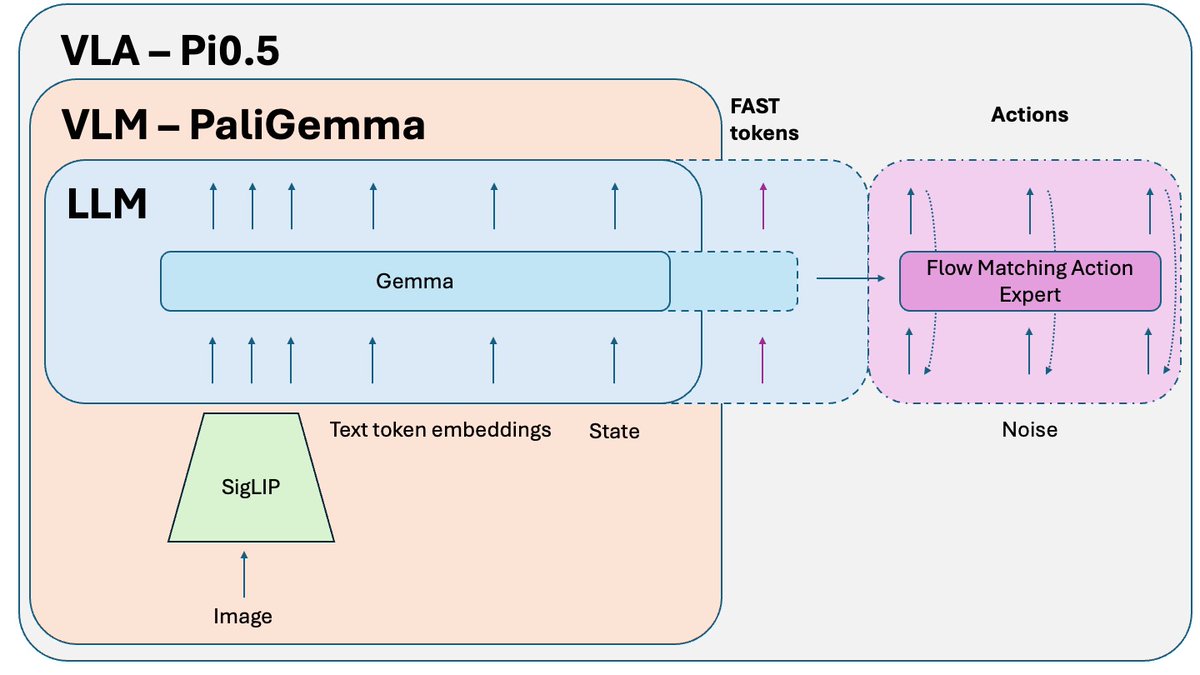
@physical_int による Pi0.5 は、現時点で最高のオープンソースのエンドツーエンドのロボット工学ポリシーの 1 つです 🤖 これはPi0のアップグレード版です。最新のPIの進歩は、この上に構築されています。その仕組みについて説明しましょう。
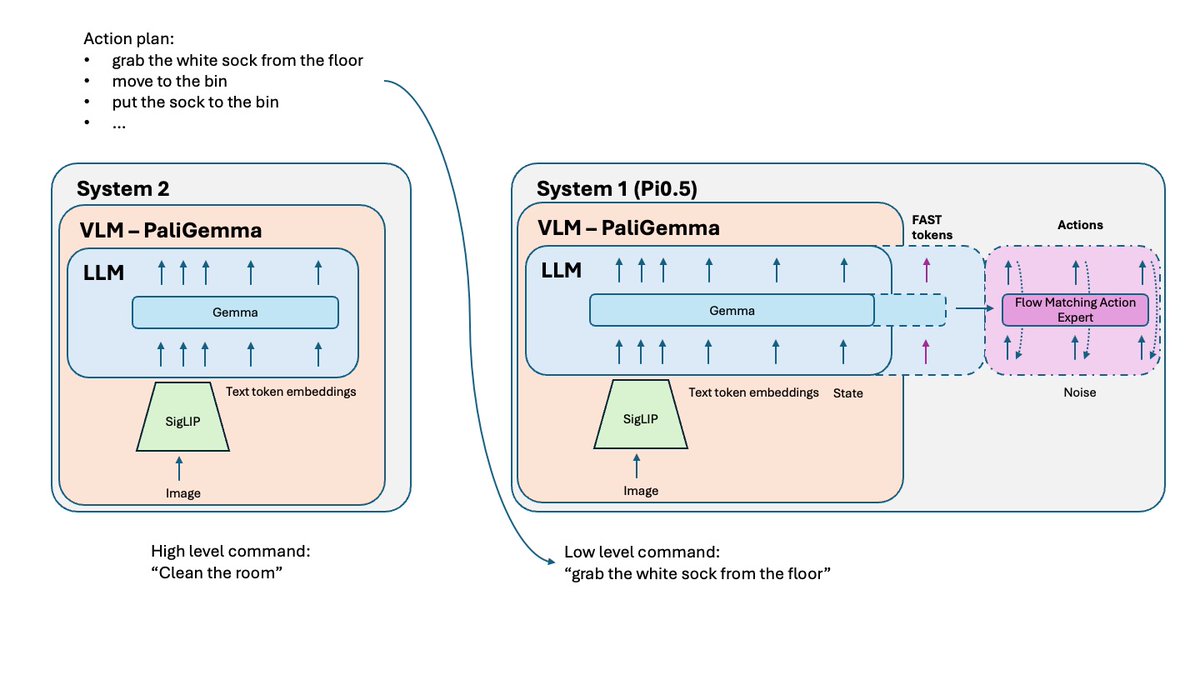
Pi0と比べて何が変わりましたか? - FASTトークン化 - Pi0ではオプションのFASTバージョンがありましたが、Pi0.5ではトレーニングの必須部分です。 - システム2 - Hi Robotの論文に従って、Pi 0.5はVLM部分を推論の高レベルシステム2として使用して、複雑なタスクを推論および計画します。 - トレーニング レシピの改善といくつかの小さな調整。
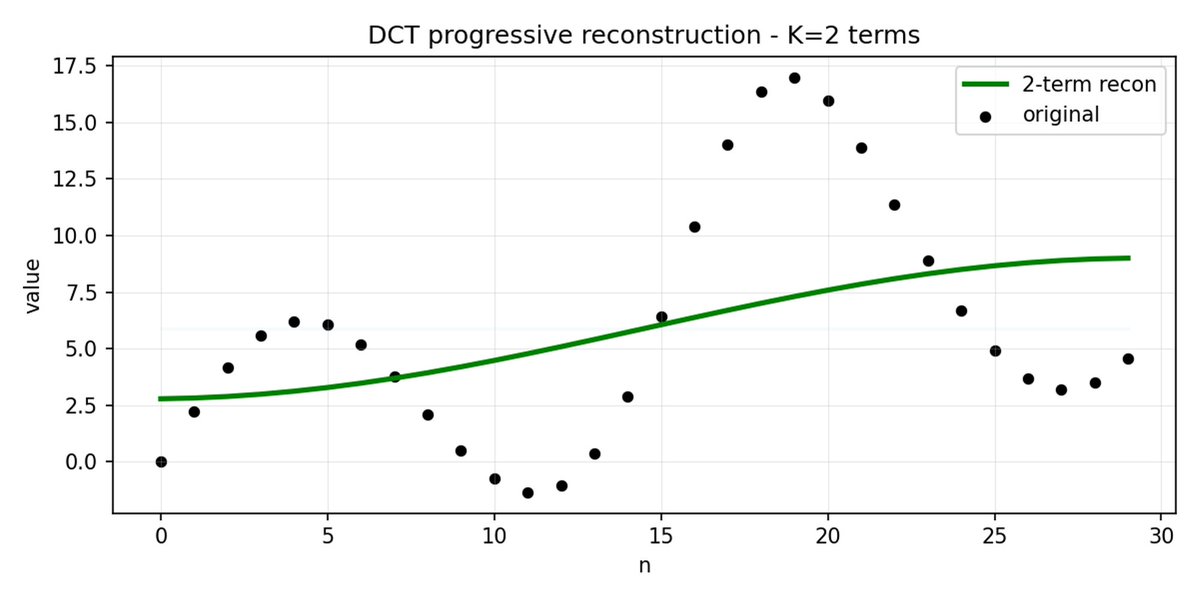
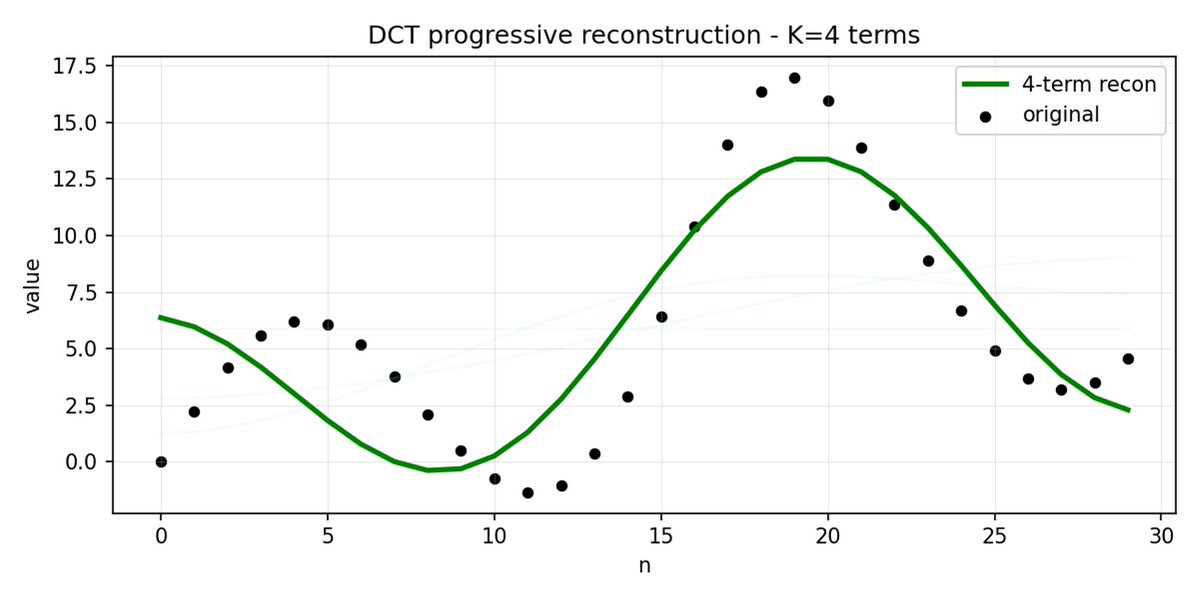
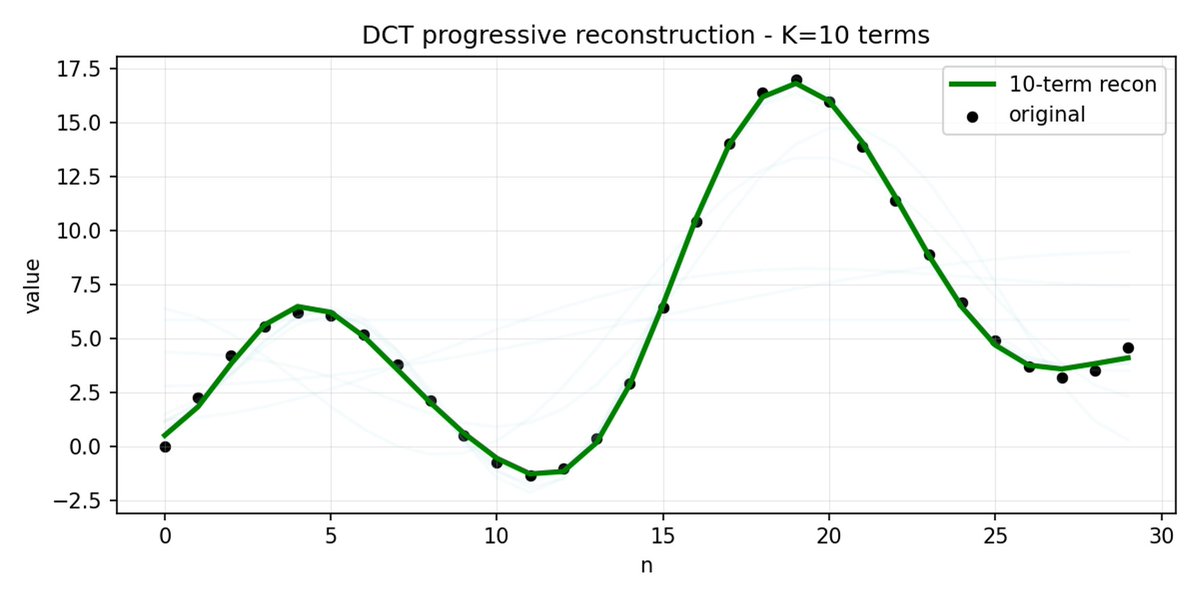
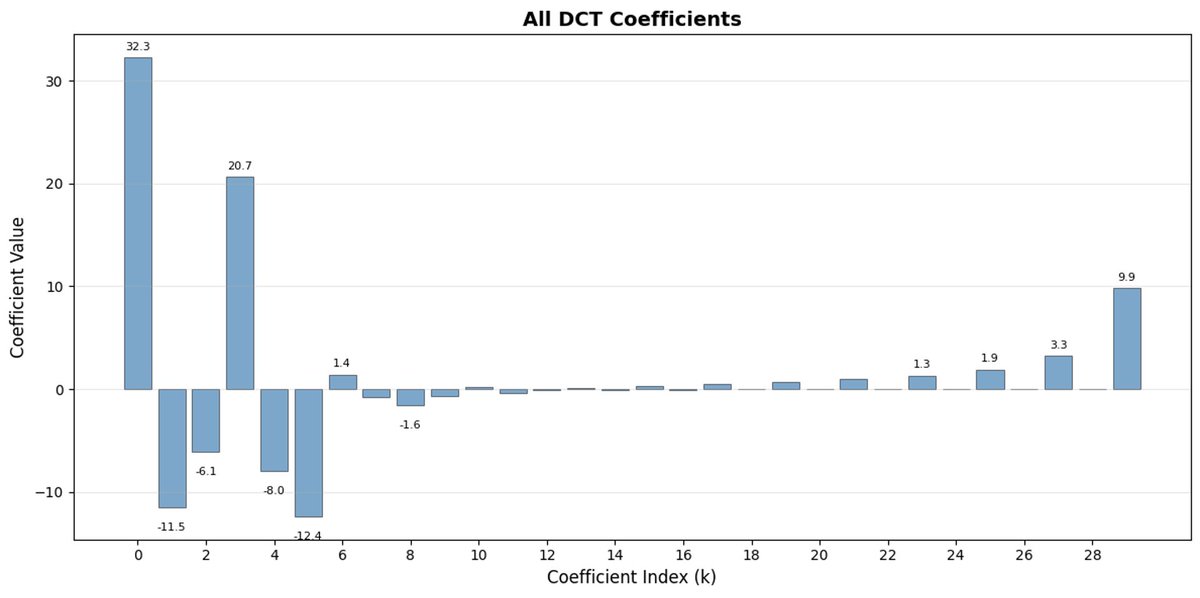
FASTは、DCT(離散コサイン変換)とBPE(バイトペアエンコーディング)を使用して、アクションシーケンスを非常に情報密度の高い離散トークンに圧縮することを可能にするトークン化アプローチです。 DCT は、JPEG で画像圧縮に使用されるアルゴリズムと同じです。 これは、異なる周波数のコサイン関数の和として信号を表します。最初の成分は信号の全体的な傾向と形状を捉え、残りの成分はより詳細な情報を捉えます。 プログレッシブ JPEG では、最初に低周波のコンポーネントが送信されるため、画像はぼやけて見えますが、コンポーネントを追加するにつれて鮮明になります。



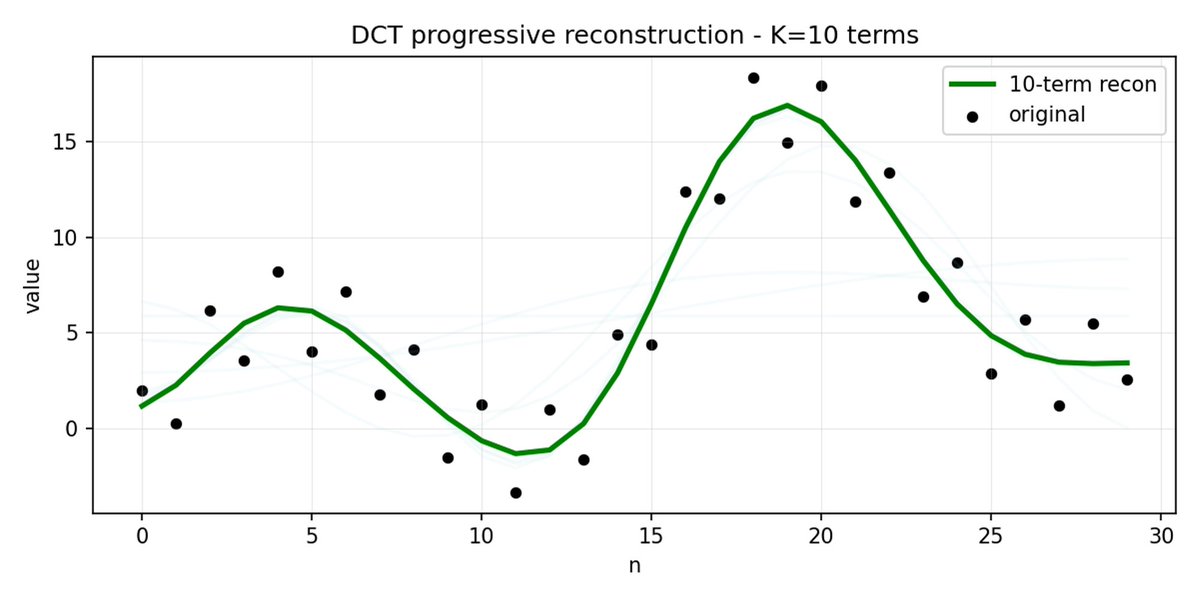
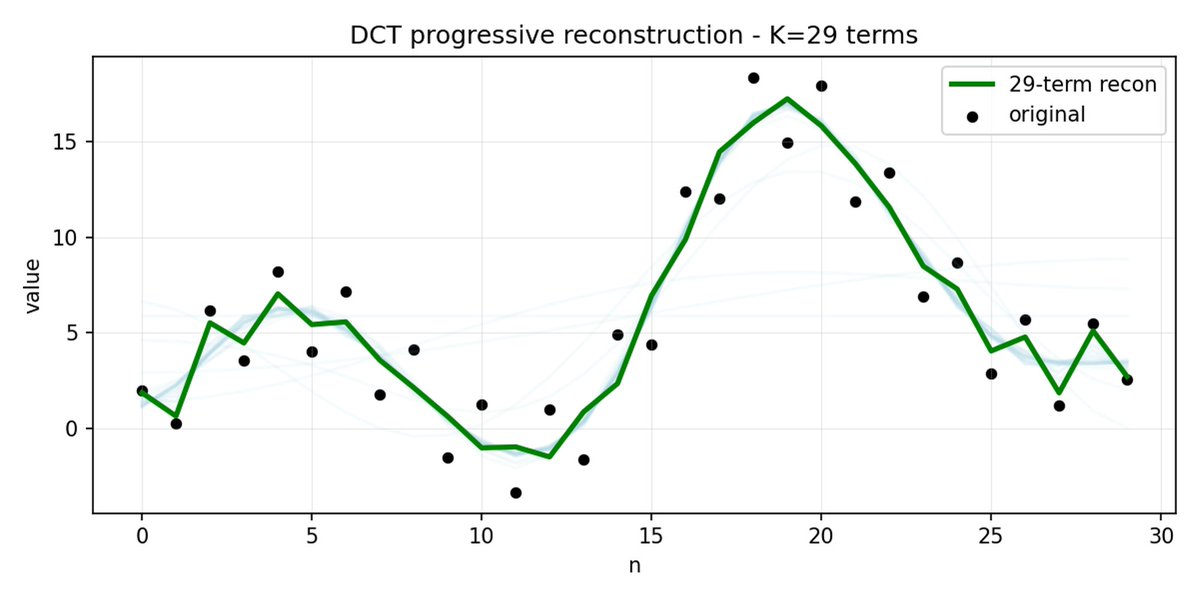
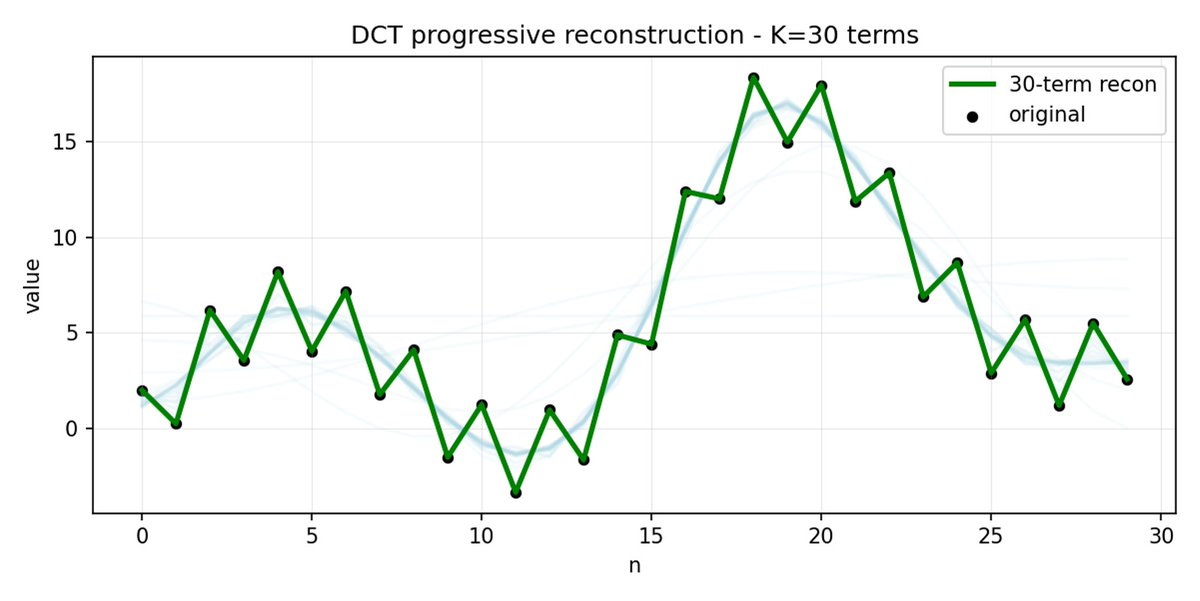
FAST はアクション チャンクに対しても同じことを行います。 30 個の相関アクション値を予測する代わりに、より短く意味のある表現を予測します。 多くの場合、いくつかの主要な係数(元の信号のエネルギーの大部分を含む)のみを保持しても、軌道をかなり適切に再構築できます。
バイト ペア エンコーディング (BPE) は、LLM で使用される最も一般的なトークン化アプローチです。 最も一般的なトークンのペアを探し、それらを単一のトークンに結合します。 これを量子化された DCT に適用すると、高周波成分の多くの 0 係数と、さまざまな関節の共通の組み合わせ動作が単一のトークンにマージされ、強力な圧縮が実現します。
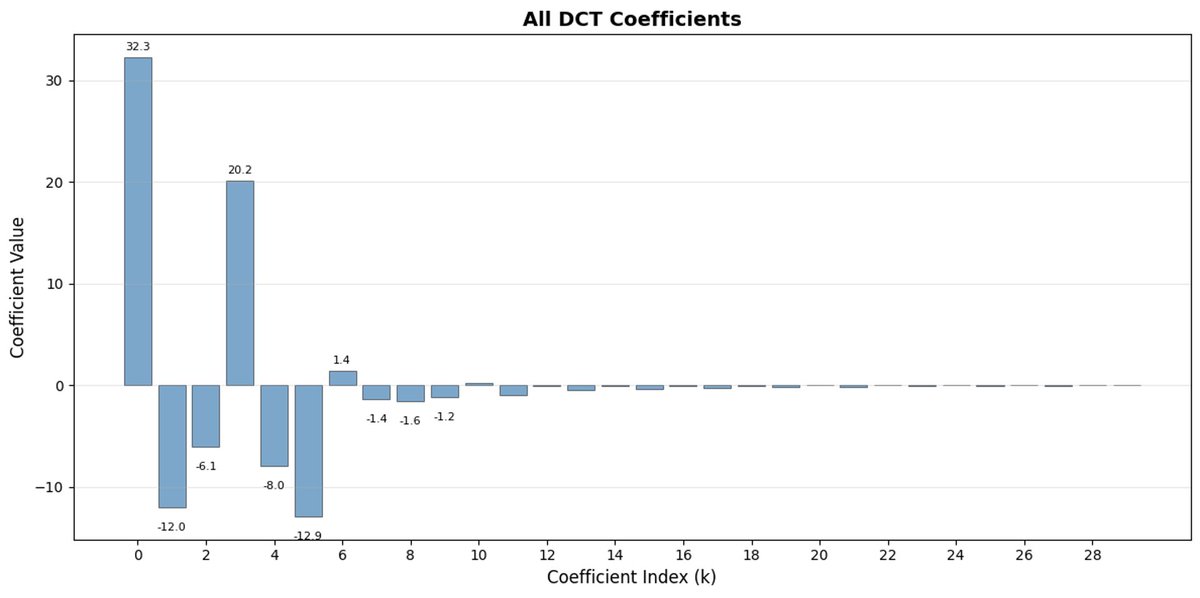
アクションに高周波ノイズ (タイムステップごとの正規化アーティファクトなど) があり、係数がゼロに近づかなくなり、圧縮率が低下する場合、FAST では圧縮率が低下する可能性があります。 実際のロボットデータは通常は滑らかなので、ほとんどの場合は問題ありません。ただし、データの前処理には注意してください。
単純なタスクについてトレーニングされた VLA ポリシーは、それらを複雑で長期的な問題に組み合わせるのに苦労する可能性があります。 これを解くには、より高次のシステム2が使用されます。Pi0.5はシステム1(VLA)で使用されるのと同じVLMを使用しますが、問題を推論し次のステップを定義するために、はるかに低い頻度で呼び出されます。そして、そのステップはシステム1に送信され、実行されます。
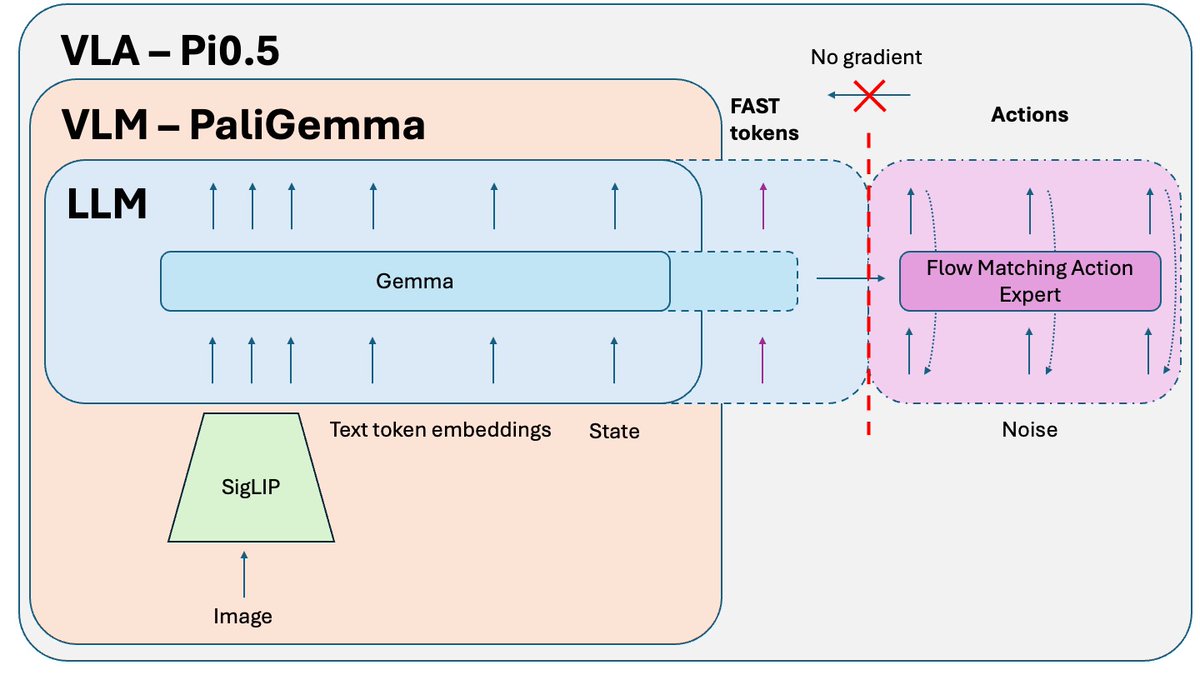
Pi0.5 論文の後に公開され、オープンソース バージョンのモデルのトレーニングに使用される追加のトリックが Knowledge Insulation です。 VLM部分(インターネット規模のデータで事前学習済み)とアクションエキスパート(ランダムに初期化)を共同学習すると、アクションエキスパートからのノイズの多い勾配によってVLMの事前学習が損なわれ、事前学習済みの知識を忘れ始めます。 修正方法は、アクション エキスパートから勾配を分離し、それがアクション エキスパートの重みにのみ影響を与えるようにすることです。その一方で、VLM は FAST アクション トークン + 関連する非アクション データでトレーニングされます。
推論中のもう 1 つの問題は、チャンク化による非スムーズな動きです。 モデルは次のチャンクを予測し、それを実行し、次のチャンクを予測するために一時停止します (下のビデオ、速度 3 倍)。 前のチャンクが実行される前にチャンクを予測しようとすると、モデルがまったく異なるアクション モードを実行している間に新しいアクション モードにジャンプすると、致命的なエラーが発生する可能性があります。 解決策は、画像生成でよく使われるインペインティングです。古いチャンクの実行中に次のチャンクを予測できますが、新しい予測が前のチャンクの末尾と完全に一致するように強制します。 その結果、ジャンプや一時停止のないよりスムーズな動作と、モデルのパフォーマンスとスループットが向上します。
完全な詳細(ビジュアル + デモ + 微調整手順付き)を知りたい場合は、私の新しいビデオをご覧ください: https://t.co/TDdhedJiDn