も問題であり、不安定性と頻繁な故障が身体性知能の発展を制限しています。2026年までにこれらの分野で大きな進歩が期待されています。 ドメインマスターモデルとその応用についても議論しましょう。私はドメインマスターモデルは誤った命題だと常々思ってきました。AIが既に存在している中で、ドメイン特化型のAIなど存在するのでしょうか?しかし、AIがまだ完全に実現されていない以上、ドメインモデルは今後も長く存在し続けるでしょう(AIの急速な発展を考えると、どれくらい存在するかは予測できません)。ドメインモデルの存在は、本質的にアプリケーション企業がAI企業に負けたくないという強い意志を反映しています。彼らはドメインノウハウという堀を築き、AIの侵入を防ぎ、AIをツールとして制御しようとしています。しかし、AIは本質的に津波のようなもので、行く手を阻むものすべてを飲み込んでしまいます。一部のドメイン企業は必然的に堀を突破し、AIの世界に引き込まれていくでしょう。つまり、ドメインデータ、プロセス、エージェントデータが徐々にマスターモデルに入っていくということです。 大規模モデルの応用もまた、原点に立ち返る必要があります。AIは新しいアプリケーションを生み出す必要はありません。AIの本質は、人間の特定の必須タスク(特定のジョブ)をシミュレート、代替、または支援することです。これはおそらく2つのタイプに分けられます。1つは既存のソフトウェアをAI対応化し、元々人間の介入を必要としていた部分を修正することです。もう1つは、人間の特定のジョブに合わせたAIソフトウェアを作成し、人間の労働を代替することです。したがって、大規模モデルの応用は人々を助け、新たな価値を生み出す必要があります。AIソフトウェアを作成しても、誰も使用せず、価値を生み出せないのであれば、そのAIソフトウェアには何の活力もありません。