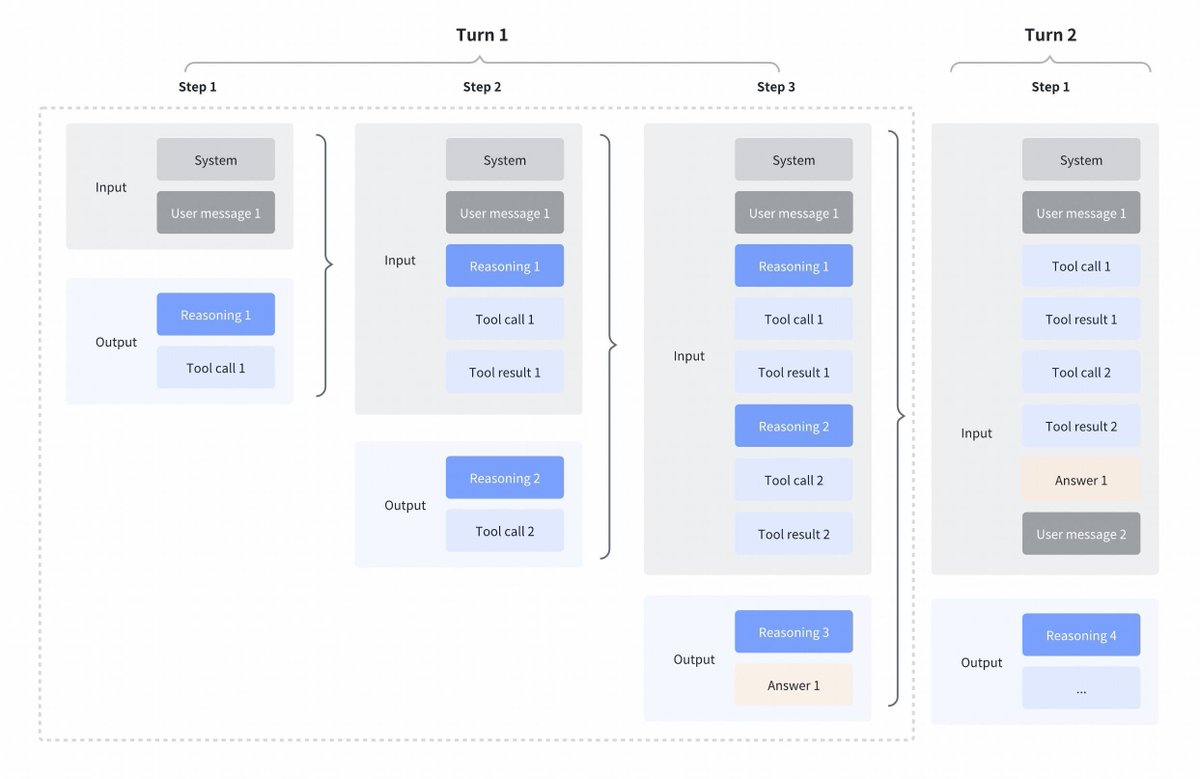
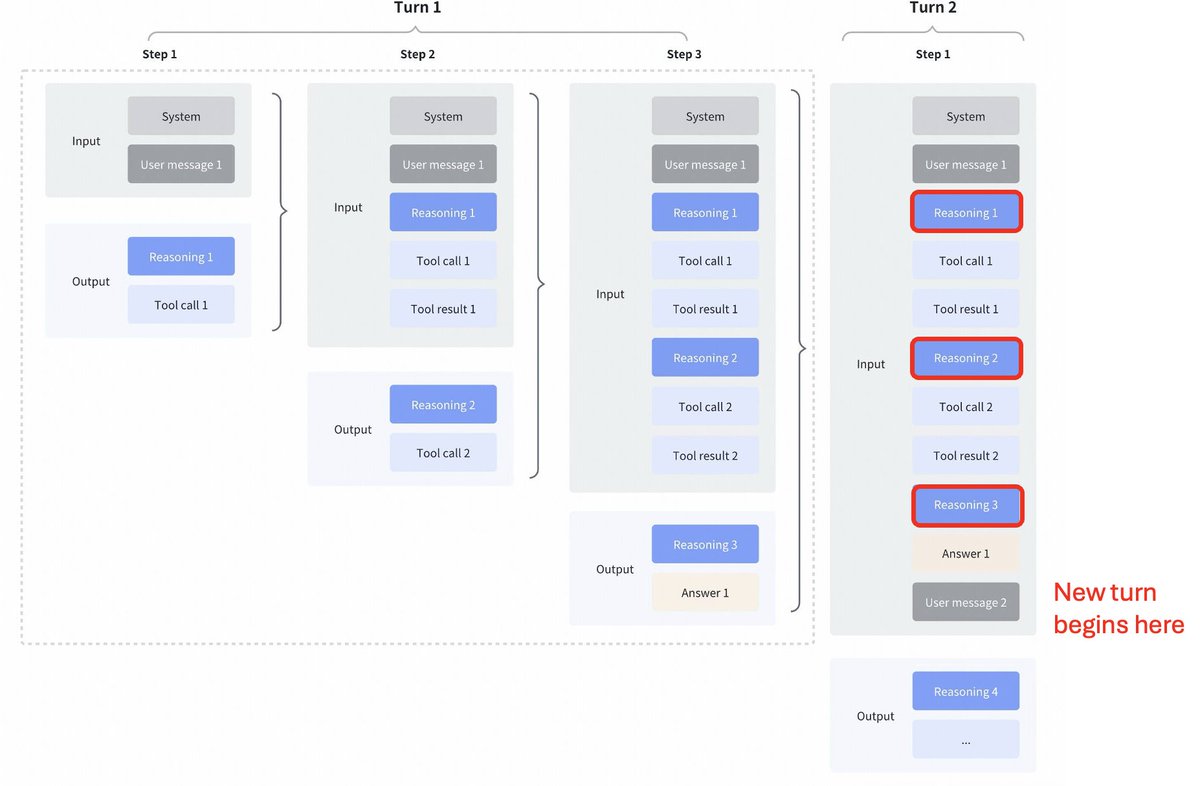
GLM4.7による興味深い戦略の変更 Kimi K2 Thinking、DeepSeek V3.2、MiniMax M2.1と比較 ツール呼び出し間のインターリーブ思考: これらすべてのモデルは、ツール呼び出しのインターリーブ思考をサポートしていましたが、下の最初のスクリーンショットに見られるように、前のターンからの思考をクリアしています。 GLM 4.7 で保存された思考: それと比較すると、GLM 4.7(エンドポイントのみのコーディング)では、下のスクリーンショットでわかるように、前のターンからの推論が保持されます(赤いブロックに注意)。 他の API エンドポイントの場合、動作は以前と同じです (前のターンの推論を破棄します)。 モデルに過去のコンテキストが含まれるようになるため、パフォーマンスが確実に向上します。 @peakji さんがアドバイスされているように、モデルは過去の思考プロセスに基づいて適切な判断を下す必要があります。これはコンテキスト圧縮とは相反するものです。しかし、コーディングのシナリオでは十分に価値があると思います。 設定可能にして、影響を自分で確認できるようにしてほしいです。